本文主要是介绍STM32的疑难杂症之一:Printf的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、Printf简介
二、Printf和串口
一、Printf简介
Printf是一个标准的C库API,用来打印信息显示的。
Printf的底层输出调用,在windows环境下是fputc函数,在GNUC环境下是__io_putchar函数。
Printf主要做两件事:第一件是将参数字符串以及可变参数进行解析,格式化成 一串字符串。第二件事就是将格式化的字符串一个字节一个字节的输出出去(至于以什么样的方式输出那就得看底层的实现了,比如有OS的情况下就是输出在命令行下的)。
二、Printf和串口
在嵌入式设备中一般有两种调试方法,一种是硬件调试无需软件干预(利用厂商提供的仿真器和应用软件),另一种是软件调试(利用串口发送调试)。一般在系统初始阶段串口无法使用的情况下都是用的硬件进行调试但是这种方式不太灵活,限制很多,能用软件调试尽量都用软件,这种方式比较灵活。
串口设备本身只能将我们写入数据寄存器的数据发送出来,无法支持更多的功能。比如将存放十进制的数据的变量转换成字符形式再发出去,这样我们人才识别。而标准库的printf就是实现了这些功能。
printf的第一件事主要是软件实现,这个已经由C标准实现了我们不用管;而第二件事就是将printf格式化好的字符串输出到那个设备。所以我们只需要将fputc或者__io_putchar函数实现为串口的发送,然后通过USB转串口硬件发送到上位机上,上位机再通过串口助手程序显示出来。代码如下:

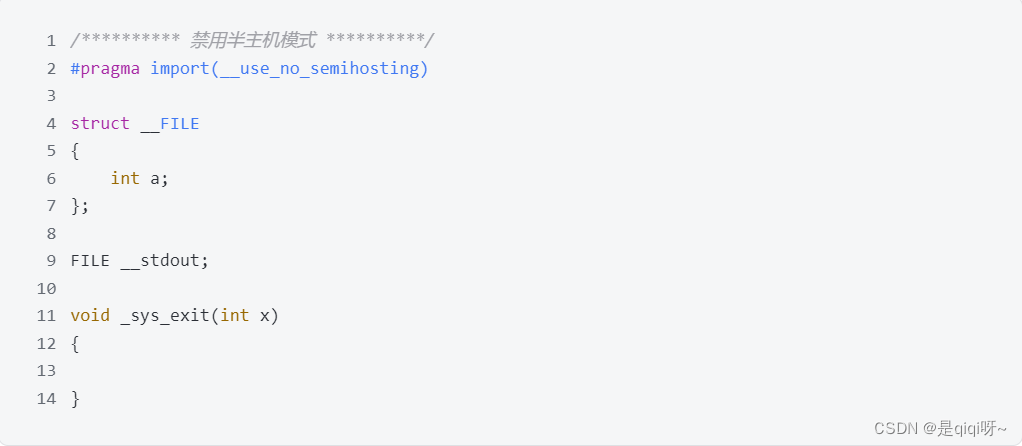
除此之外,我们还要再做一点配置工作—禁用半主机模式,禁用了半主机模式才能使用标准库函数printf()打印信息到串口,在程序中加入以下代码即可。
那么什么是半主机模式?为什么不用它?半主机模式是ARM单片机的一种调试机制,跟串口调试不一样的是,它需要通过仿真器来连接电脑和ARM单片机,并调用相应的指令来实现单片机向电脑显示器打印信息(或者从电脑键盘读取输入)。简而言之,这种方法比串口调试更复杂(需要进行更多的配置操作),也更不灵活(一定要用仿真器)。
上面的配置似乎有点麻烦,要加入这么一堆难懂的代码,难道没有更简便点的方法吗?有,但不推荐。
方法是使用微库(MicroLIB),只要在Keil的“Options for Target -> Target ->Use MicroLIB”上打勾,即可使用串口打印(fputc()函数还是要实现,但上述的禁用半主机代码不用加)。
微库是区别于C标准库的另一个库,当使用微库时,就默认关闭了半主机模式,也就不用添加上面的代码。这样虽然方便,但个人建议能不用就不用,原因:
第一,微库是为小内存嵌入式设备而设计的,使用它可以减少代码所占空间,但对现在STM32等单片机来说,内存一般都够用,微库并非必需。
第二,微库相对于C标准库而言,支持的功能更少,主要体现在对操作系统的支持上。总的来说,标准的东西总是相对更可靠,所以为了不必要的掉坑,还是用C标准库,不用微库。
![]()
这篇关于STM32的疑难杂症之一:Printf的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





