本文主要是介绍Redis系列-2 Redis持久化机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景:
服务器重启后会丢失内存中的全部数据,内存数据库如果没有持久化机制,难以保证数据的可靠性,如Memcached。Redis提供了RDB(基于全量)和AOF(基于增量)两种持久化机制,一方面可以保证数据的可靠性,当服务器意外宕机重启后,Redis从持久化文件中读取数据,可以快速恢复到宕机前的状态;另外,基于持久化文件可以实现数据备份、数据扩展和搭建Redis集群。
1.RDB
RDB持久化当前内存快照的数据,属于全量同步。RDB有两种触发类型: 当Redis客户端执行save命令时,使用Redis主进程进行持久化,会阻塞此期间的用户请求;当Redis客户端执行bgsave命令或者配置文件中save规则触发持久化时,通过创建子进程并将持久化任务委托给子进程,从而不会阻塞Redis主线程。持久化完成后会生成一个持久化文件dump.rdb文件, 文件内容是二进制数据。当RDB开启而AOF关闭,重启服务时,Redis会根据dump.rdb文件恢复内存数据。
save规则可通过redis.conf配置文件或通过命令形式:
# 查看save规则
traffic:0>config get save
1) "save"
2) "900 1 300 10 60 10000"# 清空save规则
traffic:0>config set save ""
"OK"
traffic:0>config get save
1) "save"
2) ""# 新增save规则
traffic:0>config set save "900 1"
"OK"
traffic:0>config get save
1) "save"
2) "900 1"
“save 900 1"持久化规则表示每900秒内有key进行了修改,触发持久化;将save设置为""时,表示关闭RDB。
另外,dir(持久化存放文件路径)和dbfilename(持久化文件名称)是受保护的配置,不可通过config set命令修改。
RDB实现机制
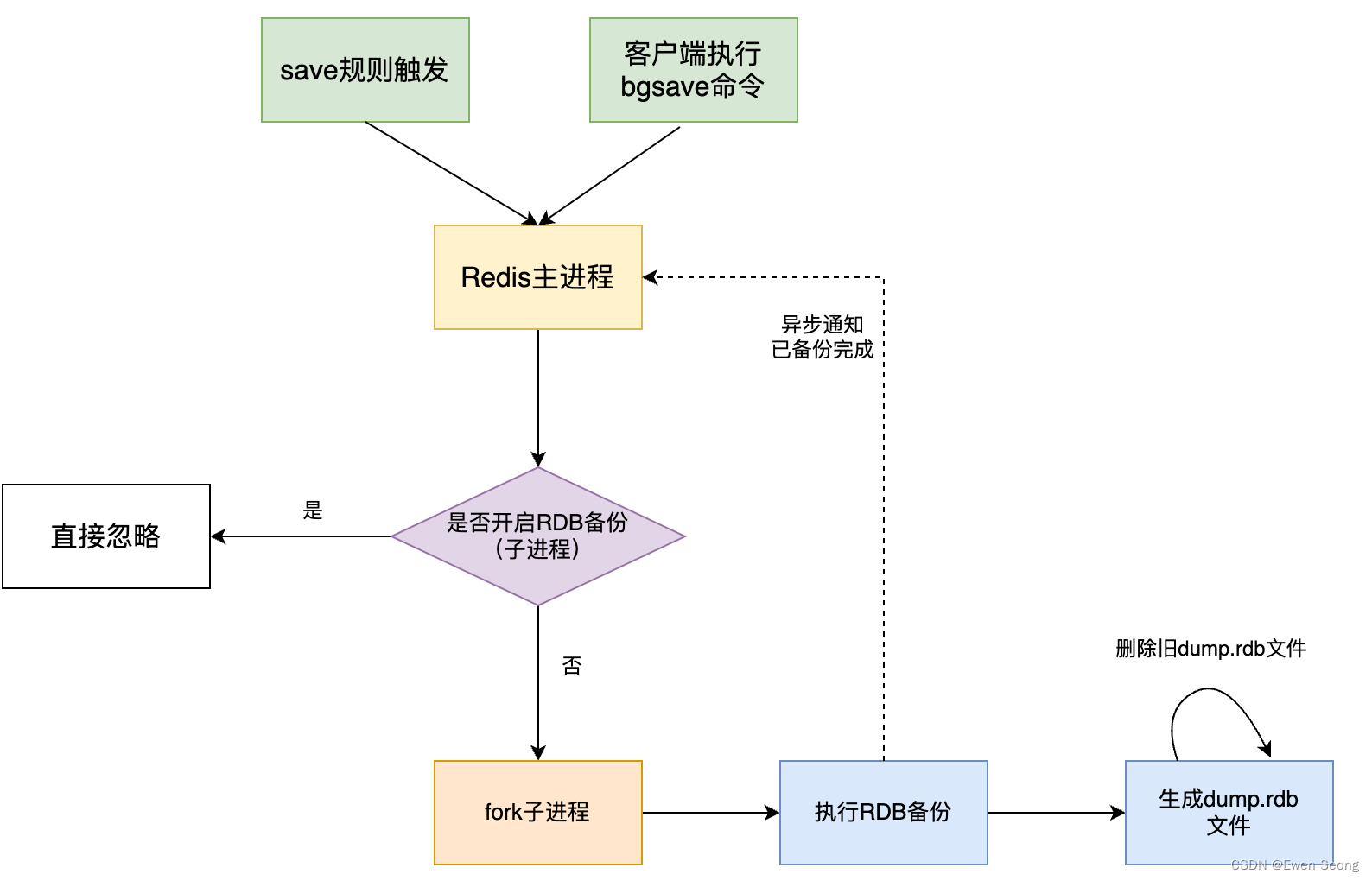
如上图所示,通过bgsave指令或者save规则(本质也是bgsave指令)触发,Redis主进程会创建一个子进程,将RDB持久化操作委托给子进程处理, 子进程将内存快照写入临时dump.rdb文件,之后替换原有的dump.rdb文件。其中,Redis主进程fork子进程时会阻塞,且内存越大阻塞时间越长。
内存快照
Redis主进程fork子进程时,子进程共享主进程的所有内存信息,如下图所示:
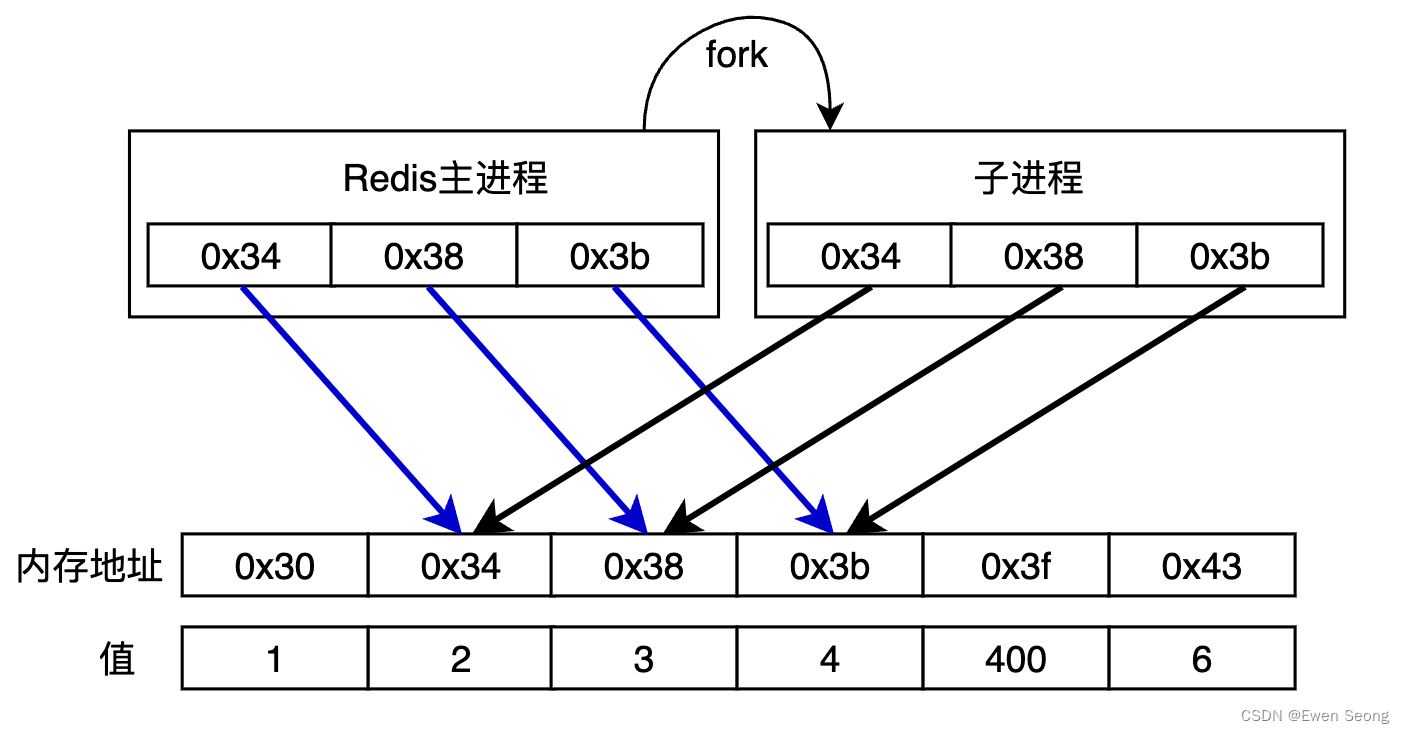
通过CopyOnWrite技术,Redis数据库信息在内存中仅保存一份:主进程修改数据时,复制一份副本并在副本的基础上进行修改,未修改的部分与之前保持一致。当主进程将内存中0x3b地址的值由4改成400时,有如下变化:
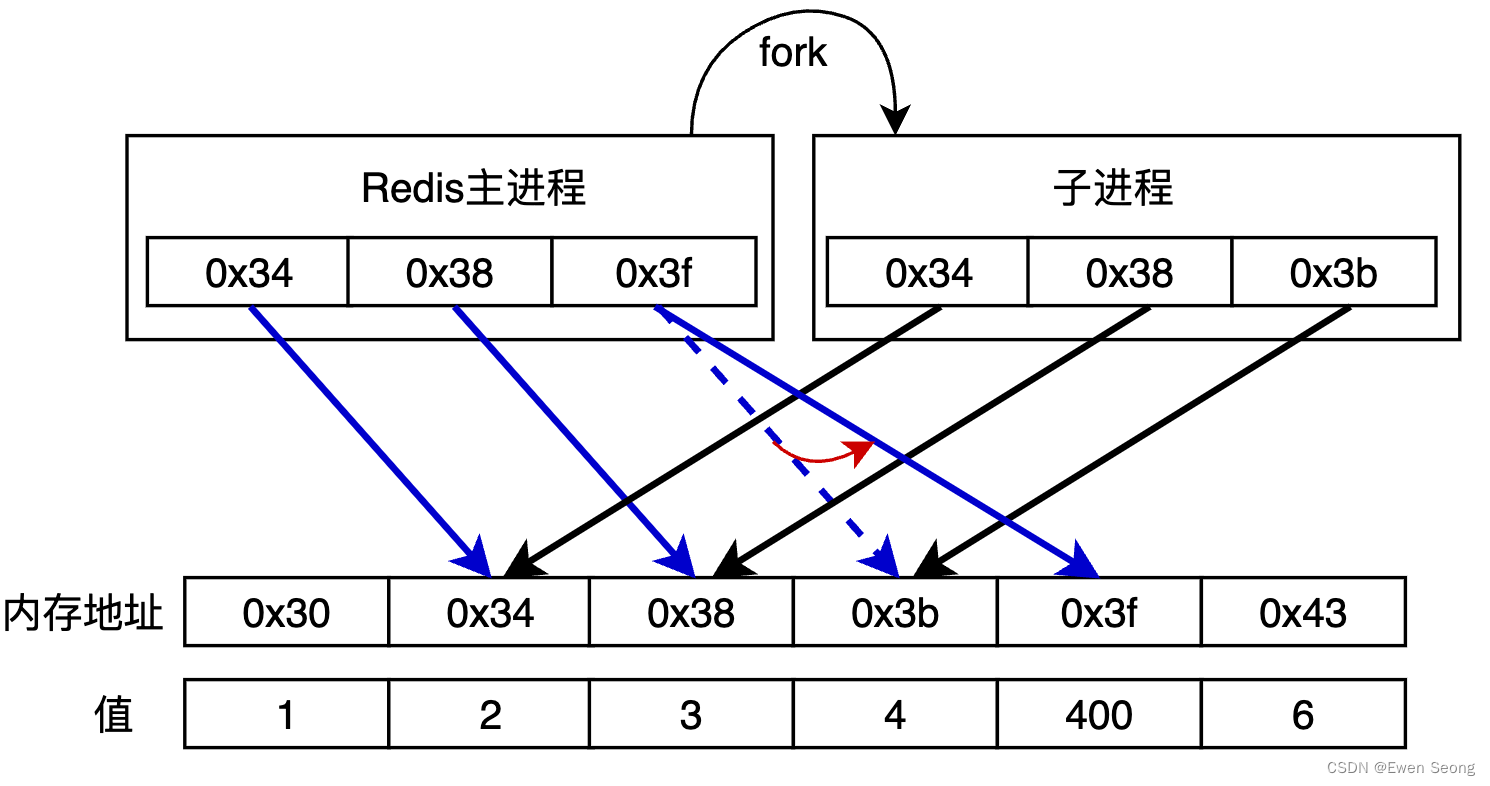
当主进程对0x3b的数据写操作时,系统的CopyOnWrite机制将复制0x3b数据至0x3f, 并将主进程的内存地址由0x3b切换至0x3f; 主进程对0x3f进行写操作,数据由4修改为40。
需要注意的是,主进程未修改部分内存地址无变化,子进程全部内存地址无变化。因此,子进程被fork后,Redis主进程的数据变化对子进程不可见,子进程保留了被fork瞬间主进程的全部内存信息, 也叫做内存快照。
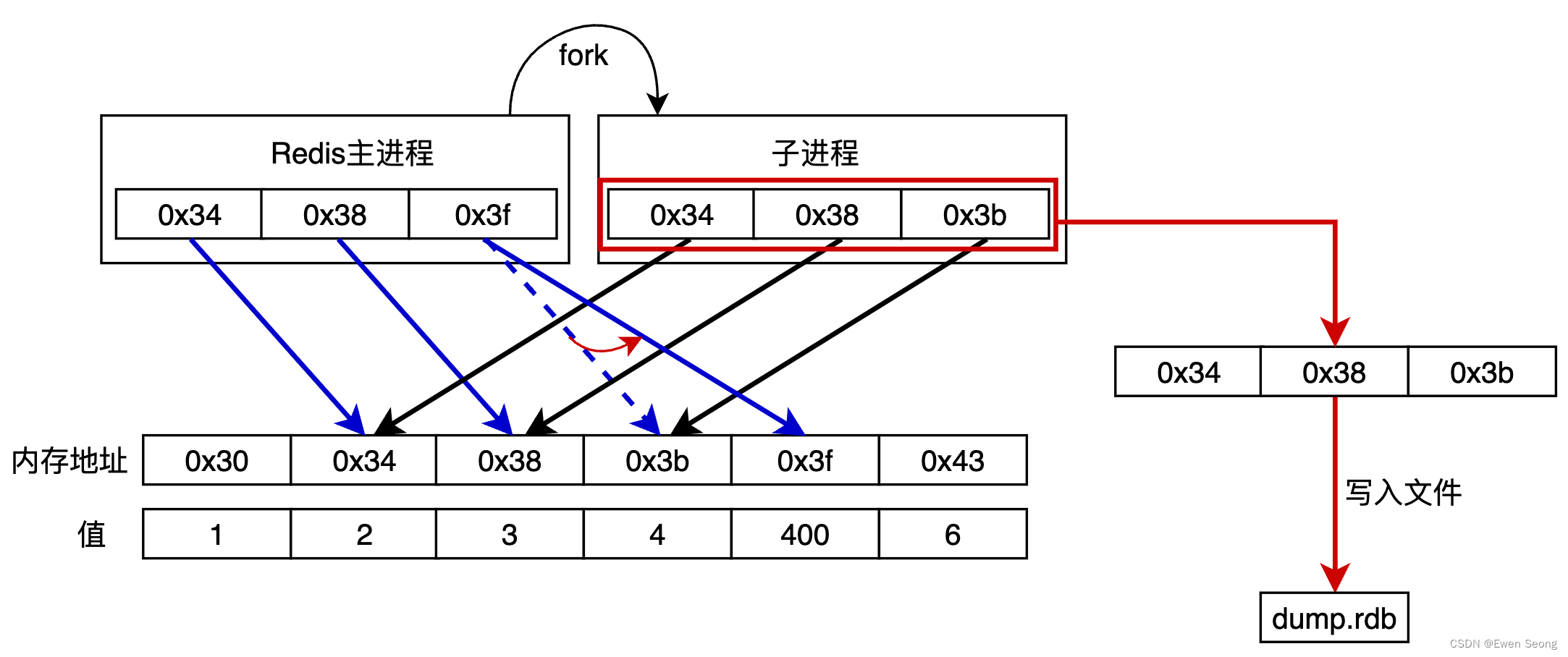
子进程将该部分内存快照(0x34,0x38,0x3b)持久化写入dump.rdb文件,而主进程改动的部分(4->400)未被写入RDB文件,改动部分将在下次RDB时持久化,如果下次RDB前Redis服务被重启,可能存在数据丢失的风险。
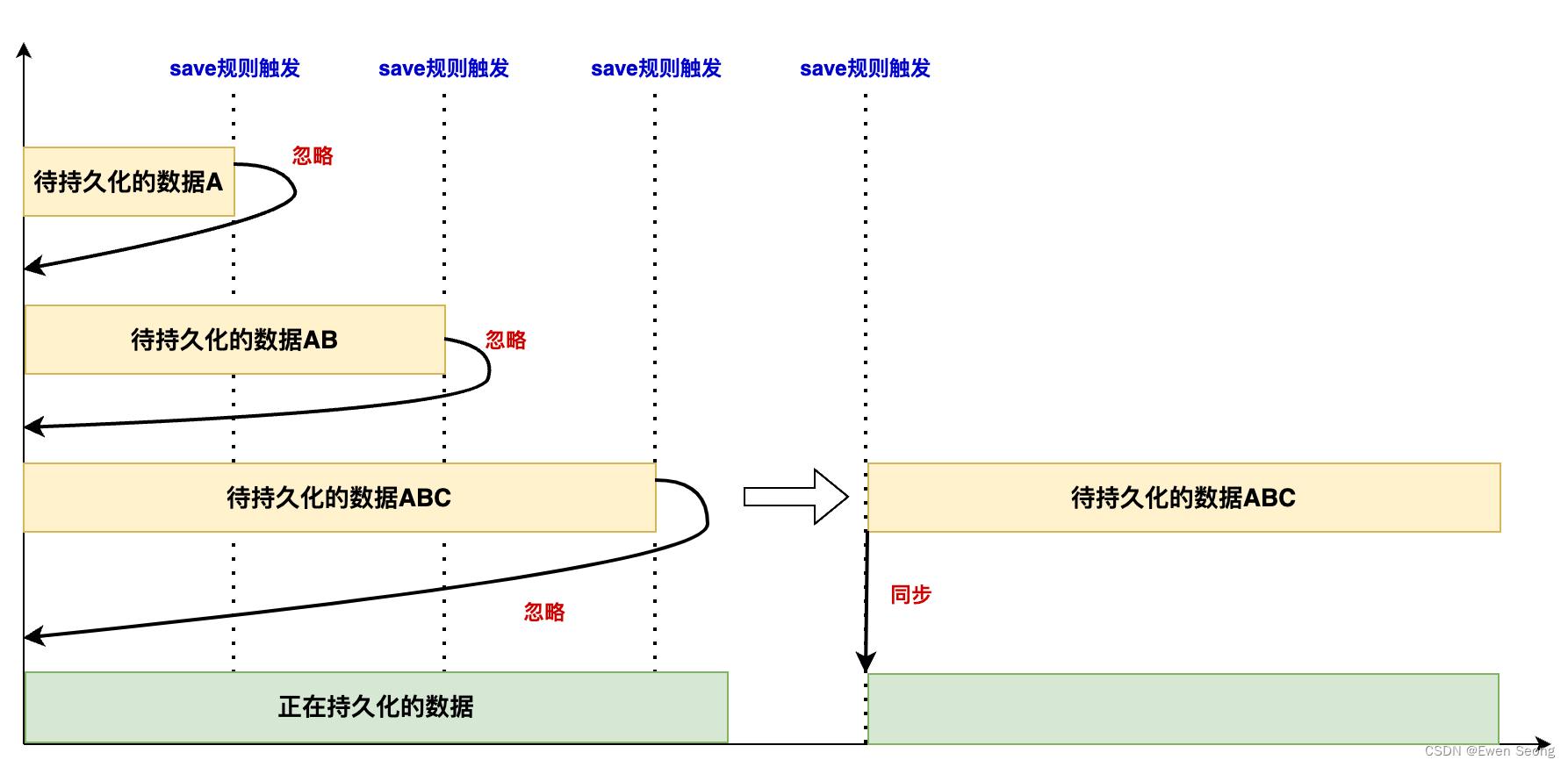
绿色部分表示正在持久化的内存数据(RDB子进程的内存快照),黄色部分表示Redis待持久化的部分(Redis主进程修改的部分)。如果快照数据较大,持久化时间较长,待持久化的数据积累越多,此时Redis重启会丢失大量的数据。因此,为保障数据的可靠性,RDB一般与AOF结合使用。
2.AOF
一般而言,POSIX 标准的 I/O 库,因直接使用内核缓冲区(涉及用户态和内核态的来回切换),适合小文件的读写;而封装的C语言标准IO库,使用用户态缓存区(无需切换内核形态),更适合大文件的读写。AOF据此将内核缓冲区和用户缓冲区分别用于AOF持久化和重写AOF持久化文件。下文仅用缓存区指代,不再区分。
与RDB全量同步不同,AOF(Append Only File只追加文件), 向文件中增量追加变化(类似mysql的binlog),AOF的流程如下所示:
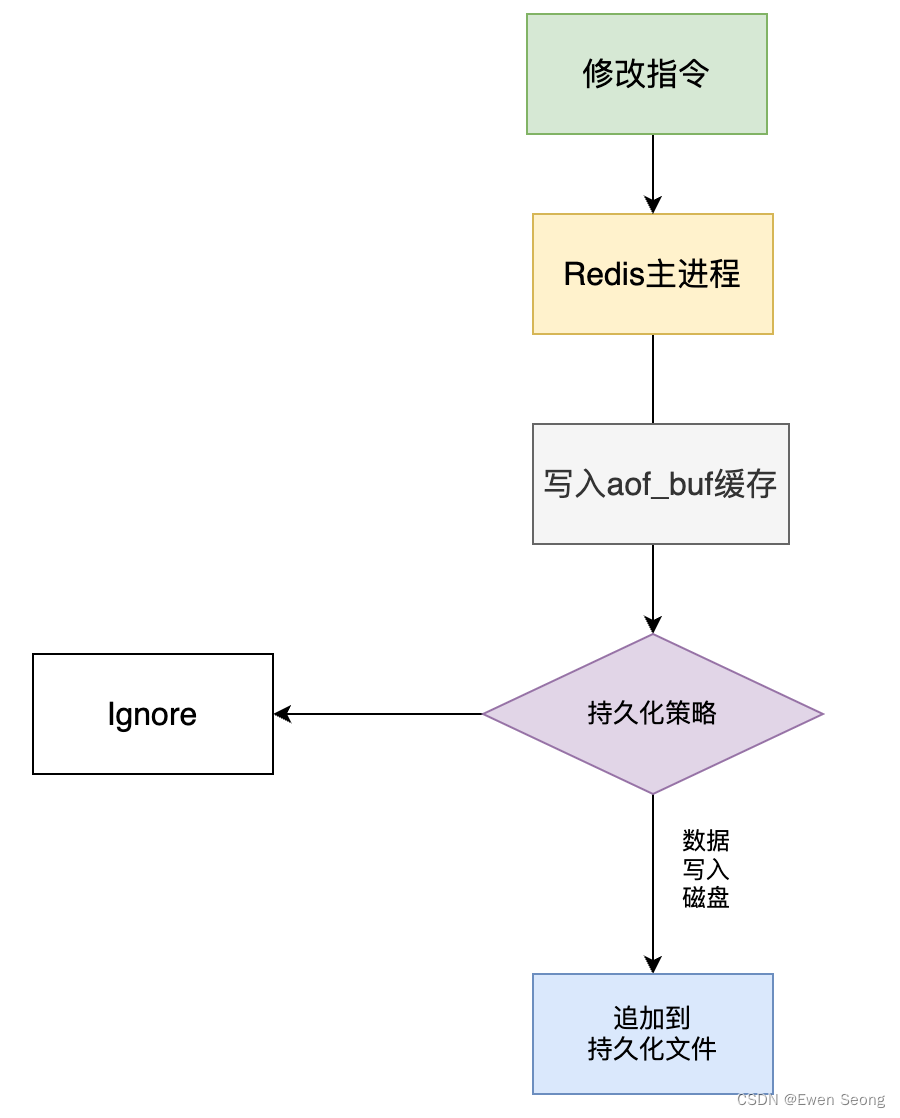
AOF持久化可以分为以下两个部分。
(1) 将数据写入缓存区
当Redis主线程完成内存修改后,将修改数据写入到缓存区;这部分也会占据主线程的时间。
(2) 将缓存刷入硬盘
当Redis主线程将数据写入缓存区后,根据配置的持久化策略确定是否调用 flushAppendOnlyFile方法将缓存数据刷入硬盘。之前提到的aof的配置项appendfsync表示持久化策略,有三个取值:always—每次修改都进行持久化(立即调用);everysec—每秒持久化一次(每秒调用一次);no不主动持久化(不调用),由系统决定。
数据刷入磁盘后,生成一个AOF文件,可通过如下配置配置文件名称:
#开启AOF, 默认是no关闭状态
appendonly yes#配置aof的文件名
appendfilename "appendonly.aof"# aof持久化策略: everysec表示每秒持久化一次, always每次修改都进行持久化
appendfsync everysec
当RDB关闭,而AOF开启:重启Redis时,redis会根据AOF的持久化文件(appendonly.aof)恢复内存数据。
当RDB和AOF都开启时:优先使用AOF持久化文件恢复数据;如果AOF文件不存在或者损坏,再尝试使用RDB持久化文件恢复数据。
rewrite
每个操作都会记录在appendonly.aof文件中,会导致文件变大且存放很多无意义的中间操作。
traffic:0>set key1 value1
"OK"
traffic:0>set key1 value2
"OK"
traffic:0>del key1
"1"
Redis经理上述新增、修改和删除key1键后,内存不变化,但是AOF文件内容如下所示:
*2
$6
SELECT
$1
0
*3
$3
set
$4
key1
$6
value1
*3
$3
set
$4
key1
$6
value2
*2
$3
del
$4
key1
为解决该问题,Redis引入rewrite重写机制。
rewrite可以通过redis.conf配置文件的auto-aof-rewrite-percentage和auto-aof-rewrite-min-size确定触发频率:
#需要二者同时满足,才会触发
# aof文件增长达到上一次的100%时才会触发
auto-aof-rewrite-percentage 100
# aof需要大于64M才会触发
auto-aof-rewrite-min-size 64mb
触发rewrite后,流程如下所示:
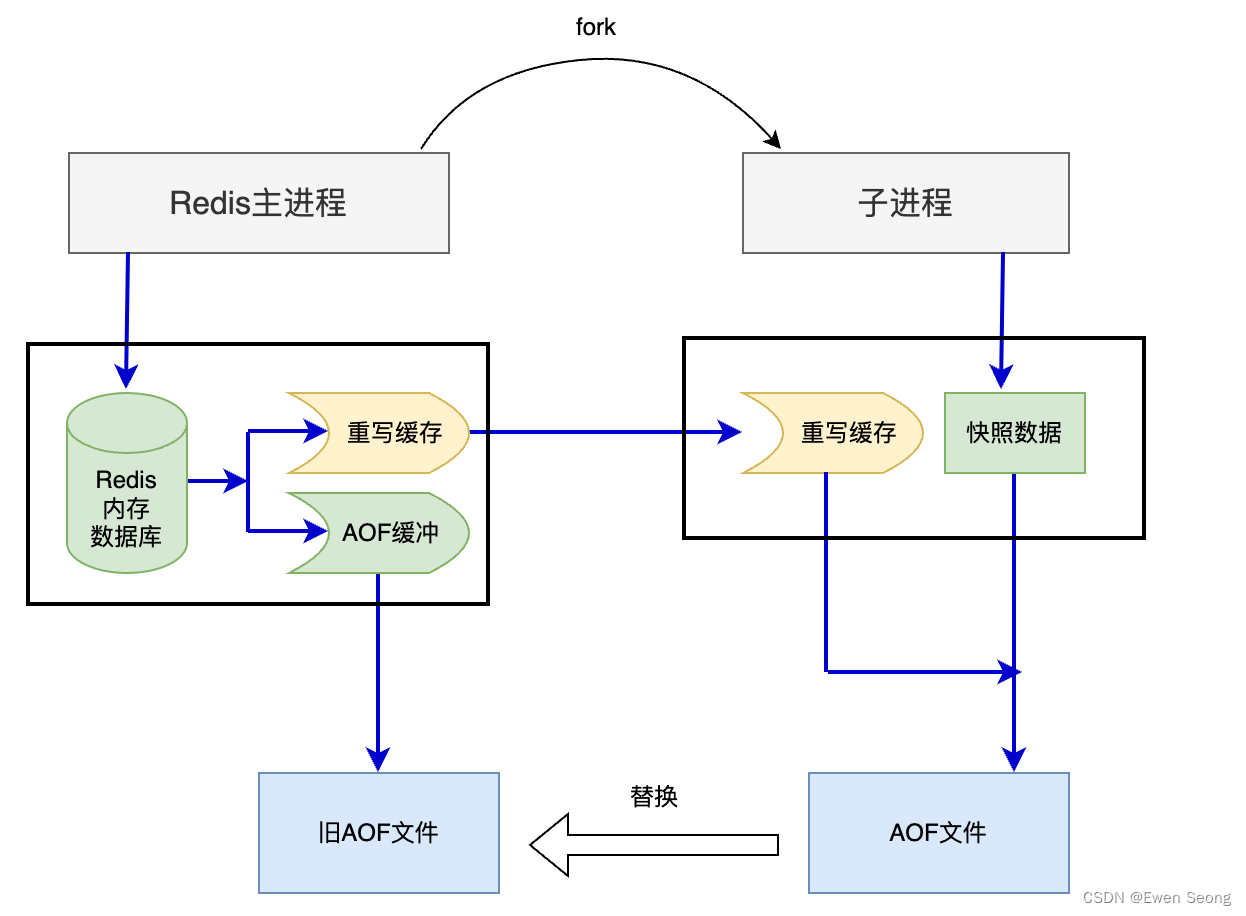
[1] 主进程fork出子进程(阻塞),然后继续工作;
[2] 与RDB相同,子进程此刻拥有与主进程的全部内存信息,子进程将该部分信息写入临时AOF文件;
[3] 在此期间,主进程会接收数据库操作指令并修改内存数据库,此时,Redis主进程会将该部分指令数据写入重写缓存区和AOF缓冲区(写入AOF文件);
[4] 当子进程将快照写完时,重写缓存区中累积的数据写入临时AOF;
[5] 使用临时AOF替换原AOF文件;
这里有个细节需要注意:子进程将重新缓存数据写入到临时AOF文件之前,需要先向主进程发送消息:“暂时不要发数据给我”,此过程中累积的消息后续会直接更新到AOF文件中。
这篇关于Redis系列-2 Redis持久化机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







