本文主要是介绍【CAP探索者指南】掌握分布式世界的三角平衡术,一致性、可用性、分区容错性大揭秘!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注微信公众号 “程序员小胖” 每日技术干货,第一时间送达!
引言
在现代的微服务架构中,系统被拆分成了许多小型服务,每个服务可能有自己的数据库。这种架构带来了灵活性和可扩展性,但也引入了新的挑战,尤其是在事务管理方面。分布式事务确保了在跨多个服务的操作中,所有事务的参与者要么全部成功提交,要么在遇到错误时全部回滚,从而保持了数据的最终一致性。
CAP理论
CAP理论是分布式系统设计中的一个核心原则,它指出在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个特性无法同时完全满足。一个分布式系统只能满足这三个特性中的两个。
一致性(Consistency)
在分布式系统中,一致性意味着所有节点在同一时间看到的数据是相同的。当一个写操作完成后,所有节点在同一时间的数据完全一致,等同于所有节点拥有数据的最新版本。
可用性(Availability)
可用性强调分布式系统在任何时候都能够响应请求,即使在部分节点故障的情况下,系统也能够继续处理请求。
我们平时会看到一些 IT 公司的对外宣传,比如系统稳定性已经做到 3 个 9、4 个 9,即 99.9%、99.99%,这里的 N 个 9 就是对可用性的一个描述,叫做 SLA,即服务水平协议。比如我们说月度 99.95% 的 SLA,则意味着每个月服务出现故障的时间只能占总时间的 0.05%,如果这个月是 30 天,那么就是 21.6 分钟。
分区容错性(Partition tolerance)
当部分节点出现消息丢失或者分区故障的时候,分布式系统仍然能够继续运行,即系统容忍网络出现分区,并且在遇到某节点或网络分区之间网络不可达的情况下,仍然能够对外提供满足一致性和可用性的服务
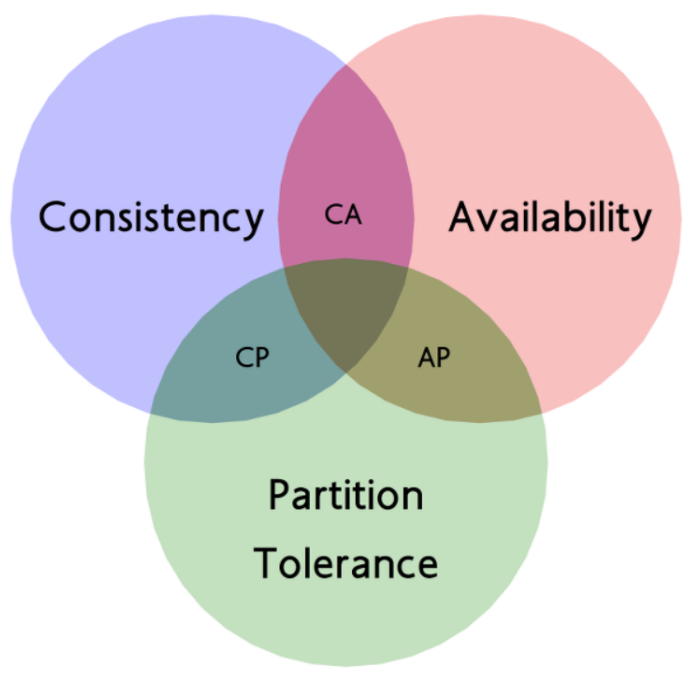
使用场景分析
CA系统(一致性与可用性)
**场景:**需要强一致性的数据库系统,如关系型数据库 mysql。
**设计:**通过引入事务机制、两阶段提交等协议来保证一致性。在网络分区发生时,可能会牺牲一部分可用性,例如通过锁定机制来防止数据不一致。
由于严格的CA系统在分布式环境中难以实现,我们可以展示一个简化版的伪代码思路,模拟一个中心化服务,它在理想状态下提供了高可用性和强一致性。但请记住,这并不直接对应于真实的分布式系统设计。
// 简化模拟:中心化服务,模拟一致性与可用性优先
class CentralizedService {private Map<String, String> dataStore = new ConcurrentHashMap<>();// 写入数据,确保所有操作直接作用于单一存储源,保证一致性synchronized void put(String key, String value) {dataStore.put(key, value);}// 读取数据,直接从单一存储源读取,保证一致性String get(String key) {return dataStore.get(key);}
}public class CADemo {public static void main(String[] args) {CentralizedService service = new CentralizedService();// 模拟写操作new Thread(() -> {service.put("exampleKey", "exampleValue");}).start();// 模拟读操作new Thread(() -> {try {Thread.sleep(100); // 确保写操作先执行} catch (InterruptedException e) {e.printStackTrace();}System.out.println(service.get("exampleKey"));}).start();}
}
CP系统(一致性与分区容错性)
**场景:**对于数据一致性要求极高的系统,如金融交易系统 (ZooKeeper,Redis(Redis配置为主从复制且采用严格一致性模式时))。
**设计:**当网络分区发生时,系统可能会拒绝服务以保证数据一致性,直到网络分区问题解决。
//1.使用zookeeper 实现分布式锁
import org.apache.zookeeper.*;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;public class DistributedLock {private final ZooKeeper zookeeper;private final String lockPath;private String currentLock;private CountDownLatch latch;public DistributedLock(ZooKeeper zookeeper, String lockPath) {this.zookeeper = zookeeper;this.lockPath = lockPath;}public boolean lock() throws KeeperException, InterruptedException {try {currentLock = zookeeper.create(lockPath + "/lock-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);List<String> children = zookeeper.getChildren(lockPath, false);Collections.sort(children);if (currentLock.equals(lockPath + "/" + children.get(0))) {// 如果当前锁是最小的,则获取锁成功return true;} else {// 不是最小的锁,找到比自己小1的锁并监听它String prevLock = lockPath + "/" + children.get(Collections.binarySearch(children, currentLock.substring(lockPath.length() + 1)) - 1);latch = new CountDownLatch(1);zookeeper.exists(prevLock, event -> {if (event.getType() == Watcher.Event.EventType.NodeDeleted) {latch.countDown();}});latch.await(); // 阻塞等待锁释放return true; // 锁释放后尝试重新获取锁}} catch (KeeperException | InterruptedException e) {throw e;}}public void unlock() throws InterruptedException, KeeperException {zookeeper.delete(currentLock, -1);}
}//2.在业务逻辑处理中,利用上面的分布式锁确保每次更新操作的原子性和一致性:
public class InventoryManager {public void updateStock(int quantity, String productId) throws KeeperException, InterruptedException {DistributedLock lock = new DistributedLock(ZKConnection.zookeeper, "/inventoryLocks");lock.lock(); // 获取锁try {// 这里执行实际的库存更新逻辑,例如调用数据库更新接口System.out.println("Updating stock for product " + productId + " by " + quantity);// 更新库存代码...} finally {lock.unlock(); // 操作完成后释放锁}}
}
AP系统(可用性与分区容错性)
**场景:**对可用性要求较高的系统,如Web搜索、社交网络等 (es,redis(配置为异步复制时),MongoDB(默认配置))。
**设计:**在网络分区发生时,系统继续提供服务,但可能会读到过时的数据。通过最终一致性模型来保证数据最终达到一致的状态。
代码示例:简化版分布式缓存系统(偏向AP)
// 简化的Cache接口
interface Cache {void put(String key, String value);String get(String key);
}// 偏向AP的实现,使用HashMap模拟内存缓存
class DistributedCache implements Cache {private ConcurrentHashMap<String, String> cache = new ConcurrentHashMap<>();@Overridepublic void put(String key, String value) {// 简单的写入操作cache.put(key, value);}@Overridepublic String get(String key) {// 立即返回本地缓存的值,保证可用性return cache.get(key);}// 实际场景中还需考虑数据同步机制,例如使用最终一致性模型
}public class CAPDemo {public static void main(String[] args) {DistributedCache cache = new DistributedCache();cache.put("key", "value");System.out.println(cache.get("key")); // 即使在分区情况下,也能读取到旧值,体现了可用性}
}
对于多数大型互联网应用的场景,结点众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9(99.99…%),并要达到良好的响应性能来提高用户体验,因此一般都会做出 如下选择:保证P和A,舍弃C强一致,保证最终一致性。
结语
在实际应用中,系统设计者需要根据业务需求和场景特点来决定哪些特性是优先考虑的,并据此做出合理的架构决策。例如,对于需要实时数据处理和高并发访问的互联网应用,可能会倾向于选择AP模型;而对于数据准确性和一致性要求极高的金融系统,则可能会选择CP模型。同时,随着技术的发展,一些新型的分布式系统设计如BASE模型(Basically Available, Soft state, Eventual consistency)提出了对CAP理论的补充,强调了最终一致性,以适应实际应用中的灵活性需求。
这篇关于【CAP探索者指南】掌握分布式世界的三角平衡术,一致性、可用性、分区容错性大揭秘!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



