本文主要是介绍Vitis HLS 学习笔记--HLS流水线基本用法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 简介
2. 示例
2.1 对内层循环打拍
2.2 对外层循环打拍
2.3 优化数组访问后打拍
3. 总结
1. 简介
本文介绍pipeline的基本用法。pipeline是一种用于提高硬件设计性能的技术。本文介绍了pipeline在累加计算函数中的应用。通过优化内外层循环和数组访问,显著提高了函数的时序性能,实现更高效的硬件设计。
2. 示例
这个程序定义了一个名为func的函数,接受一个长度为20的ap_int类型的数组A,数组中每个元素都是一个长度为5的ap_int类型。函数的目标是计算一个累加值并返回。
函数通过两个嵌套的循环对数组A进行遍历:
- 外部循环(LOOP_I)遍历数组A的所有元素。
- 内部循环(LOOP_J)对每个元素执行一个操作。
- 在内部循环中,数组A的第j个元素与外部循环的迭代次数i相乘,结果累加到一个名为acc的静态ap_int类型变量中。
- 最终,函数返回累加值acc。
2.1 对内层循环打拍
#include "ap_int.h"ap_int<20> func(ap_int<5> A[20]) {int i, j;static ap_int<20> acc;LOOP_I:for (i = 0; i < 20; i++) {LOOP_J:for (j = 0; j < 20; j++) {
#pragma HLS PIPELINEacc += A[j] * i;}}return acc;
}
C综合后,可以看到时序报告,函数func的Latency=405。循环II=1,Trip Count=400。
+ Performance & Resource Estimates: PS: '+' for module; 'o' for loop; '*' for dataflow+------------------+------+------+---------+-----------+----------+---------+------+----------+------+---------+----------+-----------+-----+| Modules | Issue| | Latency | Latency | Iteration| | Trip | | | | | | || & Loops | Type | Slack| (cycles)| (ns) | Latency | Interval| Count| Pipelined| BRAM | DSP | FF | LUT | URAM|+------------------+------+------+---------+-----------+----------+---------+------+----------+------+---------+----------+-----------+-----+|+ func | -| 4.92| 405| 4.050e+03| -| 406| -| no| -| 1 (~0%)| 68 (~0%)| 171 (~0%)| -|| o LOOP_I_LOOP_J | -| 7.30| 403| 4.030e+03| 5| 1| 400| yes| -| -| -| -| -|+------------------+------+------+---------+-----------+----------+---------+------+----------+------+---------+----------+-----------+-----+可以理解,两层循环20*20=400,II=1,所以Trip Count=400。符合我们的预期。
2.2 对外层循环打拍
#include "ap_int.h"ap_int<20> func(ap_int<5> A[20]) {int i, j;static ap_int<20> acc;LOOP_I:for (i = 0; i < 20; i++) {
#pragma HLS PIPELINELOOP_J:for (j = 0; j < 20; j++) {acc += A[j] * i;}}return acc;
}
C综合后,可以看到时序报告,func的Latency=13,II=14。
+ Performance & Resource Estimates: PS: '+' for module; 'o' for loop; '*' for dataflow+--------+------+------+---------+---------+----------+---------+------+----------+------+---------+----------+-----------+-----+| Modules| Issue| | Latency | Latency | Iteration| | Trip | | | | | | || & Loops| Type | Slack| (cycles)| (ns) | Latency | Interval| Count| Pipelined| BRAM | DSP | FF | LUT | URAM|+--------+------+------+---------+---------+----------+---------+------+----------+------+---------+----------+-----------+-----+|+ func | -| 0.82| 13| 130.000| -| 14| -| no| -| 1 (~0%)| 93 (~0%)| 444 (~0%)| -|+--------+------+------+---------+---------+----------+---------+------+----------+------+---------+----------+-----------+-----+通过观察Schedule可以发现, 数组A被默认绑定为ap_memory,实现形式是双端口ram,每个周期可读取2个元素,共计10个周期读取完毕,额外有4个周期进行了乘法运算和回写。所以II=14。

此结果并不符合预期,理论上,内层循环应该展开,外层循环被流水线打拍,func的Latency=20才对。
尝试使用 ARRAY_PARTITION 优化数组 A 访问。
#include "ap_int.h"ap_int<20> func(ap_int<5> A[20]) {
#pragma HLS ARRAY_PARTITION dim=0 type=complete variable=Aint i, j;static ap_int<20> acc;LOOP_I:for (i = 0; i < 20; i++) {
#pragma HLS PIPELINELOOP_J:for (j = 0; j < 20; j++) {acc += A[j] * i;}}return acc;
}
C综合后的结果如下:
+ Performance & Resource Estimates: PS: '+' for module; 'o' for loop; '*' for dataflow+--------+------+------+---------+--------+----------+---------+------+----------+------+---------+----------+-----------+-----+| Modules| Issue| | Latency | Latency| Iteration| | Trip | | | | | | || & Loops| Type | Slack| (cycles)| (ns) | Latency | Interval| Count| Pipelined| BRAM | DSP | FF | LUT | URAM|+--------+------+------+---------+--------+----------+---------+------+----------+------+---------+----------+-----------+-----+|+ func | -| 1.50| 3| 30.000| -| 4| -| no| -| 1 (~0%)| 24 (~0%)| 278 (~0%)| -|+--------+------+------+---------+--------+----------+---------+------+----------+------+---------+----------+-----------+-----+其中II=4,我无法理解。从Schedule Viewer来看,似乎是乘法运算和回写占用了4个周期。
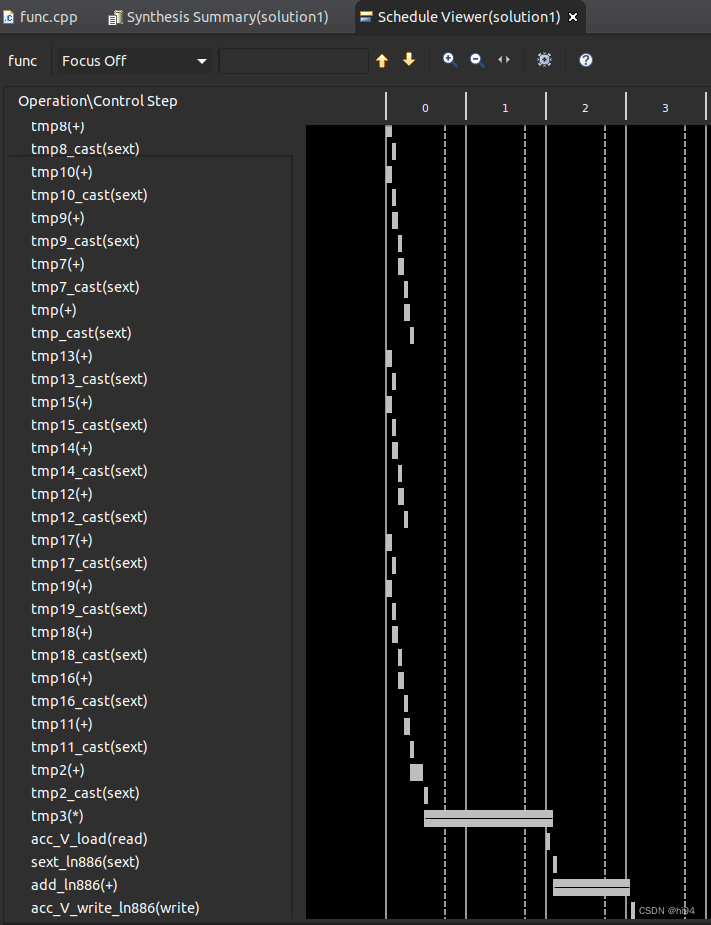
此结果的原因未知。后续研究之后再补充吧。
2.3 优化数组访问后打拍
#include "ap_int.h"ap_int<20> func(ap_int<5> A[20]) {
#pragma HLS ARRAY_PARTITION dim=0 type=complete variable=Aint i, j;static ap_int<20> acc;#pragma HLS PIPELINE
LOOP_I:for (i = 0; i < 20; i++) {LOOP_J:for (j = 0; j < 20; j++) {acc += A[j] * i;}}return acc;
}
为了最大化榨取并行处理能力,我们做了“最疯狂”的优化:
- 使用 ARRAY_PARTITION 对数组A进行分区,将其完全分割为独立元素,每个周期可以访问所有元素。
- PIPELINE 在函数提内,HLS 工具会展开所有循环,即双层循环会在一个周期内完成。
+ Performance & Resource Estimates: PS: '+' for module; 'o' for loop; '*' for dataflow+--------+------+------+---------+--------+----------+---------+------+----------+------+---------+-----------+-----------+-----+| Modules| Issue| | Latency | Latency| Iteration| | Trip | | | | | | || & Loops| Type | Slack| (cycles)| (ns) | Latency | Interval| Count| Pipelined| BRAM | DSP | FF | LUT | URAM|+--------+------+------+---------+--------+----------+---------+------+----------+------+---------+-----------+-----------+-----+|+ func | II| 1.50| 3| 30.000| -| 1| -| yes| -| 1 (~0%)| 240 (~0%)| 649 (~0%)| -|+--------+------+------+---------+--------+----------+---------+------+----------+------+---------+-----------+-----------+-----+查看C综合结果,符合我们的预期。
3. 总结
本文介绍了使用pipeline进行硬件优化的基本方法,并通过示例展示了不同优化方式的性能影响。针对累加计算函数,我们通过内外层循环的pipeline优化和数组访问优化,显著提高了时序性能,从405个周期降至3个周期。这些优化方法可有效应用于其他硬件设计中,提高性能和效率。

这篇关于Vitis HLS 学习笔记--HLS流水线基本用法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






