本文主要是介绍2024.4.29 Pandas day01 基础语法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

pandas是python的一个数据库,在使用数据库的时候需要输入 import pandas as pd 引入,
df = pd.read.csv(''文件路径“):这是利用pandas数据库读取CSV文件的方法,如果读取EXCEL文件或者其他文件,csv文件换成其他文件的格式。
df.dtypes:如果在文件中有字符型数据返回object
df.head(n):表示将前n行数据显示出来,默认是显示前五行
df.tail(n):表示将后n行数据显示出来,默认后五行
最后打印即可
关于dytype
pd.read_csv('Nowcoder.csv')会尝试自动推断每列的数据类型,而pd.read_csv('Nowcoder.csv', dtype=object)会将所有列的数据类型设置为object。如果不指定数据类型(即第一个例子),pandas会尝试推断每个列的数据类型,这可能会导致一些列被错误地解释为不同的类型,从而可能导致错误。指定
dtype=object可以确保所有列都被解释为Python对象(即字符串),这对于某些情况可能是有用的。另一方面,指定正确的数据类型可以提高性能和减少内存使用,因为pandas可以更好地利用数据类型的信息进行优化。 因此,如果您已经知道每列的正确数据类型,则最好指定它们。
在 pandas 中,数据类型
object表示一个通用的 Python 对象,可以存储任何 Python 对象类型,包括字符串、整数、浮点数、列表、字典、自定义类等。将数据类型设置为object表示将每个数据点解释为 Python 对象,而不是尝试自动推断数据类型。这种设置在某些情况下可能很有用,比如:
- 数据集中的某些列包含混合类型的数据(如字符串和数字),而不是单一的数据类型。
- 某些列的数据类型无法被 pandas 正确地推断。
- 想要在使用数据时动态地处理数据类型的情况。
但是,由于
object类型是一个通用的 Python 对象,其存储和处理速度通常比其他数据类型要慢,并且占用更多的内存空间,因此只有在确实需要时才应将数据类型设置为object。
- loc : Selection by Label ,按标签取数据,
loc[行索引,列名/column]
(如果第二个参数的个数是全部即 : ,可以省略不写)。
例:
print(df.loc[1,'name']) # 索引1(行),名为‘name’的列
- iloc : Selection by Position,即按位置选择. 只接受整型参数。
不接受列字段名称作为参数,只支持列字段的位置索引作为参数。
iloc[行索引,列索引](没有逗号及以后就是默认列为所有列)
- isnull: 判断是否为空。
返回bool类型的值:True or False
- any:返回是否至少一个元素为真
all:返回是否所有元素为真
axis=1或0: 1表示横轴,方向从左到右;0表示纵轴,方向从上到下
import pandas as pd
df = pd.read_csv("Nowcoder.csv", sep=",", dtype=object)
print(df[df["Language"] == "Python"])
"""
df['Language'] == 'Python' 创建一个布尔型 Series,该 Series 的长度与 df 的长度相同,
并且对应于每行数据,如果该行中 'Language' 列的值为 'Python',则该行对应的 Series 元素为
True,否则为 False。最后,使用布尔型 Series 作为索引,将 DataFrame 中所有 'Language' 列为 'Python' 的行提取出来,
并将其打印输出。这里的 df[df['Language']=='Python'] 表示只选择 DataFrame 中 'Language'
列的值为 'Python' 的行。
"""
import pandas as pd
nk = pd.read_csv('Nowcoder.csv',sep=',')
col = [0,1,2,5]
print(nk.iloc[-5:-1,col])
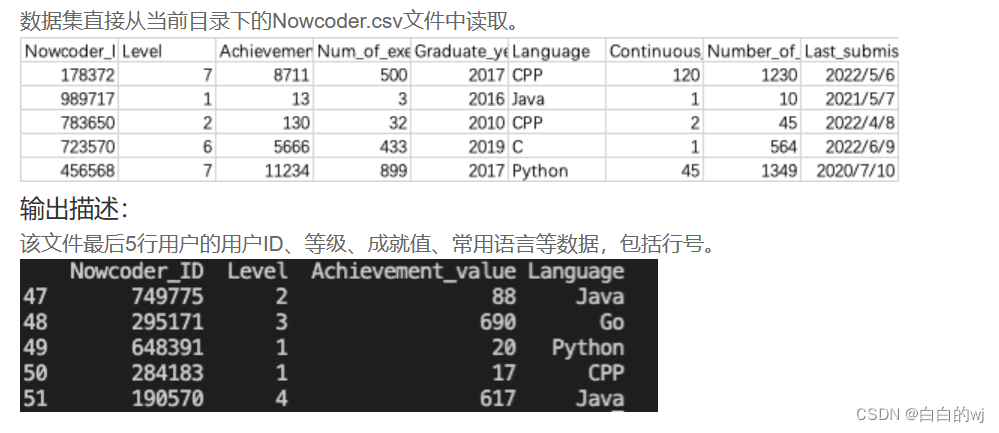
pd.set_option("display.max_columns", None) # 显示所有的列,而不是以……显示
pd.set_option("display.max_rows", None) # 显示所有的行,而不是以……显示
pd.set_option("display.width", None) # 不自动换行显示
这是使用 `pd.set_option()` 函数设置 Pandas 显示选项的例子。让我解释一下这些选项的含义:
- `pd.set_option('display.width', 300)`: 设置显示一行的最大字符宽度为300。这意味着当你输出一行的内容时,如果内容的字符宽度超过了300,Pandas会尝试自动换行,以使输出更容易阅读,None就可以不换行。
- `pd.set_option('display.max_rows', None)`: 设置显示的最大行数为无限。当你输出 DataFrame 或 Series 时,所有行都会被显示,而不是被截断。这可以帮助你查看整个数据集。
- `pd.set_option('display.max_columns', None)`: 设置显示的最大列数为无限。当你输出 DataFrame 时,所有列都会被显示,而不是被截断。这对于查看包含大量列的 DataFrame 是有用的。
这些选项的设置可以根据你的需要进行调整。在实际使用中,你可以根据数据的大小和显示需求来设置这些选项。例如,如果你的数据集很大,可能需要限制显示的行数和列数,以避免输出过于庞大。
同时多个条件筛选
cond1 = Nowcoder['Language'] =='CPP'
cond2 = Nowcoder['Level'] ==7
cond3 = Nowcoder['Graduate_year'] !=2018
cond = cond1 & cond2 & cond3
print(Nowcoder[cond])或者使用查询
print(nk.query('Language=="CPP"&Level>=7 &Graduate_year!=2018'))
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
# 完整版函数
# value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
# 参数:
# 1.normalize : boolean, default False 默认false,如为true,则以百分比的形式显示
# 2.sort : boolean, default True 默认为true,会对结果进行排序
# 3.ascending : boolean, default False 默认降序排序
# 4.bins : integer, 格式(bins=1),意义不是执行计算,而是把它们分成半开放的数据集合,只适用于数字数据
# 5.dropna : boolean, default True 默认删除na值
print(Nowcoder['Language'].value_counts())
这篇关于2024.4.29 Pandas day01 基础语法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





