本文主要是介绍msmpi 高性能并行计算 移植并行细胞自动机报错,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
报错情况如图
代码来源
元胞自动机生命游戏C语言并行实现 – OmegaXYZ
稍微修改,因为相对路径在 msmpi 10.1.1 中失效
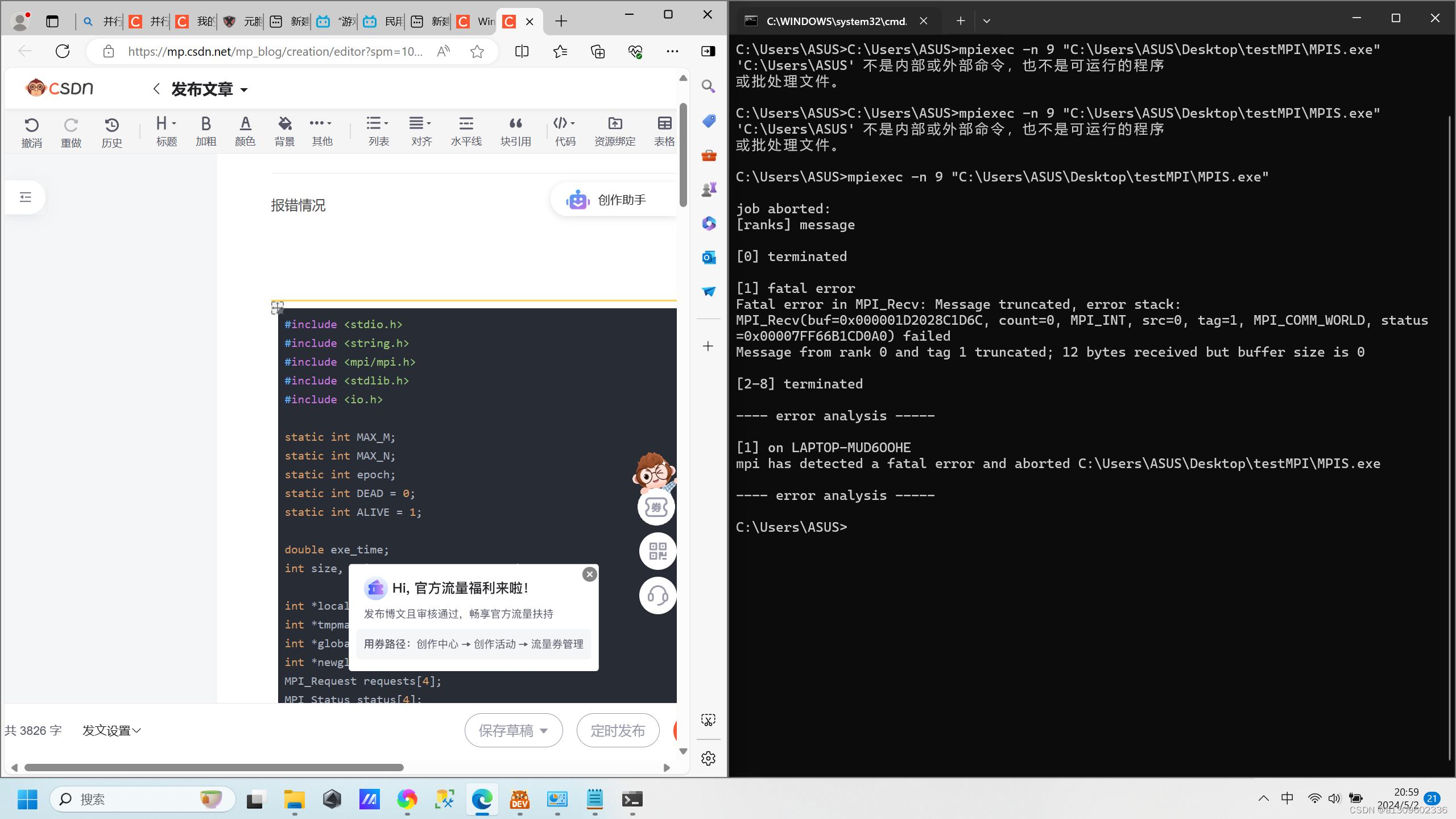
Microsoft Windows [版本 10.0.22000.2538]
(c) Microsoft Corporation。保留所有权利。C:\Users\ASUS>mpiexec -n 9 "C:\Users\ASUS\Desktop\testMPI\MPIS.exe"job aborted:
[ranks] message[0] terminated[1] fatal error
Fatal error in MPI_Recv: Message truncated, error stack:
MPI_Recv(buf=0x000002F82B501D6C, count=0, MPI_INT, src=0, tag=1, MPI_COMM_WORLD, status=0x00007FF66B1CD0A0) failed
Message from rank 0 and tag 1 truncated; 12 bytes received but buffer size is 0[2-8] terminated---- error analysis -----[1] on LAPTOP-MUD6OOHE
mpi has detected a fatal error and aborted C:\Users\ASUS\Desktop\testMPI\MPIS.exe---- error analysis -----C:\Users\ASUS>
windows msmpi 移植 linux 代码如下
#include <stdio.h>
#include <string.h>
#include <mpi/mpi.h>
#include <stdlib.h>
#include <io.h>
//https://www.omegaxyz.com/2022/01/26/c_game_of_life/?utm_source=tuicool&utm_medium=referral
static int MAX_M;
static int MAX_N;
static int epoch;
static int DEAD = 0;
static int ALIVE = 1;double exe_time;
int size, myid, s, ver, row, col, dir;int *local_matrix = NULL;
int *tmpmatrix = NULL;
int *global_matrix = NULL;
int *newglobal_matrix = NULL;
MPI_Request requests[4];
MPI_Status status[4];FILE * matrix;void display(int *local_matrix) {int i, j;printf("%10c", ' ');printf("$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n");for (i = 0; i < MAX_M; i++) {printf("\n%10c", ' ');for (j = 0; j < MAX_N; j++)if (local_matrix[i * MAX_N + j] == ALIVE)printf("+");elseprintf("-");}printf("\n%10c\n", ' ');
}int adj8(int neighbor, int row, int col) {int res;if (neighbor == 2) {return local_matrix[row * MAX_N + col];} else if (neighbor == 3) {return ALIVE;} else {return DEAD;}
}int main(int argc, char *argv[]) {MPI_Init(&argc, &argv);MPI_Comm_size(MPI_COMM_WORLD, &size);MPI_Comm_rank(MPI_COMM_WORLD, &myid);ver = MAX_M / size;// epoch= atoi(argv[1]);
// MAX_M= atoi(argv[2]);
// MAX_N= atoi(argv[3]);epoch = 100;MAX_M = 3;MAX_N = 3;local_matrix = (int*)malloc(sizeof(int) * (ver + 2) * MAX_N);tmpmatrix = (int*)malloc(sizeof(int) * (ver + 2) * MAX_N);for (row = 0; row < ver + 2; row++) {for (col = 0; col < MAX_N; col++) {local_matrix[row * MAX_N + col] = DEAD;tmpmatrix[row * MAX_N + col] = DEAD;}}//Initializationif (myid == 0) {int i;global_matrix = (int*)malloc(sizeof(int) * MAX_M * MAX_N);newglobal_matrix = (int*)malloc(sizeof(int) * MAX_M * MAX_N);// windows 的 msmpi 相对路径不能读取,只能用绝对路径,但是可以通过获取当前文件所在文件夹来拼出来绝对路径FILE* fp;fp = fopen("C:\\Users\\ASUS\\Desktop\\testMPI\\matrixv6.txt", "w");fprintf(fp, "hello\n");fclose(fp);char path[PATH_MAX + 100]; //PATH_MAX is defined in limits.hgetcwd(path, sizeof(path)); // io.h 获取当前文件夹位置printf("%s\n", path);strcat(path, "\\matrixv7.txt"); // 在当前文件夹位置加入数据printf("%s\n", path);fp = fopen(path, "w");for (int i = 0; i < MAX_M; i++) {for (int j = 0; j < MAX_N; j++) {fprintf(fp, "%d ", 1);}fprintf(fp, "\n");}fclose(fp);if ((matrix = fopen(path, "r")) == NULL) {printf("the file can not open.");return -1;}for (row = 0; row < MAX_M; row++) {for (col = 0; col < MAX_N; col++) {fscanf(matrix, "%d ", &global_matrix[row * MAX_N + col]);}fscanf(matrix, "\n");}memcpy(&local_matrix[MAX_N], &global_matrix[0], ver * MAX_N * sizeof(int));for (dir = 1; dir < size; dir++) {MPI_Send(&global_matrix[dir * ver * MAX_N], ver * MAX_N, MPI_INT, dir, 1, MPI_COMM_WORLD);}display(global_matrix);} else {//For each processor, there is a local matrix.MPI_Recv(&local_matrix[MAX_N], ver * MAX_N, MPI_INT, 0, 1, MPI_COMM_WORLD, status);}exe_time = -MPI_Wtime();for (int count = 0; count < epoch; count++) {int req_id = 0;if (myid == 0) {MPI_Isend(&local_matrix[(ver)*MAX_N], MAX_N, MPI_INT, myid + 1, 1, MPI_COMM_WORLD, &requests[req_id++]);MPI_Irecv(&local_matrix[(ver + 1)*MAX_N], MAX_N, MPI_INT, myid + 1, 1, MPI_COMM_WORLD, &requests[req_id++]);printf("\n");display(local_matrix);} else {MPI_Irecv(local_matrix, MAX_N, MPI_INT, myid - 1, 1, MPI_COMM_WORLD, &requests[req_id++]);MPI_Isend(&local_matrix[(ver)*MAX_N], MAX_N, MPI_INT, myid + 1, 1, MPI_COMM_WORLD, &requests[req_id++]);MPI_Irecv(&local_matrix[(ver + 1)*MAX_N], MAX_N, MPI_INT, myid + 1, 1, MPI_COMM_WORLD, &requests[req_id++]);MPI_Isend(&local_matrix[MAX_N], MAX_N, MPI_INT, myid - 1, 1, MPI_COMM_WORLD, &requests[req_id++]);}MPI_Waitall(req_id, requests, status);for (row = 1; row < ver + 1; row += 1) {for (col = 0; col < MAX_N; col++) {int neighbor = 0, c, r;for (r = row - 1; r <= row + 1; r++)for (c = col - 1; c <= col + 1; c++) {if (c < 0 || c >= MAX_N) continue;if (local_matrix[r * MAX_N + c] == ALIVE) neighbor++;}if (local_matrix[row * MAX_N + col] == ALIVE)neighbor--;tmpmatrix[row * MAX_N + col] = adj8(neighbor, row, col);}}for (row = 1; row < ver + 1; row += 1) {for (col = 0; col < MAX_N; col++) {local_matrix[row * MAX_N + col] = tmpmatrix[row * MAX_N + col];}}}if (myid == 0) {exe_time += MPI_Wtime();printf("Time: %lf \n", exe_time);memcpy(global_matrix, &local_matrix[MAX_N], ver * MAX_N * sizeof(int));for (dir = 1; dir < size; dir++) {MPI_Recv(&global_matrix[dir * ver * MAX_N], ver * MAX_N, MPI_INT, dir, 1, MPI_COMM_WORLD, status);}printf("Last Status:\n");display(global_matrix);} else {MPI_Send(&local_matrix[MAX_N], ver * MAX_N, MPI_INT, 0, 1, MPI_COMM_WORLD);}MPI_Finalize();return 0;
}这篇关于msmpi 高性能并行计算 移植并行细胞自动机报错的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






