本文主要是介绍MemSQL Start[c]UP 2.0 - Round 2 - Online Round 题解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题解:
Piegirl got bored with binary, decimal and other integer based counting systems. Recently she discovered some interesting properties about number 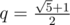 , in particular that q2 = q + 1, and she thinks it would make a good base for her new unique system. She called it "golden system". In golden system the number is a non-empty string containing 0's and 1's as digits. The decimal value of expression a0a1...an equals to
, in particular that q2 = q + 1, and she thinks it would make a good base for her new unique system. She called it "golden system". In golden system the number is a non-empty string containing 0's and 1's as digits. The decimal value of expression a0a1...an equals to 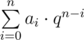 .
.
Soon Piegirl found out that this system doesn't have same properties that integer base systems do and some operations can not be performed on it. She wasn't able to come up with a fast way of comparing two numbers. She is asking for your help.
Given two numbers written in golden system notation, determine which of them has larger decimal value.
Input consists of two lines — one for each number. Each line contains non-empty string consisting of '0' and '1' characters. The length of each string does not exceed 100000.
Print ">" if the first number is larger, "<" if it is smaller and "=" if they are equal.
1000 111
<
00100 11
=
110 101
>
解题思路;
这题的关键就是这个公式q2 = q + 1。通过这个式子,我们可以发现,对于q进制数,相邻的两个低位如果都是1,就可以向高位进1,如011 = 100。我们先读入两个数组,取一个值n为二者长度的最大值+1(为方便处理11000种情况),不足n位的,在高位用0补齐,然后就来处理数组了,从高位往低位扫一遍,将可以进位的地方进位。最后直接比较两个字符串的大小即可。
代码:
#include <cstdio>
#include <cmath>
#include <cstring>
#include <algorithm>
using namespace std;const int MAXN = 1e5 + 10;
char sa[MAXN], sb[MAXN];char *fun(char s[])
{int n = strlen(s);for(int i = 0; i < n-1; ++i){int x = i;while(x>=0 && (s[x]-'0') && (s[x+1]-'0')){s[x]--, s[x+1]--, s[x-1]++, x-=2;}}return s;
}int main()
{scanf("%s", sa);scanf("%s", sb);int na = strlen(sa);int nb = strlen(sb);int n = max(na, nb) + 1;for(int i = na; i >= 0; --i)sa[i+n-na] = sa[i];for(int i = 0; i < n-na; ++i)sa[i] = '0';for(int i = nb; i >= 0; --i)sb[i+n-nb] = sb[i];for(int i = 0; i < n-nb; ++i)sb[i] = '0';strcpy(sa, fun(sa));strcpy(sb, fun(sb));//puts(sa), puts(sb);int cmp = strcmp(sa, sb);switch(cmp){case -1:{printf("<\n");break;}case 0:{printf("=\n");break;}case 1:{printf(">\n");break;}}return 0;
}
Piegirl was asked to implement two table join operation for distributed database system, minimizing the network traffic.
Suppose she wants to join two tables, A and B. Each of them has certain number of rows which are distributed on different number of partitions. Table A is distributed on the first cluster consisting of mpartitions. Partition with index i has ai rows from A. Similarly, second cluster containing table B has npartitions, i-th one having bi rows from B.
In one network operation she can copy one row from any partition to any other partition. At the end, for each row from A and each row from B there should be a partition that has both rows. Determine the minimal number of network operations to achieve this.
First line contains two integer numbers, m and n (1 ≤ m, n ≤ 105). Second line contains description of the first cluster with m space separated integers, ai (1 ≤ ai ≤ 109). Similarly, third line describes second cluster with n space separated integers, bi (1 ≤ bi ≤ 109).
Print one integer — minimal number of copy operations.
2 2 2 6 3 100
11
2 3 10 10 1 1 1
6
大致题意:
A有m个分支,每个分支有ai组,B有n个分支,每个分支有bi组,要将A与B合并(A的每个分支都包含B的全部,或B的每个分支都包含A的全部),使得总花费最小。
解题思路:
贪心。策略:将a数组升序排列,b数组升序排列,求出a的和ma,b的和mb。一共就两种情况,要么将A合并到B,要要么将B合并到A,取两者的小值即可。如果是将B合并到A中,我们就将a数组遍历一下,a[i]>=mb就保留a[i],将mb合并到a[i]中,花费为mb,否则,将a[i]合并到A的其他组中,花费为a[i],注意一点如果是a的最后一项必须保留,哪怕是比mb小,也要保留下来,将mb合并进来,因为是将B合并到A,A中应该至少保留一项。
代码:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;typedef long long lint;
const int MAXN = 1e5 + 10;
int n, m, a[MAXN], b[MAXN];int main()
{scanf("%d%d", &m, &n);lint ma = 0, mb = 0, ansa = 0, ansb = 0;for(int i = 0; i < m; ++i){scanf("%d", &a[i]);ma += a[i];}for(int i = 0; i < n; ++i){scanf("%d", &b[i]);mb += b[i];}sort(a, a+m);sort(b, b+n);for(int i = 0; i < m; ++i){if(a[i]>=mb || m-1==i)ansa += mb;elseansa += a[i];}for(int i = 0; i < n; ++i){if(b[i]>=ma || n-1==i)ansb += ma;elseansb += b[i];}printf("%I64d\n", min(ansa, ansb));return 0;
}
这篇关于MemSQL Start[c]UP 2.0 - Round 2 - Online Round 题解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







