本文主要是介绍wechat_OCR项目说明文档,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
2024年五一期间,我写了一个项目,项目文档如下。
本项目Github地址:https://github.com/Knighthood2001/wechat_OCR
传送门
公众号文章
前言
项目功能
- 通过截图软件进行截图后,通过按下
Ctrl+C后,实现了图片提取文字,并将文字复制到剪切板中,大家通过Ctrl+V即可粘贴。
项目优势
- 实现了图片提取文字,并且依托微信OCR,其识别精度还是挺高的;
- 无需登录微信,即可实现微信OCR;
- 操作简单,项目集成了使用微信OCR进行提取文字进行粘贴的一些步骤,使得你只需要通过
Ctrl+C和V键,即可快捷实现复制图片中的文字。 - 可以通过更改项目中的
mode参数,实现文字分行复制还是同行复制。
项目展示
最简单的图片提取文字
初始项目架构
下载项目打开后,项目架构如下:
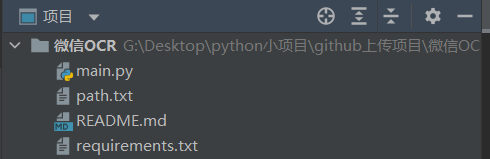
其中
mian.py是项目代码。
path.txt是配置微信OCR所需要的路径存放处。
README.md是项目说明文档。
requirements.txt是项目所需的包及版本。
README_picture存放的是README.md项目说明文档所需要的图片。
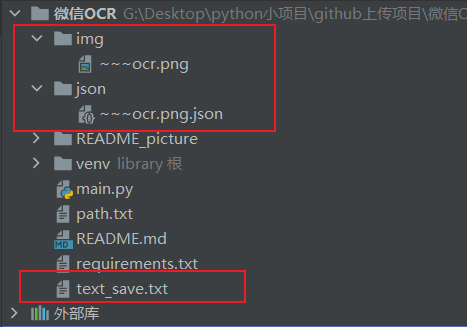
运行后的项目架构
项目成功运行后,会生成img文件夹,里面存放的是剪切板中存放的图片,json文件夹中存放的是剪切板图片经过微信OCR识别后保存的json文件。
并且会生成一个text_save.txt文件,里面的内容就是图片提取的文字。如下图所示:
配置环境
要想运行本项目,首先你得先配置项目环境。
创建虚拟环境
首先打开终端,输入以下命令,创建虚拟环境
python -m venv venv
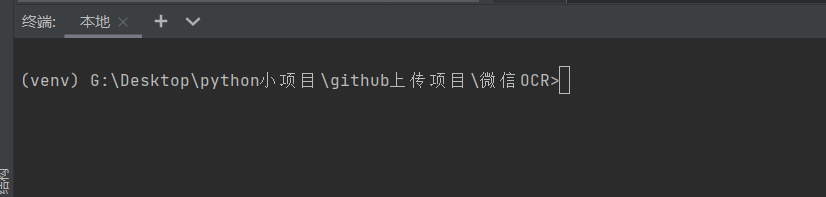
然后进入到这个虚拟环境,并将其激活
venv\scripts\activate
注意这里是反斜杠。
此时可以看到,命令前面有个(venv),说明已经进入了这个虚拟环境了。
安装项目包
如果你的pip版本不够,可以升级一下。命令如下
python -m pip install --upgrade pip
然后使用下面的命令,安装requirements.txt中的包
pip install -r requirements.txt
配置python解释器
这时候需要配置一下python解释器。当然这一步你可以选择在创建完虚拟环境后就进行这一步操作。
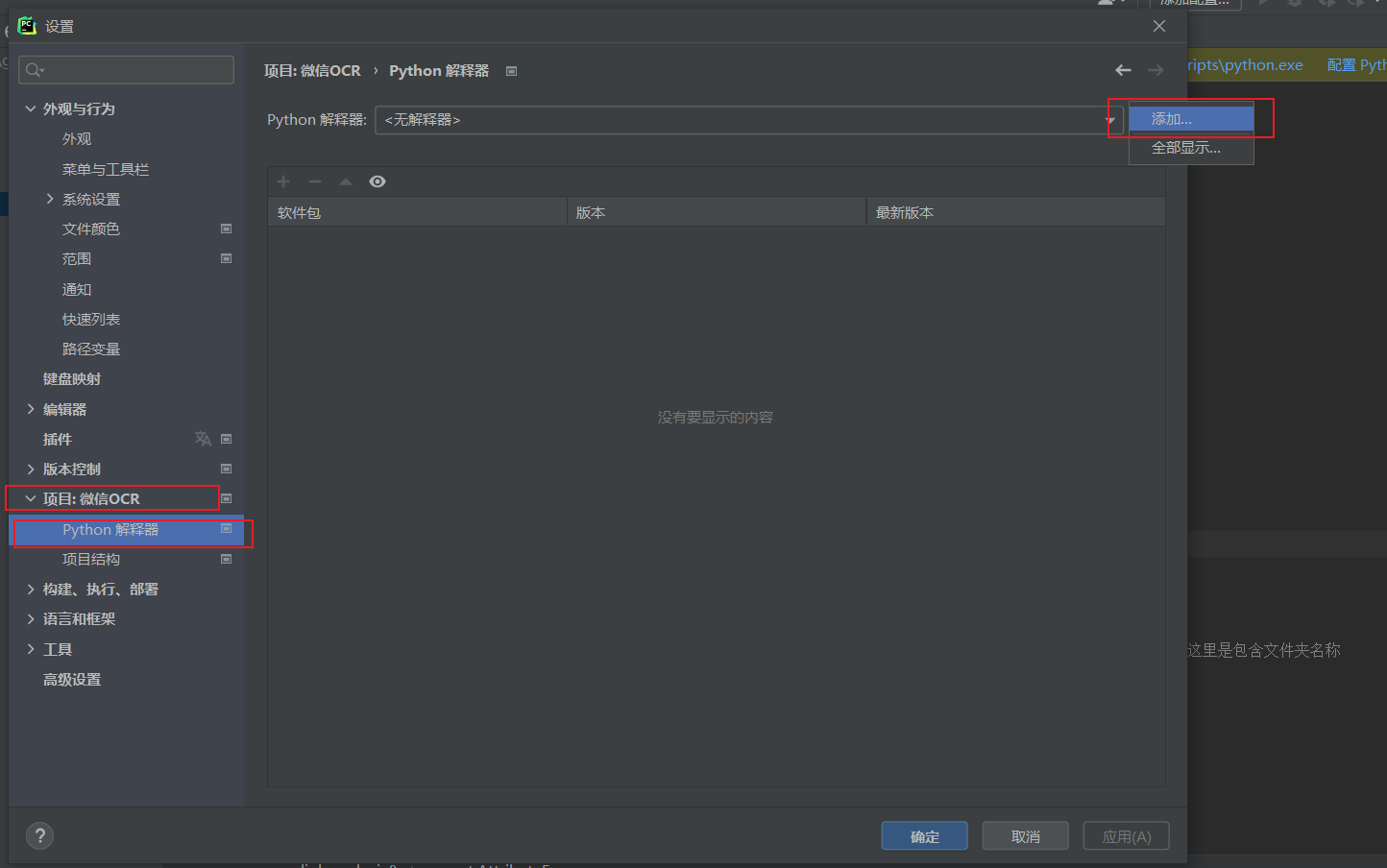
点击现有环境,一般来说,它会自动帮你选择你刚刚配置好的venv中的python.exe解释器,如果没有的话,自己选择一下。
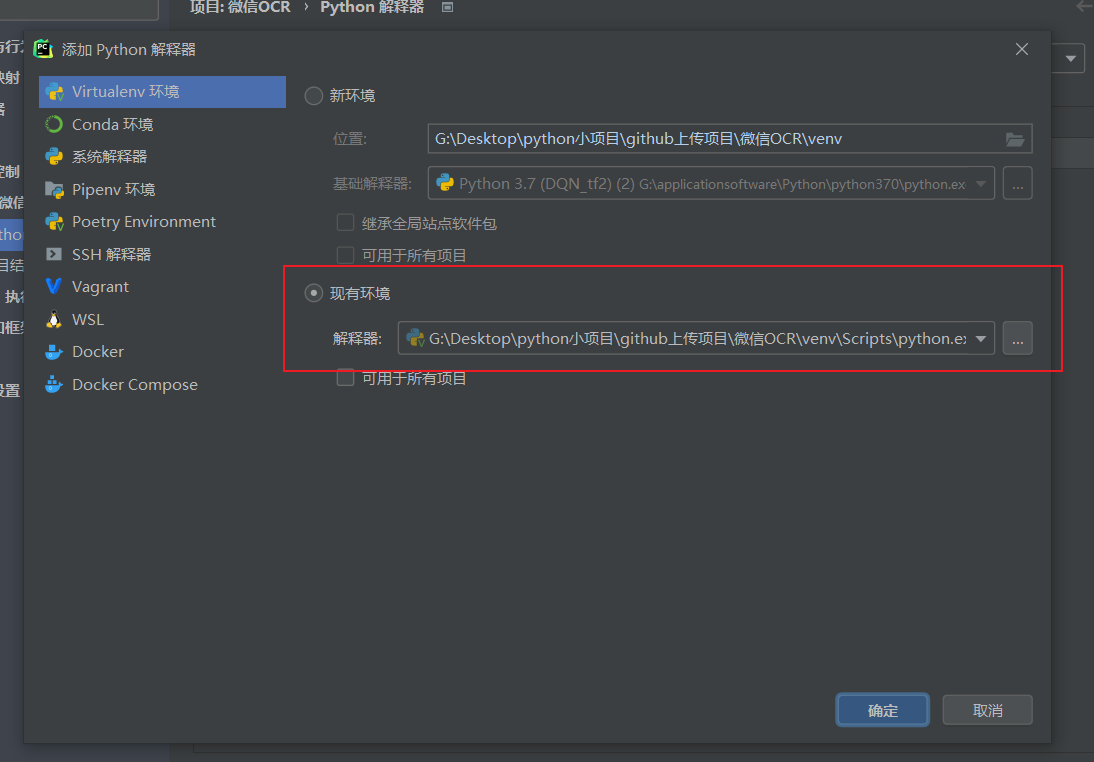
点击确定
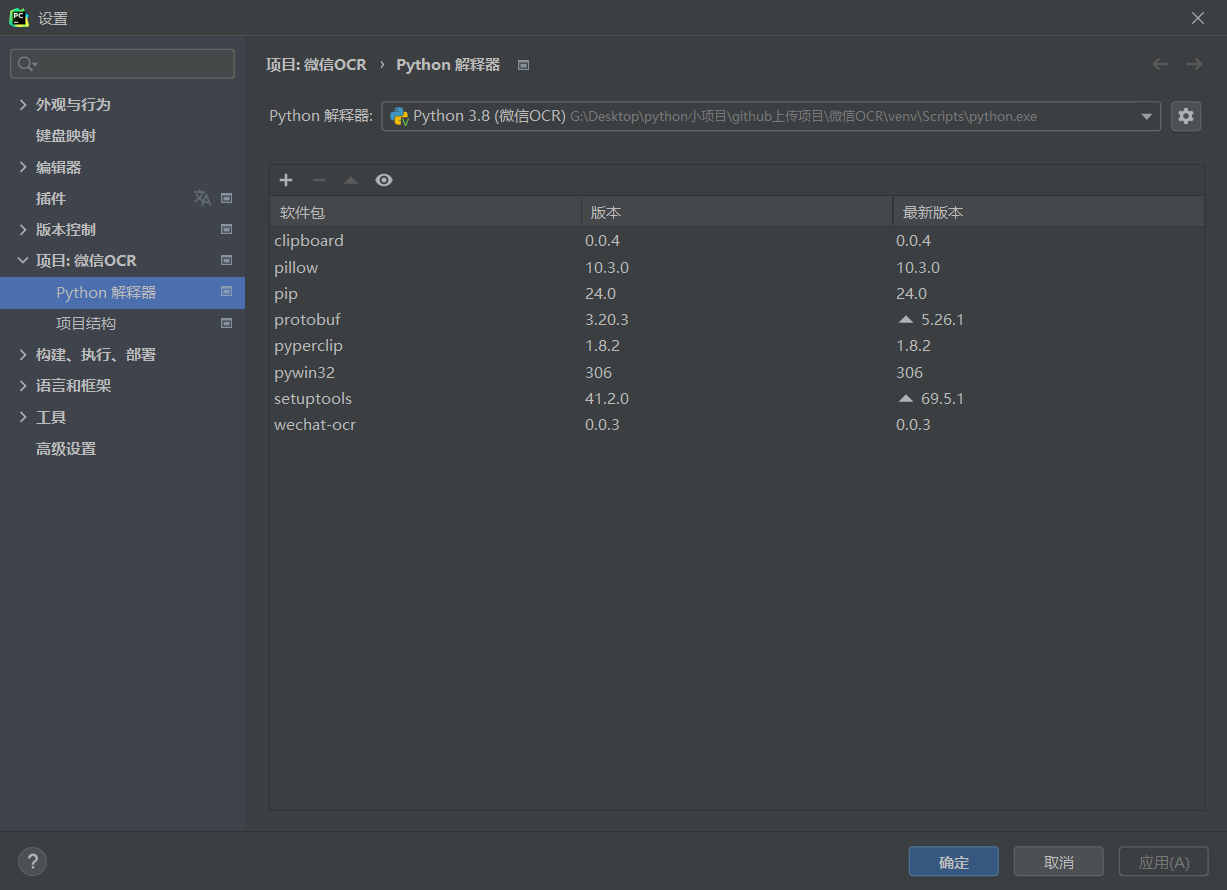
可以看到,虚拟环境中已经安装了你需要的包了。
以上操作完成后,你项目基础配置就完成了。
配置微信OCR和mmmojo.dll路径
找到项目中的path.txt文件,里面存放的是你WeChatOCR.exe和mmmojo.dll的路径

C:\Users\Lenovo\AppData\Roaming\Tencent\WeChat\XPlugin\Plugins\WeChatOCR\7079\extracted\WeChatOCR.exe
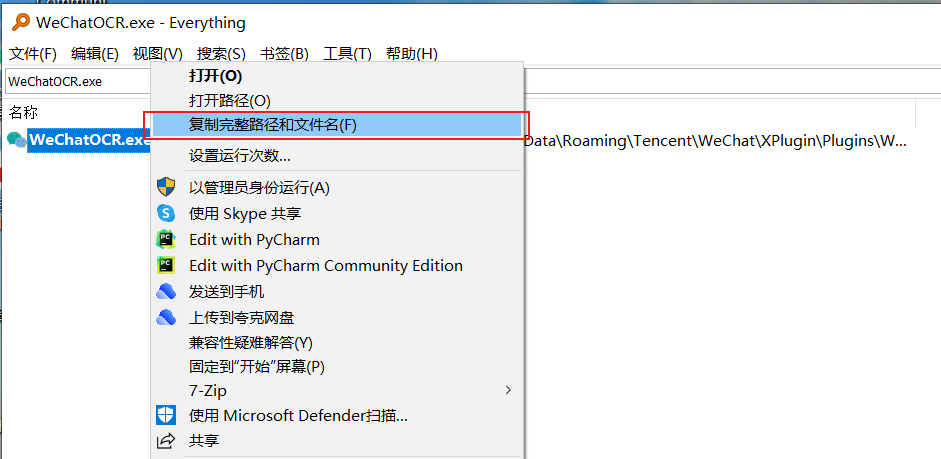
你可以使用everything软件进行查找,并复制完整路径及文件名。
G:\applicationsoftware\WeChat[3.9.10.19]
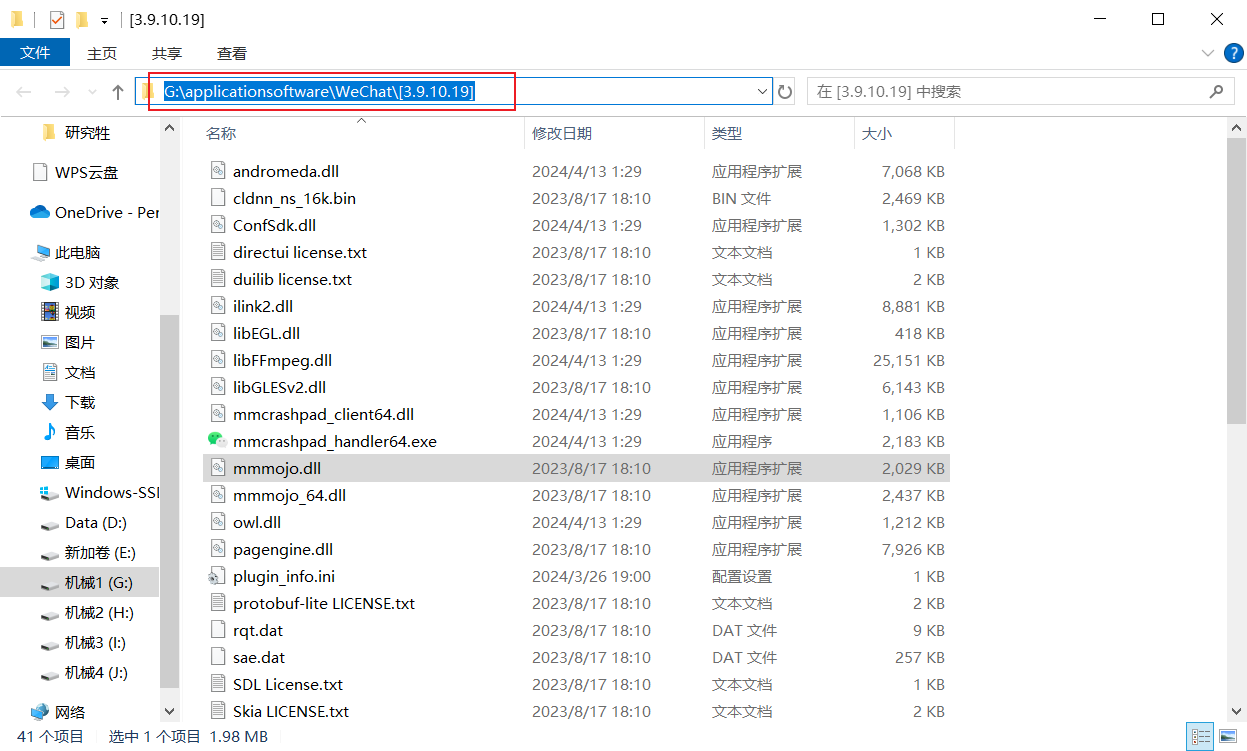
同理,你可以复制mmmojo.dll所在的路径。
这里需要注意的是:WeChatOCR.exe的路径需要到最终文件名,mmmojo.dll的路径只需要到上一级目录即可。
然后将这两个路径,依次分行复制到path.txt中,保存。
以上这一步操作需要好好配置,否则后续就无法运行。
运行代码
接下来就可以运行代码了
实现同行的复制
在main.py中的第135行中,你可以将mode改成2,这样就能将识别结果的文字放在同一行,适用与同一段落的图片的截图并提取文字。
# TODO 你可以将mode改成2,实现文字放在同一行。
save_text(json_file, save_file, mode=2)
最后
经过以上的讲解,我觉得大家对于这个项目的配置已经运行应该是没有问题了。
如有问题,欢迎+v:TheOnewbd和我交流。
希望大家可以多多关注一下我的公众号,对这个项目的免费讲解,我会更新在微信公众号中,绝对不会让你失望。

这篇关于wechat_OCR项目说明文档的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




