本文主要是介绍MVC和DDD的贫血和充血模型对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 架构区别
- MVC三层架构
- DDD四层架构
- 贫血模型
- 代码示例
- 充血模型
- 代码示例
架构区别
MVC三层架构
MVC三层架构是软件工程中的一种设计模式,它将软件系统分为 模型(Model)、视图(View)和控制器(Controller) 三个核心部分。具体如下:
- 模型(Model):模型代表的是数据和业务逻辑,它负责管理应用程序的数据和定义操作数据的规则。模型直接与数据库进行交互,处理如数据库查询、更新等操作,并返回结果给视图或控制器。
- 视图(View):视图是用户界面元素,它负责显示模型层提供的数据。视图通常不包含程序的逻辑,而是专注于数据的展示和用户交互的界面。一个模型可以对应多个视图,即相同的数据可以以不同的方式展现给用户。
- 控制器(Controller):控制器是模型与视图之间的协调者,它处理用户的输入和系统的事件,执行相应的业务逻辑,并选择相应的视图来展示模型处理后的数据。控制器确保模型和视图之间的同步和数据的一致性。
DDD四层架构
DDD的四层架构旨在通过明确的层次划分来组织代码结构,促进模块化、可维护性和可扩展性。尽管DDD本身并未严格定义必须使用四层架构,不过在实践中,开发者常参考以下四层来构建DDD应用:
-
表示层(Presentation Layer):
这一层负责用户界面的展示和用户交互。它包括Web页面、移动应用的界面或是命令行界面等。此层的主要职责是接收用户的输入并展示处理结果,同时调用领域层的服务来完成业务操作。 -
应用层(Application Layer):
应用层是领域层和表示层之间的桥梁,它负责协调领域对象执行业务操作,处理事务边界,以及执行任何与具体技术框架相关的任务(如安全、权限控制等)。应用层中的服务通常很薄,主要封装领域逻辑的入口点,而不包含业务规则。 -
领域层(Domain Layer):
DDD的核心所在,封装了复杂的业务规则和逻辑。这一层包含了领域模型、实体(Entities)、值对象(Value Objects)、聚合(Aggregates)、领域事件(Domain Events)等概念。领域层的设计关注于反映业务领域的本质,使得业务逻辑清晰、可维护。 -
基础设施层(Infrastructure Layer):
提供底层技术支持,如数据库访问、消息队列、外部服务调用等。这一层实现了技术细节,如ORM映射、数据库访问接口、日志记录等,为上层提供必要的服务,同时也隐藏了技术实现细节,使得领域层和应用层能更加专注于业务逻辑。
贫血模型
在MVC(Model-View-Controller)架构中,模型(Model)负责管理应用程序的数据和业务逻辑。如果模型的实现过于简单,仅仅作为数据的容器,而没有包含足够的业务逻辑,就可能导致所谓的“贫血模型”。
在这种情况下,控制器(Controller)可能会变得过于臃肿,因为它需要处理大量的业务逻辑,而这些逻辑本应该由模型来管理。这种设计问题被称为“贫血模型,膨胀控制器”(Anemic Model, Bloated Controller),其中“贫血模型”指的是缺乏业务逻辑的模型,而“膨胀控制器”则指代承担了过多职责的控制器。
MVC架构中的贫血模型会降低代码的可维护性,将导致以下问题:
- 业务逻辑分散:由于业务逻辑主要在控制器中实现,而不是封装在模型中,这导致业务逻辑分散在多个控制器中。当需要修改或扩展业务逻辑时,开发者需要找到并修改所有相关的控制器,这使得维护变得更加困难和耗时。
- 代码复用性差:模型层如果只是简单的数据容器,而没有包含业务逻辑,那么这些模型就很难在不同的上下文中重用。每个新的应用场景都需要重新编写控制器逻辑,这增加了开发的工作量,并且可能导致重复代码的产生。
- 违反单一职责原则:理想情况下,每个类应该只有一个引起变化的原因。但在贫血模型中,控制器既处理用户输入和交互,又处理业务逻辑,这违反了单一职责原则。当一个类承担了过多的职责时,它变得难以理解和修改。
代码示例
下面是一个示例,展示了一个基本的银行账户(BankAccount)领域对象,包含了存款(deposit)和取款(withdraw)的业务逻辑:
public class BankAccountService {public void deposit(BankAccount account, double amount) {if (amount <= 0) {throw new IllegalArgumentException("Deposit amount must be positive.");}double newBalance = account.getBalance() + amount;account.setBalance(newBalance);}public void withdraw(BankAccount account, double amount) {if (amount <= 0) {throw new IllegalArgumentException("Withdrawal amount must be positive.");}if (account.getBalance() < amount) {throw new IllegalStateException("Insufficient funds.");}double newBalance = account.getBalance() - amount;account.setBalance(newBalance);}
}
充血模型
在(DDD)中,充血模型(Rich Model)是一种设计哲学,它强调将业务逻辑和规则尽可能地集中在领域模型中,而不是分散在服务层或控制器中。这种设计方法与贫血模型(Anemic Model)形成对比,后者的领域模型通常只包含数据结构,而业务逻辑则被放置在其他地方,如控制器或服务层。
充血模型的特点包括:
- 丰富的领域逻辑:领域模型包含与该领域相关的所有业务逻辑和行为,这使得模型具有丰富的功能和表现力。
- 封装性:通过将业务逻辑封装在领域模型中,这些逻辑对外部是不可见的,只能通过模型提供的接口进行交互。
- 领域专家的语言:领域模型使用领域专家的语言来表达概念和规则,这有助于确保软件设计与业务需求紧密匹配。
- 可维护性和可扩展性:由于业务逻辑集中在领域模型中,当业务规则发生变化时,只需要修改相应的模型,而不需要在整个应用程序中寻找和修改逻辑。
- 高度的内聚性:领域模型是围绕业务概念构建的,这使得相关的业务逻辑和数据高度内聚
充血模型的优点在于它能够更好地反映和处理复杂的业务需求,同时提高了代码的可读性、可维护性和可测试性。然而,它也可能需要更多的设计和抽象工作,特别是在项目的早期阶段。
代码示例
下面是一个简化的充血模型示例,展示了一个基本的银行账户(BankAccount)领域对象,包含了存款(deposit)和取款(withdraw)的业务逻辑:
// 银行账户领域对象 - 充血模型示例
public class BankAccount {private String accountId;private double balance;// 构造函数public BankAccount(String accountId, double initialBalance) {if (initialBalance < 0) {throw new IllegalArgumentException("Initial balance cannot be negative.");}this.accountId = accountId;this.balance = initialBalance;}// 存款业务逻辑public void deposit(double amount) {if (amount <= 0) {throw new IllegalArgumentException("Deposit amount must be positive.");}addAmountToBalance(amount);}// 取款业务逻辑,包含校验余额public void withdraw(double amount) {if (amount <= 0) {throw new IllegalArgumentException("Withdrawal amount must be positive.");}checkSufficientFunds(amount);subtractAmountFromBalance(amount);}// Getter方法,通常在充血模型中只用于展示,非业务逻辑的一部分public double getBalance() {return balance;}// 增加余额public void addAmountToBalance(double amount){return balance += amount;}// 扣减余额public void subtractAmountFromBalance(double amount){return balance -= amount;}// 检查余额public boolean checkSufficientFunds(double amount){if (balance < amount) {throw new IllegalStateException("Insufficient funds.");}return true;}}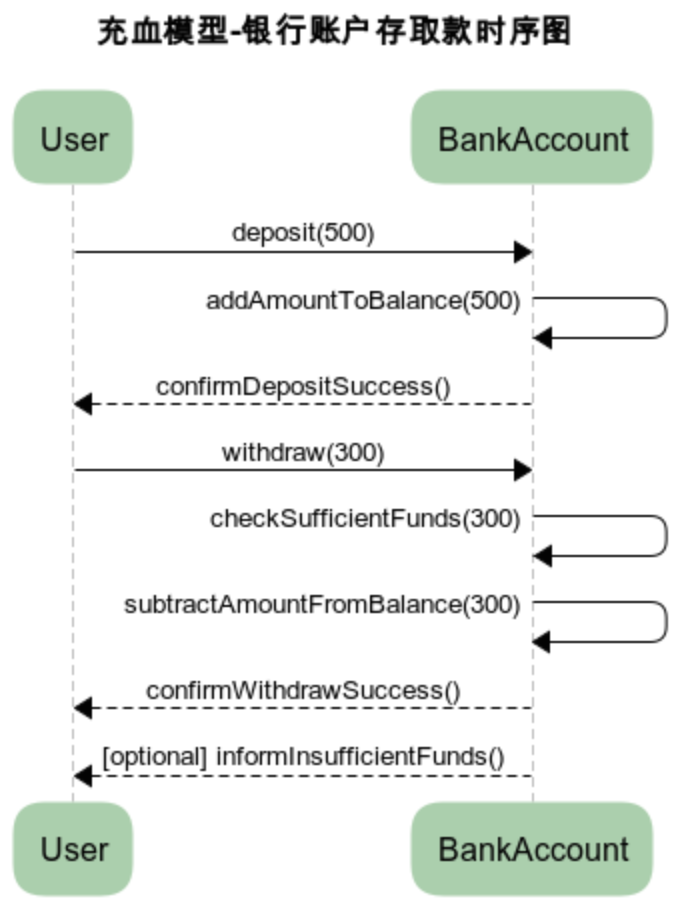
public class Main {public static void main(String[] args) {BankAccount account = new BankAccount("123456", 0);account.deposit(500); try {account.withdraw(300);} catch (IllegalStateException e) {System.out.println(e.getMessage());}}
}
BankAccount 类不仅包含了账户的属性(如 accountId 和 balance),还直接实现了业务操作(如存款和取款),并包含了相关的业务规则检查(比如不能存取负数金额,取款不能超过余额)。这就是充血模型的核心思想,即领域对象本身是富含业务逻辑的。
这篇关于MVC和DDD的贫血和充血模型对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




