本文主要是介绍nn.GRU层输出:state与output的关系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
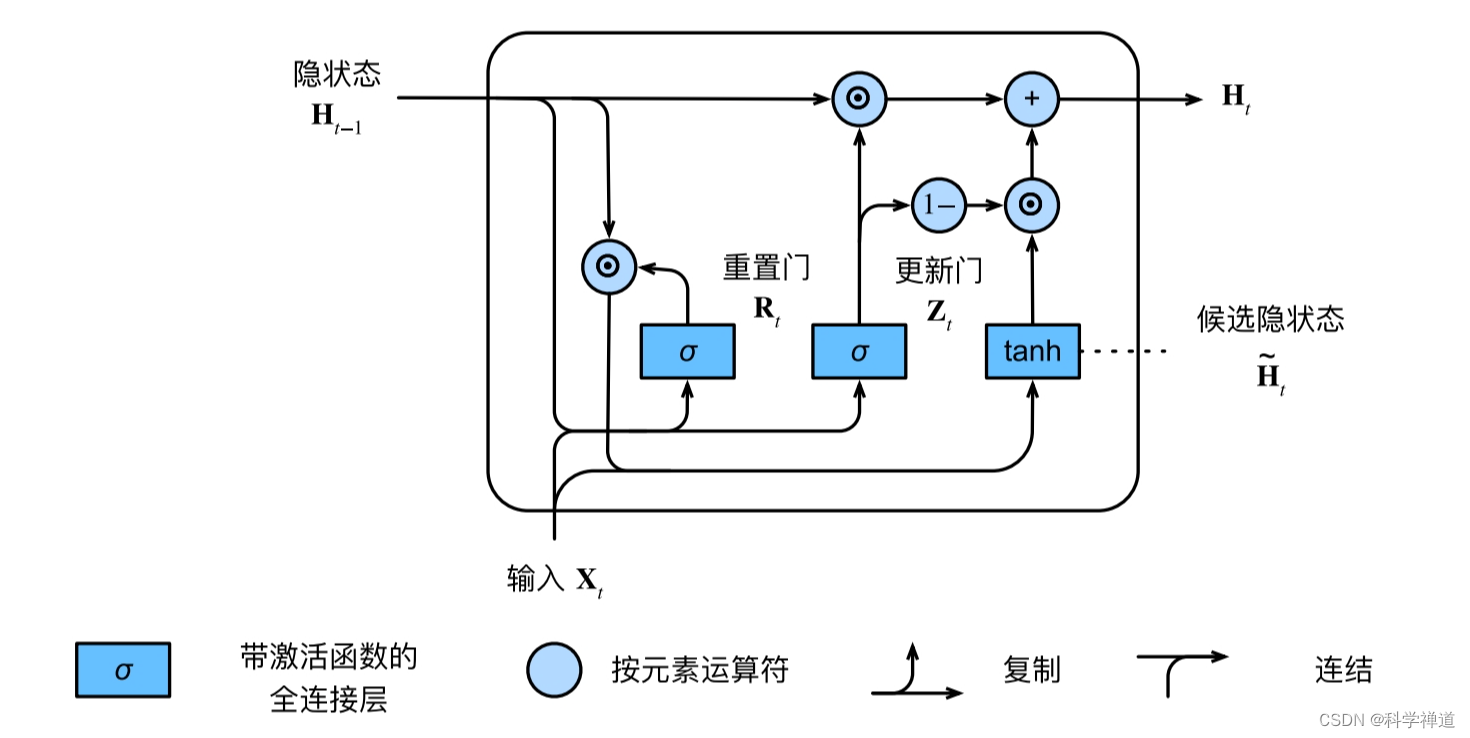
在 GRU(Gated Recurrent Unit)中,output 和 state 都是由 GRU 层的循环计算产生的,它们之间有直接的关系。state 实际上是 output 中最后一个时间步的隐藏状态。
GRU 的基本公式
GRU 的核心计算包括更新门(update gate)和重置门(reset gate),以及候选隐藏状态(candidate hidden state)。数学表达式如下:
-
更新门 \( z_t \): \[ z_t = \sigma(W_z \cdot h_{t-1} + U_z \cdot x_t) \]
其中,\( \sigma \) 是sigmoid 函数,\( W_z \) 和 \( U_z \) 分别是对应于隐藏状态和输入的权重矩阵,\( h_{t-1} \) 是上一个时间步的隐藏状态,\( x_t \) 是当前时间步的输入。 -
重置门 \( r_t \):
\[ r_t = \sigma(W_r \cdot h_{t-1} + U_r \cdot x_t) \]
\( W_r \) 和 \( U_r \) 是更新门中定义的相似权重矩阵。 -
候选隐藏状态 \( \tilde{h}_t \):
\[ \tilde{h}_t = \tanh(W \cdot r_t \odot h_{t-1} + U \cdot x_t) \]
这里,\( \tanh \) 是激活函数,\( \odot \) 表示元素乘法(Hadamard product),\( W \) 和 \( U \) 是隐藏状态的权重矩阵。 -
最终隐藏状态 \( h_t \):
\[ h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \]
output 和 state 的关系
-
output:在 GRU 中,output 包含了序列中每个时间步的隐藏状态。具体来说,对于每个时间步 \( t \),output 的第 \( t \) 个元素就是该时间步的隐藏状态 \( h_t \)。 -
state:state 是 GRU 层最后一层的隐藏状态,也就是 output 中最后一个时间步的隐藏状态 \( h_{T-1} \),其中 \( T \) 是序列的长度。
数学表达式
如果我们用 \( O \) 表示 output,\( S \) 表示 state,\( T \) 表示时间步的总数,那么:
\[ O = [h_0, h_1, ..., h_{T-1}] \]
\[ S = h_{T-1} \]
因此,state 实际上是 output 中最后一个元素,即 \( S = O[T-1] \)。
在 PyTorch 中,output 和 state 都是由 GRU 层的 `forward` 方法计算得到的。`output` 是一个三维张量,包含了序列中每个时间步的隐藏状态,而 `state` 是一个二维张量,仅包含最后一个时间步的隐藏状态。
代码示例
class Seq2SeqEncoder(d2l.Encoder):
"""⽤于序列到序列学习的循环神经⽹络编码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):super(Seq2SeqEncoder, self).__init__(**kwargs)# 嵌⼊层self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,dropout=dropout)def forward(self, X, *args):# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X)# 在循环神经⽹络模型中,第⼀个轴对应于时间步X = X.permute(1, 0, 2)# 如果未提及状态,则默认为0output, state = self.rnn(X)# output的形状:(num_steps,batch_size,num_hiddens)# state的形状:(num_layers,batch_size,num_hiddens)return output, stateoutput:在完成所有时间步后,最后⼀层的隐状态的输出output是⼀个张量(output由编码器的循环层返回),其形状为(时间步数,批量⼤⼩,隐藏单元数)。
state:最后⼀个时间步的多层隐状态是state的形状是(隐藏层的数量,批量⼤⼩, 隐藏单元的数量)。
这篇关于nn.GRU层输出:state与output的关系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






