本文主要是介绍Aggregation总结:Blending和Bootstrap,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Aggregation
首先举一个买房的例子,假如你有10个朋友给出了买房的意见,你如何参考这10个人的意见做出决定呢?
- 第一种办法是让大家投票,每人一票,最后选择得票数最多的那个选项
- 第二种办法也是投票,与第一种不同的是每个人手里的票数不一样,懂行的人可能会分配更多的票数
- 第三种办法是根据具体条件进行判断:这10个人中,有的人可能注重房源的地理位置,有的人可能更注重交通状况。根据不同的条件参考不同人的意见。
Aggregation的目的就是要融合多个hypothesis,从而达到更好的预测效果。
以上三种投票方式分别对应了机器学习中的三种Aggregation类型,即Uniform Blending、Linear Blending和Any Blending
2. Uniform Blending
分类与回归模型的Uniform Blending
对于多分类模型,Uniform Blending可将得票数最多的那一类作为最终的分类结果,其中 gt(x) 表示我们现有的模型, G(x) 表示混合后的模型:
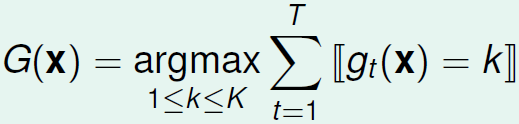
对于回归模型,Uniform Blending将每一个 gt(x) 求平均:
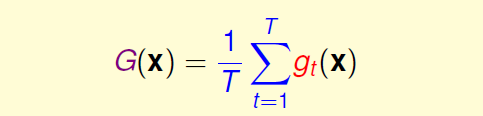
Uniform Blending的可行性:
f(x) 表示实际的预测结果, gt(x) 和 f(x) 的平方误差与 G(x) 的联系可通过如下推导得出:

(G−f)2 这项表示混合后的模型与真实结果的误差,即Bias; avg((gt−G)2) 表示 gt 之间的相异性,即Variance。从推导结果可以看出 gt(x) 与 G(x) 在预测误差上相差了 avg((gt−G)2) 这一项,即 G(x) 的误差期望小于或等于任选一个 gt(x) 的误差期望。
3. Linear Blending和Any Blending
Linear Blending
对于回归问题,Linear Blending 就是将 gt(x) 的结果进行线性组合,使混合后的结果趋近目标值。
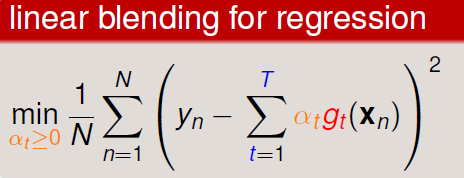
在对 α 进行训练时需采用验证集,并且通常情况会去掉 α≥0 这个约束。这时候 α<0 表示将模型起了反作用,所以将结果反着用。
Any Blending
注意overfitting问题

4. Bootstrap (Bagging)
首先回顾一下如何获得不同的 g(x) ,有如下4种方法:

第一种是从不同的模型得到不同的 gt ,第二种是同一种模型设置不同的参数,第三种是设置不同的起始点,第四种是用不同的训练数据。
bootstrapping 的思想就是利用现有的训练数据模拟出不同的数据集,从而训练出不同的 gt 。具体做法是在训练集中进行re-sample,即经过多次有放回采样获得多个数据集。
这篇关于Aggregation总结:Blending和Bootstrap的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






