本文主要是介绍QEMU如何模拟目标机上的原子指令?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Qemu行为级emulator而非simulator,在模拟目标架构时,会利用HOST架构的支持特性实现目标架构的行为,下面分析一下QEMU对目标架构原子指令的模拟方式。
HOST架构自然是X86,为了搭建环境的方便,选择RISCV架构作为目标架构,参考这篇文章搭建RISCV QEMU运行环境:
https://blog.csdn.net/tugouxp/article/details/137614570?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22137614570%22%2C%22source%22%3A%22tugouxp%22%7D
验证方案
1.首先,确保初始目标架构程序没有调用任何原子指令,验证方法是在QEMU中模拟TARGE架构流程的必经之路do_atomic_op_i32/do_atomic_op_i64打断点,确保初始程序没有调用任何目标架构上的原子操作指令。以本测试为例,riscv_programming_practice/chapter_2/benos下的初始测试程序就没有调用任何原子指令,先在do_atomic_op_i32/do_atomic_op_i64打上断点,之后运行程序,不会进入断点。

2.之后加入断点程序:
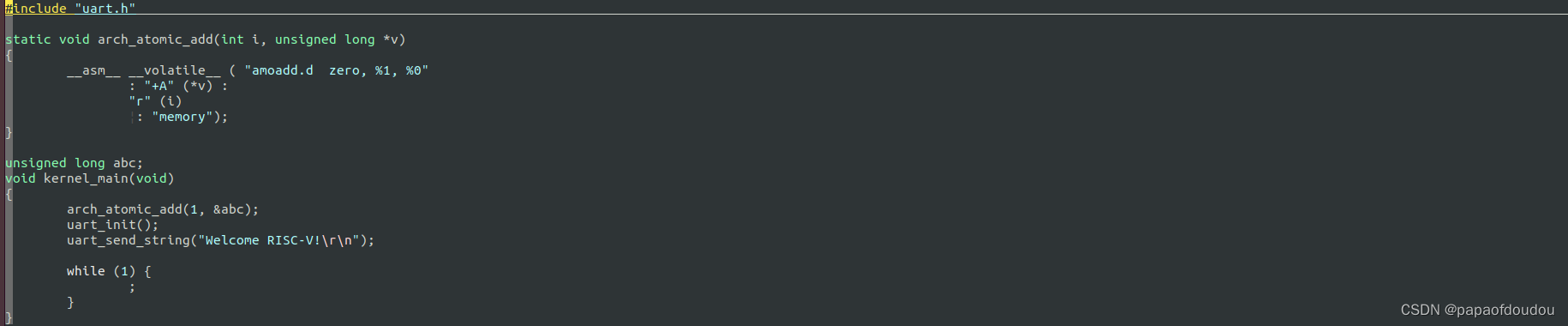
#include "uart.h" static void arch_atomic_add(int i, unsigned long *v)
{__asm__ __volatile__ ( "amoadd.d zero, %1, %0": "+A" (*v) :"r" (i) ¦: "memory");
}unsigned long abc;
void kernel_main(void)
{arch_atomic_add(1, &abc);uart_init();uart_send_string("Welcome RISC-V!\r\n");while (1) {;}
}
再次打上断点,发现这次拦截到了对原子操作指令的调用:

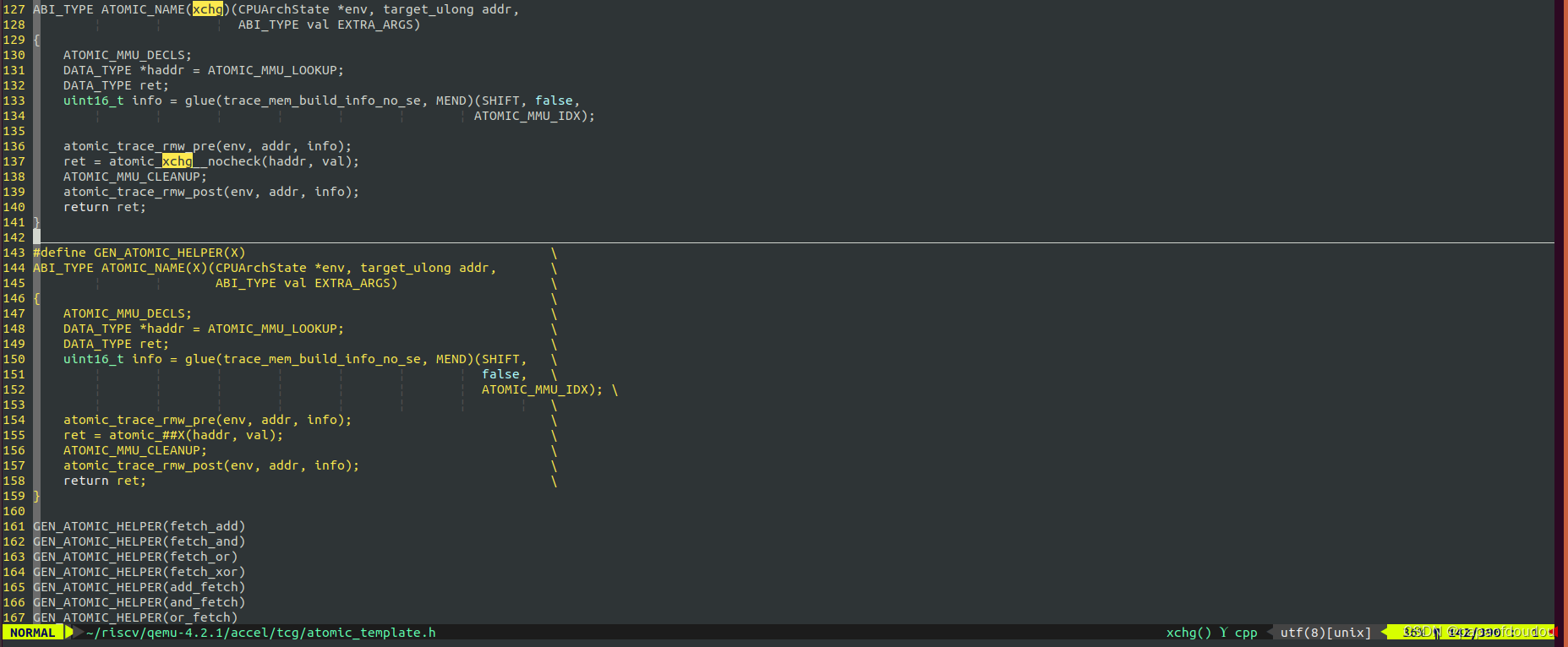
上述调用栈完成了对原子指令的翻译之后,之后开始执行GEN BUFFER中的指令,ATOMIC ADD指令具体由helper_atomic_fetch_addq_le函数实现:

helper_atomic_fetch_addq_le函数最终调用了X86 HOST主机的 "lock xadd"指令完成了对RISCV AMOADD指令的模拟操作。
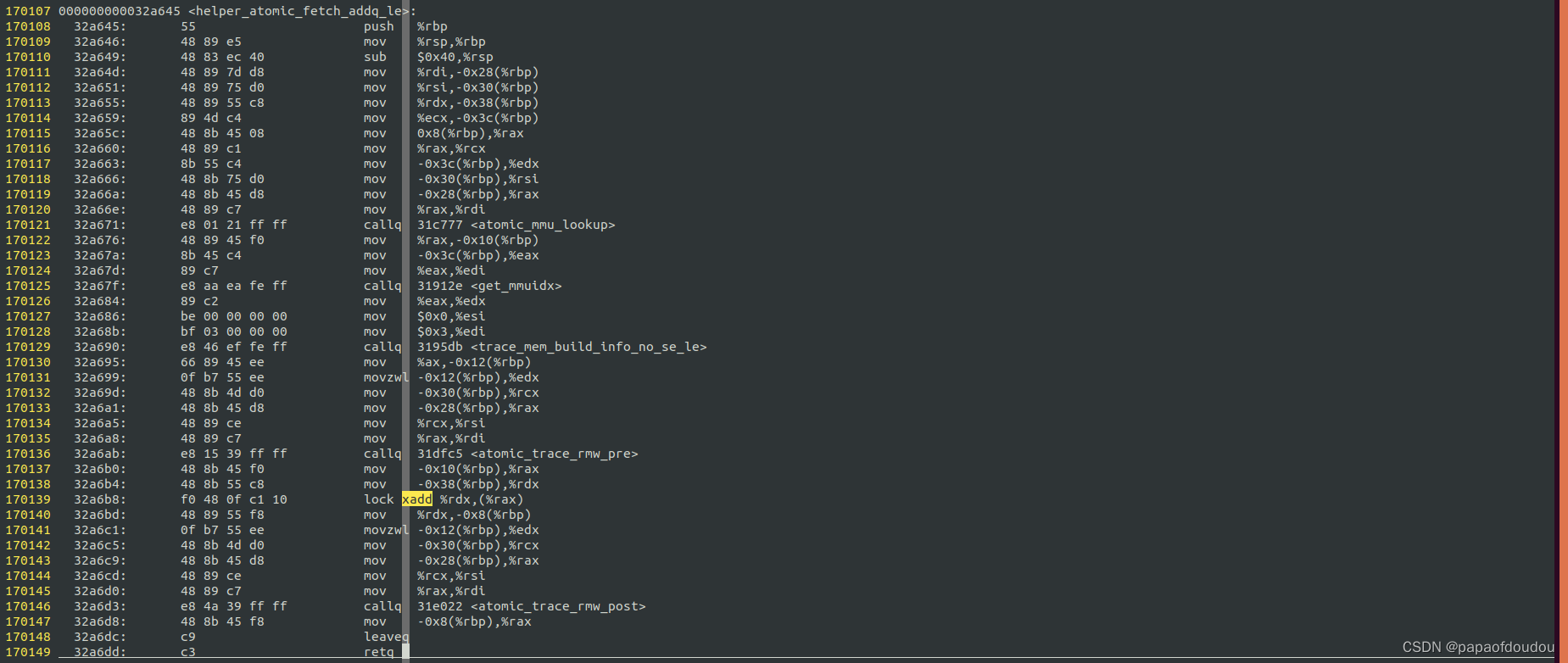
所以,这一种模拟方式是使用HOST架构CPU上的原子指令来模拟目标主机架构上的原子指令。

RISCV amoswap.d指令的模拟
测试代码:
#include "uart.h"unsigned long xchg(volatile void *ptr, unsigned long new)
{ unsigned long result;asm volatile (" amoswap.d %[result], %[new], (%[ptr])\n": [result]"=r"(result), [ptr]"+r"(ptr): [new]"r"(new): "memory");return result;
} void kernel_main(void)
{ unsigned long abc = 0;xchg(&abc, 2); uart_init();uart_send_string("Welcome RISC-V!\r\n");while (1) {;}
}运行时抓到的调用堆栈如下,可以看到,最终是通过helper_atomic_xchgq_le helper函数实现的,顾名思义,那一定是调用了X86 HOST主机上的xchgq指令了:
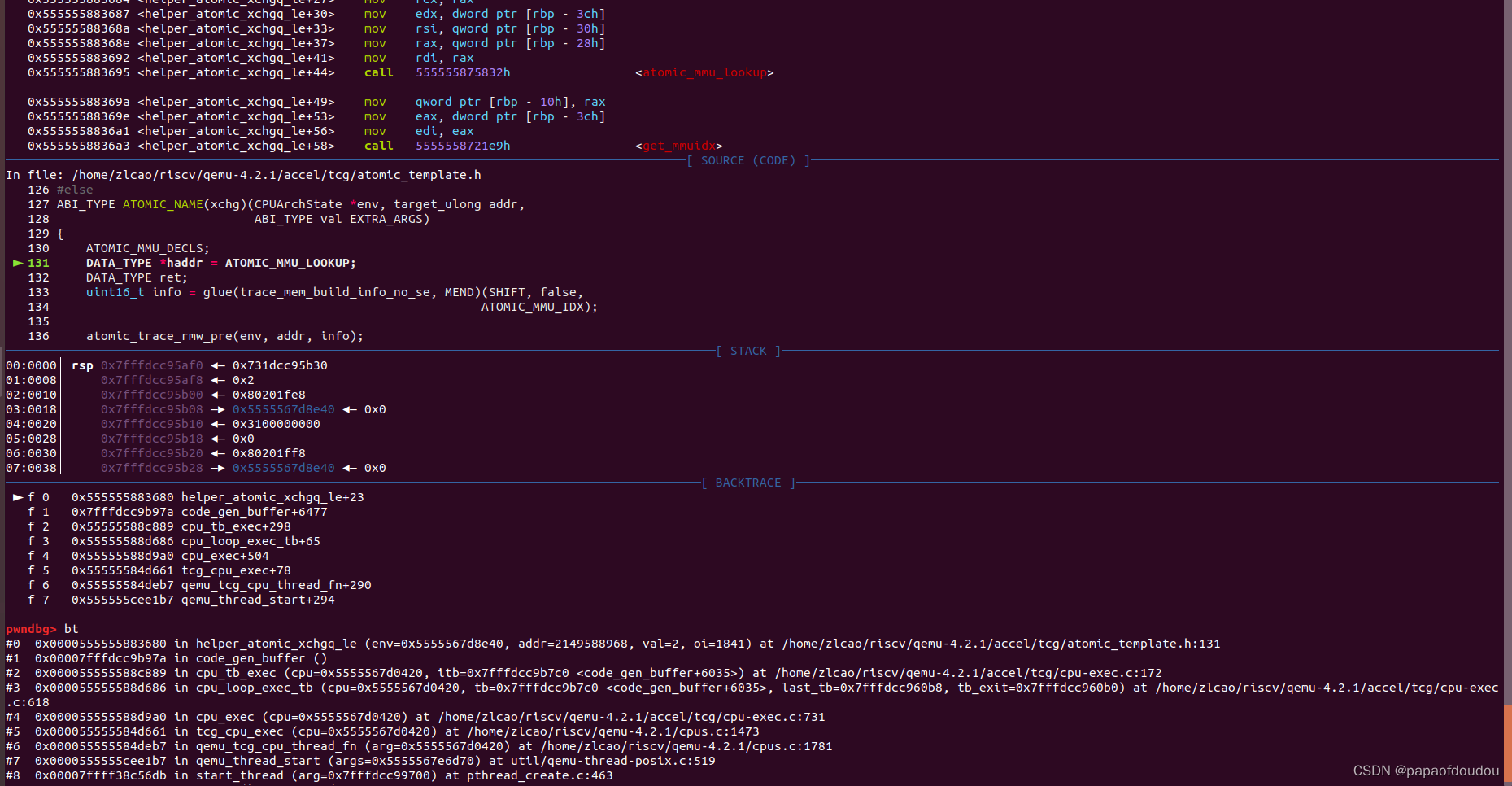
不知为何,这里没有在HOST指令xchg前加LOCK,可能是个问题吧,不管怎样,TARGET机到HOST机上的原子指令映射关系找到了。

总结:
用HOST主机的原子操作指令模拟目标机的原子指令的方式可以描述为,在指令翻译阶段,调用do_atomic_op_i64将目标机上的原子指令翻译成调用HOST机上的原子操作函数的HELPER指令。当指令BUFFER执行到原子指令操作时,进入HELPER函数,用HOST机上的原子指令替代目标机上的原子操作,实现原子操作的语义。

第二种方式 stop-the-world handling :
观察do_atomic_op_i64的实现发现,对应HOST机上的原子操作helper函数只有在CONFIG_ATOMIC64被定义时才会生成,而CONFIG_ATOMIC64是configure中根据动态检测HOST主机是否支持原子指令的结果设置的:

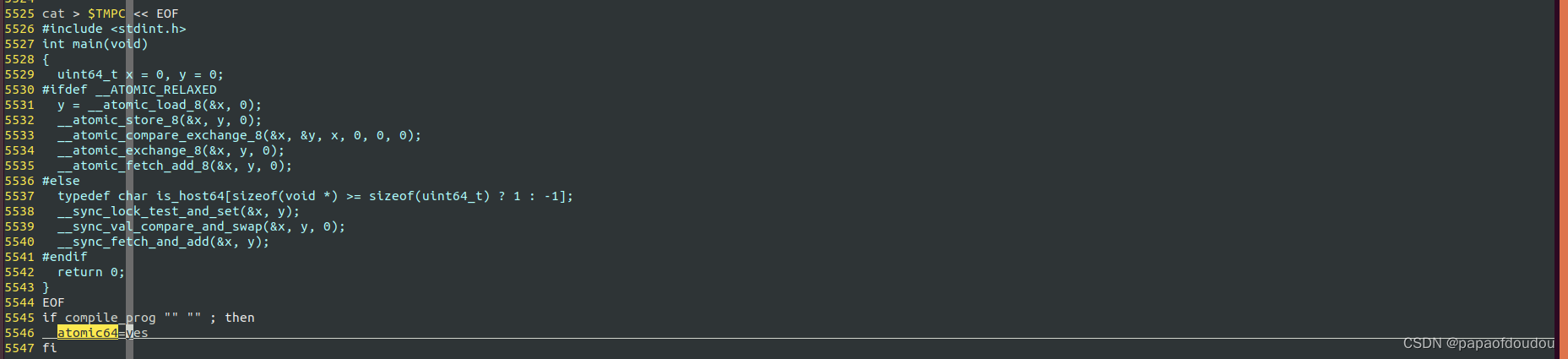
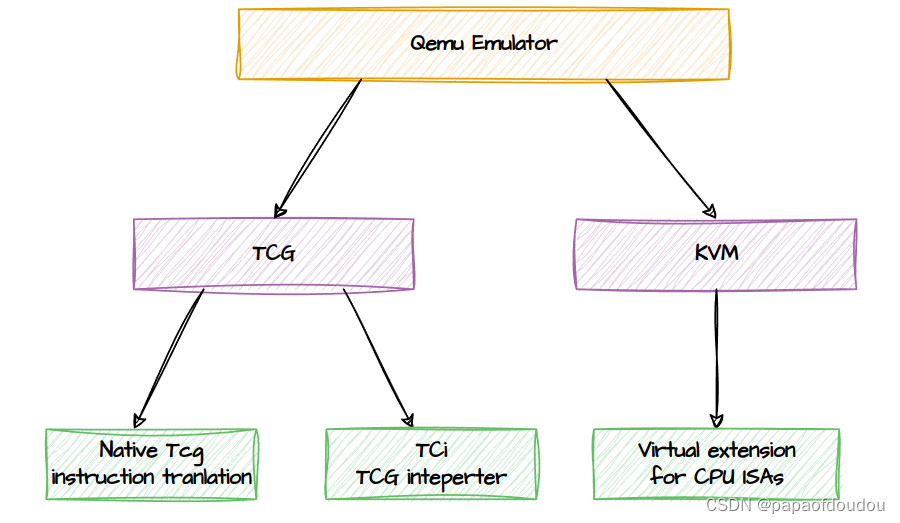
这实际上对应了QEMU的另一种原子操作实现方式:stop-the-world handling,停止世界。什么情况下需要这种原子操作机制来模拟TARGET机的原子指令呢?首先,虽然基本上所有处理器都支持原子操作指令,但是各处理器对原子操作指令的支持程度是不同的,并不是所有的目标架构上的原子指令在HOST机上都能得到支持。其次,即便HOST主机能够支持大部分目标机上的原子操作,但是有些特殊情况,比如8位,16位等等非字对齐的原子操作,基本上很难得到支持。所以,QEMU实现了这种被称为stop-the-world的原子指令实现方式。
在分析stop-the-word之前,首先思考一下,如果把这个问题交给你,该如何实现,QEMU有多个后端实现,包括KVM和TCG,TCG还包括NATIVE和TCI两种方式实现的后端,KVM只能应用在目标机和HOST机为相同架构的情况,不存在指令翻译,目标系统原子操作指令直接在HOST机上执行。不考虑这种情况。stop-the-world只适用于TCG模式,也就是下图左边的分支。
我们继续分析。为了关闭ATOMIC64,修改configure文件,强制关闭对atomic64的支持,之后重新编译QEMU:

由于CONFIG_ATOMIC64影响了do_atomic_op_i64函数的实现,而后者是TCGM模式下的一段公共代码,所以继续调试do_atomic_op_i64函数,此时,do_atomic_op_i64函数调用了gen_helper_exit_atomic,说明负责BUILD的HELPER函数变成了类似“helper_exit_atomic"之类的名字:
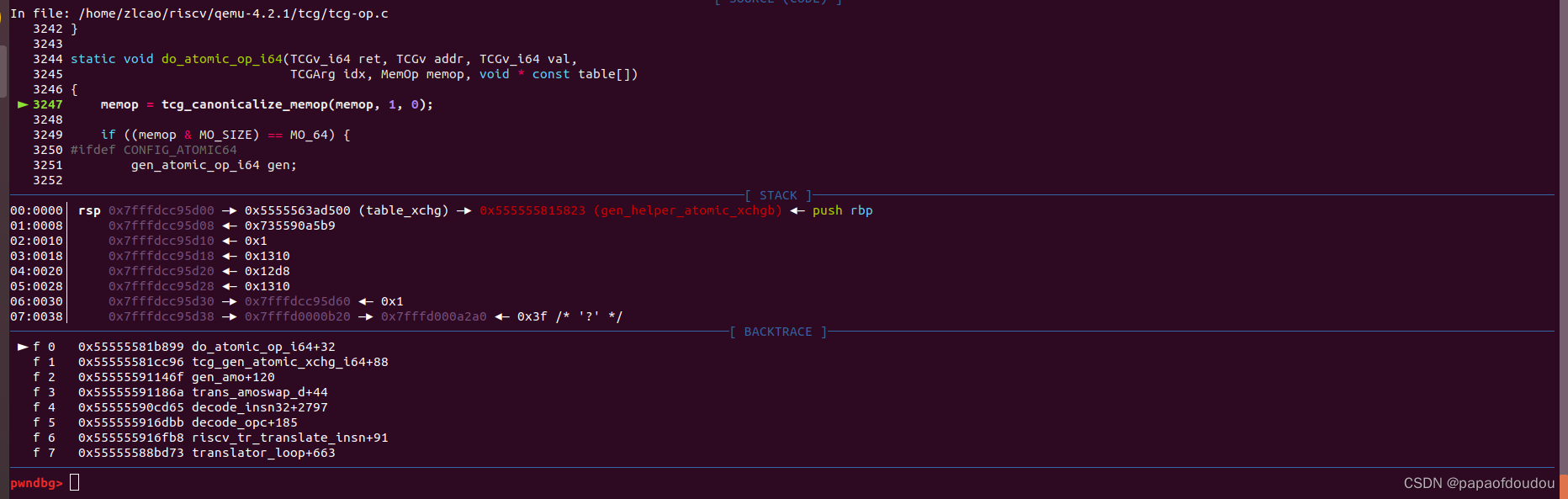
下一步,虽然并不确定是否存在一个名字为helper_exit_atomic的函数,不过可以先以helper_exit_atomic为符号打断点,如果能够打成功,说明存在这样的函数,经过测试,发现确实可以断在helper_exit_atomic函数上,函数定义在qemu-4.2.1/accel/tcg/tcg-runtime.c中,利用了宏技巧在编译阶段生成,所以直接在源码中搜索符号是搜不到的。
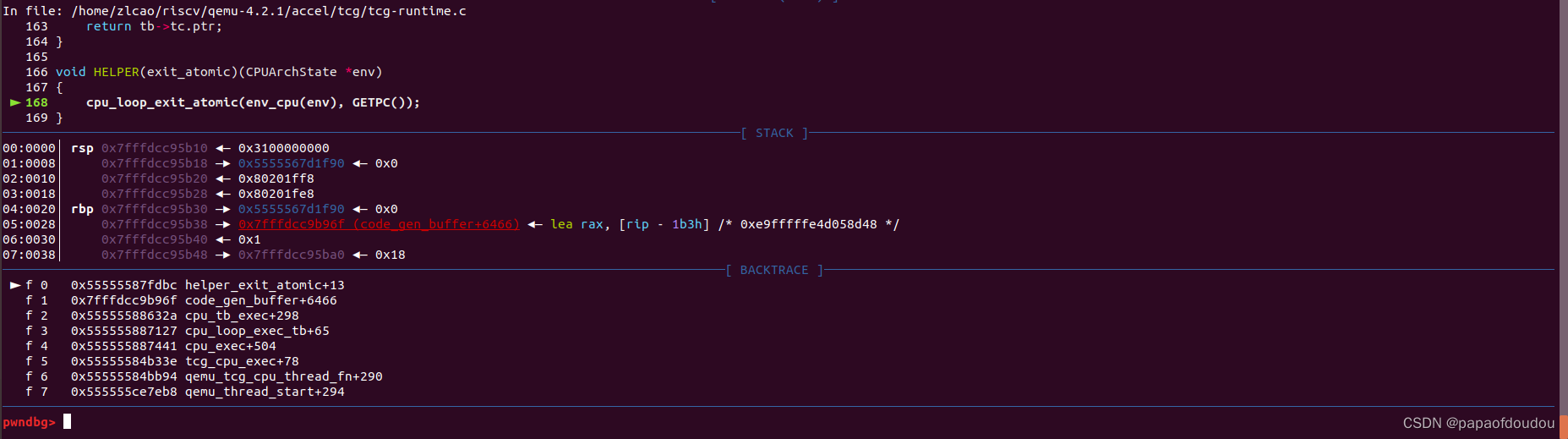
helper函数中调用了cpu_loop_exit_atomic函数,step 进入,发现除了将EXCP_ATOMIC赋值给cpu->exception_index,没有做其他事就RESTORE虚拟机状态了。
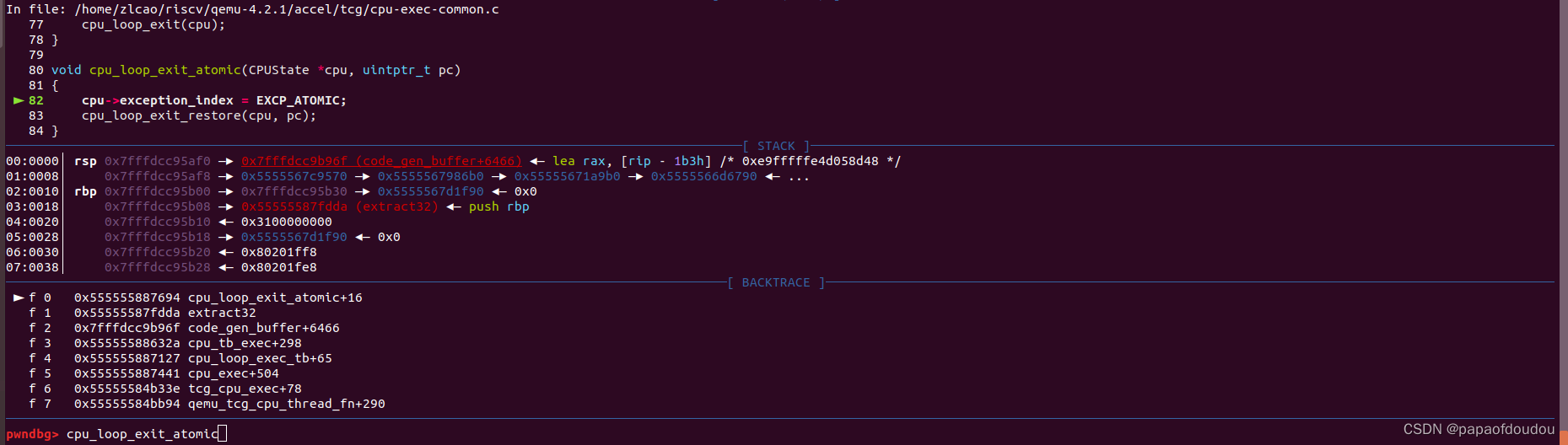
在QEMU中,exception_index一般用来记录VCPU的异常类型,这里将EXCP_ATOMIC赋值给exception_index,说明stop-the-world方式是通过触发QEMU自定义的EXCP_ATOMIC来处理原子指令的。

进一步分析,看QEMU是如何处理EXCP_ATOMIC类型的异常的,书接上回,当HELPER函数返回,QEMU 继续在TCG的CODE BUFFER中执行,由于CPU一般在每条指令的结束后检测异常,在结束当前CODE BUFFER中ATOMIC指令的执行后,异常将迫使虚拟机VCPU从tcg_cpu_exec退出,此时,tcg_cpu_exec返回值为EXCP_ATOMIC异常码,针对此类型的异常,QEMU继续执行cpu_exec_step_atomic处理:

cpu_exec_step_atomic函数继续处理,调用start_exclusive为当前CPU建立一个独占的执行环境,所谓保持原子性,从CPU的角度来看,无非保证同一时刻,某个内存变量只能被一个CPU处理,stop-the-world机制亦是如此,只不过它操作的对象不是物理CPU,而是QEMU的虚拟CPU VCPU,在QEMU中,每个VCPU对应一个线程,所以如何建立一个VCPU 独占的环境就变成了如何建立一个某个时刻只运行一个线程进入的临界区,建立临界区的方法很多,用户态MUTEX就可以,所以,如果不出意外,stop-the-world最终使用的是线程级同步机制实现的exclusive临界区。
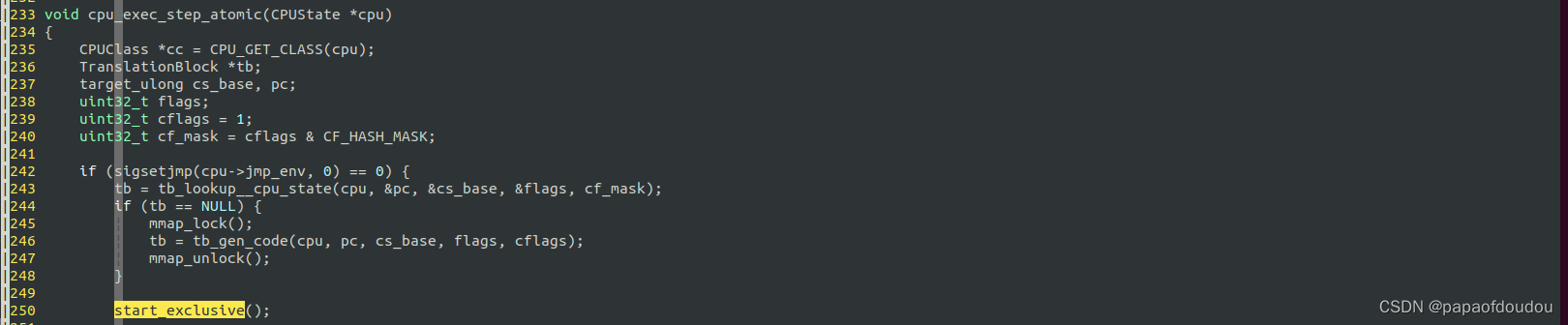
分析start_exclusive的实现,不必分析细节,仅仅从代码流程上看,它的目的应该是想起他VCPU发送信号,让其他VCPU停下来,只运行当前CPU执行,其同步函数使用的是qemu_cond_wait,底层通过pthread_cond_wait/pthread_cond_signal实现。

当从start_exclusive函数返回后,VCPU独占执行的环境已经具备,接着就可以再次进入VCPU 虚拟机,接着从ATOMIC原子指令的下一条指令开始执行了,由于此时只有一个VCPU在执行,原子性的语义自然得到了保证。

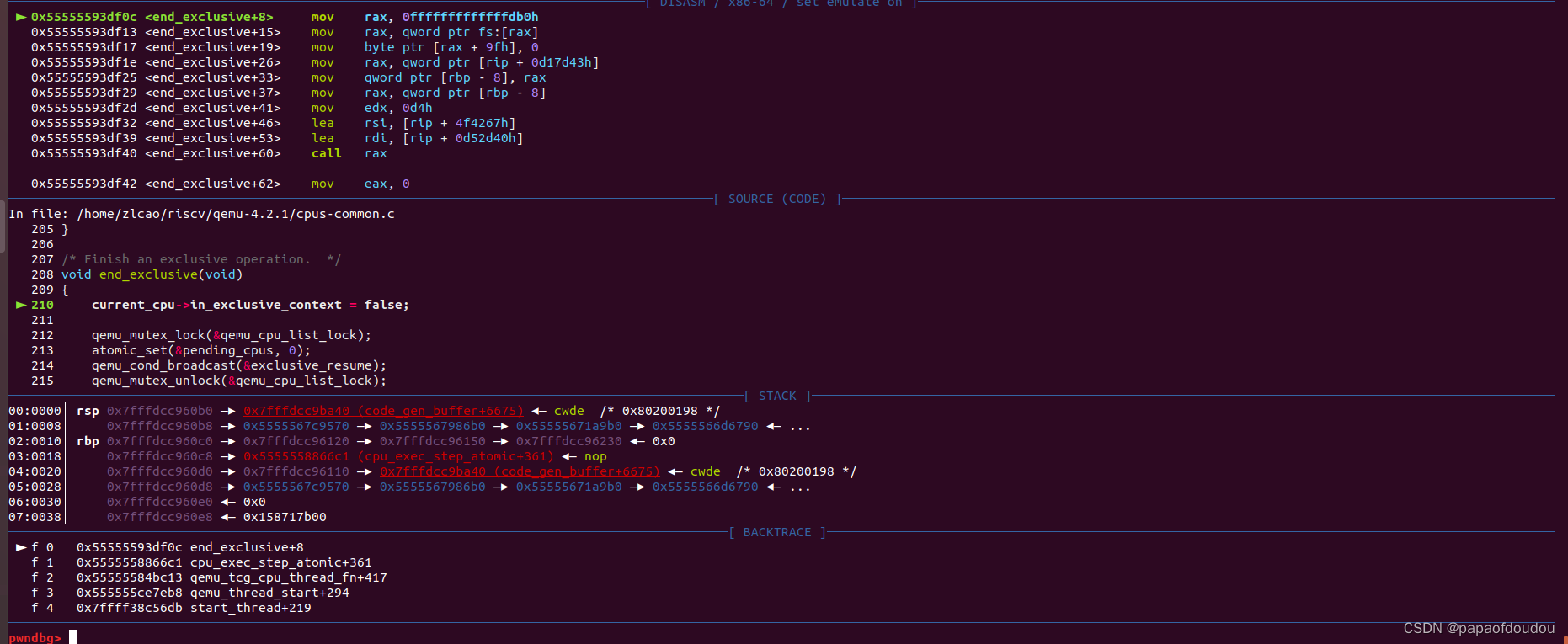
当原子指令执行结束后,QEMU会执行end_exclusive,唤醒其他VCPU,结束一个VCPU独占的状态:


start_exclulsive/end_exclusive调用堆栈:
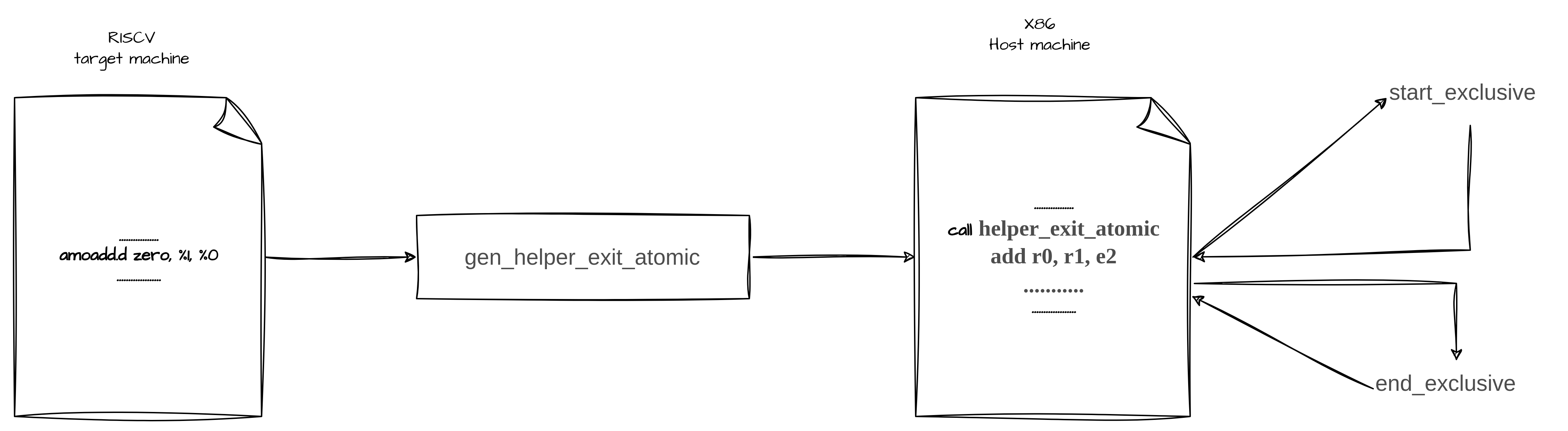
stop-the-world流程可以用下图简单表示
总结
关于QEMU对原子操作的指令,社区提供的回复总结:
All hosts that can run QEMU support at least some atomic instructions. Where possible we use the host atomic operations to provide the necessary atomicity guarantees that a guest instruction must have. For cases where we can't do that (eg where the guest needs an atomic 16-byte store but the host doesn't have one), we arrange to pause execution of all the other guest vCPU threads, do the thing that must be atomic, and then let everything resume.
I would suggest starting by translating some guest code with the atomic operation you're interested in, and using the '-d' suboptions in_asm, op and out_asm to look at the generated TCG operations and the generated host code for it.The stop-the-world handling happens when something calls cpu_loop_exit_atomic(), which then raises an EXCP_ATOMIC internal-to-QEMU exception, which is handled by some top-level-loop code that calls cpu_exec_step_atomic(), which (a) uses start_exclusive() and end_exclusive() to ensure that it is the only vcpu running and (b) generates new host code with the CF_PARALLEL flag clear to tell the translator that it can assume it's the only thing running (which in turn means "you don't need to actuallydo this operation atomically").
基本说明了通过HOST Native atomic 指令替代实现和stop-the-world两种方法实现,和分析是一致的。
结束
这篇关于QEMU如何模拟目标机上的原子指令?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







