本文主要是介绍区块链 | IPFS:CID,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🦊原文:Anatomy of a CID
🦊写在前面:本文属于搬运博客,自己留存学习。
1 CID
在分布式网络中与其他节点交换数据时,我们依赖于内容寻址(而不是中心化网络的位置寻址)来安全地定位和识别数据。
CID 规范起源于 IPFS,现在以 Multiformats 形式存在,并支持包括 IPFS、IPLD、libp2p 和 Filecoin 在内的系统。尽管我们在教程中会分享一些 IPFS 的例子,但本教程实际上是关于 CID 自身的结构,它作为这些分布式信息系统的核心标识符,用于引用内容。
内容标识符(CID)是一种自描述的内容寻址标识符。
自描述是指,标识符能够自行表达其含义或者数据类型。例如 HTTP 中的 URL就是一个自描述的标识符,因为它包含了指向资源的信息(如文件路径),并且基于协议和结构,用户和系统可以理解其含义。
CID 不指示内容存储的位置,而是基于内容本身形成一种地址。CID 的长度取决于内容的哈希,而不是内容本身的大小。由于在 IPFS 中大多数内容都使用 sha2-256 进行哈希处理,因此大多数 CID 都具有相同的大小,即 256 位或称 32 字节。
例如,如果我们在 IPFS 网络中存储 土豚 的图像,它的 CID 将如下所示:
QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
访问方式:https://ipfs.io/ipfs/QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
创建 CID 的第一步是使用 加密算法 转换输入的数据。具体来说,是将任意大小的输入映射到固定大小的输出。如下图所示:

这种转换称为 加密哈希摘要(cryptographic hash digest)或简称为 哈希。
个人理解:不管是文本、图片还是视频,它们在计算机中都是以二进制的形式进行存储的,即一个 01 字符串。而哈希函数要做的事,就是将不同文件不同长度的 01 字符串转换为固定长度的 01 字符串。
使用的 加密算法 必须生成具有以下特征的哈希:
- 确定性:对于任何给定的输入数据,加密算法必须始终产生相同的输出哈希,确保一致性。
- 抗碰撞性:即使输入数据发生微小变化,也应导致完全不同的哈希值,以保证数据的唯一性。
- 不可逆性:从哈希值应当无法反推出原始数据,确保数据的隐私和安全。
- 唯一标识:每份文件都应该有一个独特的哈希值,确保数据的不可篡改性和可追溯性。
当我们使用内容地址去获取数据时,我们可以保证看到数据的预期版本。这与中心化网络上的位置寻址有很大的不同,在中心化网络中,给定地址(URL)处的内容可能会随时间变化。
说明:在去中心化网络中,我们使用 CID 去获取数据;在中心化网络中,我们使用 URL 去获取数据。
哈希并不是 IPFS 所独有的,还有许多其他的哈希算法,如 sha2-256、blake2b、sha3-256 和 sha3-512,以及不再安全的 sha1 和 md5 等。IPFS 默认使用 sha2-256,尽管 CID 支持几乎任何强大的加密哈希算法。
2 CIDv0
随着时间的推移,某些哈希算法可能被证明对于 IPFS 和其他分布式信息系统的内容寻址是不够安全的。
因此,我们的系统需要支持多种加密算法,同时我们应该能够知道是哪种算法被用来生成特定内容的哈希值。为了支持多种哈希算法,我们使用了多重哈希。
2.1 多重哈希
多重哈希(multihash)是一种自描述的哈希,它本身包含元数据,这些元数据描述了其长度以及生成它的加密算法。
多重哈希遵循 TLV 模式,即 type — length — value。也就是说,原始哈希 value 前面附带着所使用的哈希算法的类型 type 和哈希的长度 length。如下图所示:

type:用于生成哈希的加密算法的标识符。例如,sha2-256 的标识符是 18,即十六进制的 12;length:哈希的实际长度。使用 sha2-256 时,它将是 256 位,相当于 32 字节;value:实际的哈希值;
通过查看 multicodec 表,可以获取各个哈希算法对应的标识符。
2.2 基数编码
为了将 CID 表示为紧凑的字符串而不是纯二进制(一串 0 和 1),我们可以使用基数编码(base encoding)。
在 IPFS 最初创建时,它使用 base58btc 编码来生成看起来像这样的 CID:
QmY7Yh4UquoXHLPFo2XbhXkhBvFoPwmQUSa92pxnxjQuPU
多重哈希和 base58btc 编码构成了第一版 CID,即如今所说的版本 CIDv0,以 Qm 开头的序列仍然是它的一个显著特征。
然而,随着时间的推移,人们开始对多重哈希是否足够的问题产生了疑问:
- 我们如何知道使用了什么方法来编码数据?
- 我们如何知道使用了什么方法来创建 CID 的字符串表示?我们是否会一直使用
base58btc?
为了应对这些担忧,有必要对 CID 的下一版本进行改进。
个人理解:在本文中,“基数编码” 是指将二进制转换为可读的字符串,“编码” 是指将文件转换为二进制。
3 CIDv1
CIDv0 使用多重哈希来支持多种哈希函数。这允许我们针对特定内容创建哈希值,且可以选择不同的哈希算法进行处理。有了这一机制,我们日后便能通过这些哈希值来辨识内容。
3.1 多码前缀
但当我们试图阅读数据本身时,如何知道采用了哪种编码方式?数据可能是由 CBOR、Protobuf 或纯 JSON 等编码的。为了解决这个问题,CIDv1 引入了另一个前缀,用以唯一标识所使用的编码方法。
个人理解:哈希是将任意长度的 01 字符串转换为固定长度的 01 字符串,而编码是将非 01 字符串的数据本身转换为 01 字符串。
多码前缀(multicodec prefix)指示了数据使用了哪种编码方式。如下图所示:

多码支持许多不同类型的编码,每种编码都有自己的简短码缀,可以在 complete 表中查看。
在上述示例中,我们了解到使用 dag-pb 编码的数据是如何被表示在 CID 中的。其中,dag-pb 是众多 IPLD 编码格式中的一种。由于 IPFS 总是选择一种 IPLD 格式来处理其数据,因此 IPFS 生成的 CID 中的多码前缀必然对应于一个 IPLD 编码。
IPLD 是指 Inter Planetary Linked Data,星际链接数据
需要指出的是,多码不仅仅是为了 IPFS 和 IPLD 而设计的,它还是 Multiformats 项目的一部分。这个项目最初是从 IPFS 分离出来的,现在它支持包括我们正在学习的 CID 规范在内的许多其他项目和协议。
3.2 版本前缀
添加多码前缀后,CIDv1 包含以下字段:
<multicodec><multihash-algorithm><multihash-length><multihash-hash>
那么我们如何区分不同版本的 CID 呢?答:版本前缀。如下图所示:

现在我们的 CID 看起来像这样:
<cid-version><multicodec><multihash>
其中,<cid-version> 代表 CID 的版本是 0 还是 1 。
注意:
<multihash>包含了<multihash-algorithm><multihash-length><multihash-hash>。特别地,只有 CIDv1 具有<cid-version>,而 CIDv0 只有<multihash>。
3.3 多基前缀
CIDv1 以二进制的形式为我们提供了以下信息:
<cid-version><multicodec><multihash>
由于二进制 CID 对人类不太友好,因此我们可以将这些二进制 CID 表示为字符串形式,即把二进制数据表示为字符串。
采用的就是前文提到的基数编码技术。
示例:
bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi
在二进制和字符串形式之间转换数据需要进行基数编码,因此在处理字符串格式的 CID 时,我们需要知道应用于二进制数据的基数编码的类型。
在 CIDv0 中,哈希总是使用 base58btc 进行编码。因此我们可以直接假设 CIDv0 哈希是由 base58btc 编码的。然而,由于环境限制(例如 DNS 名称),我们需要支持其他基数编码的能力。你猜对了,我们可以添加另一个前缀!
多基数前缀(multibase prefix),用于表示 CID 在进行格式转换时使用的基数编码,仅用于 CID 的字符串形式:
Binary:
<cid-version><multicodec><multihash>
String:
<base>base(<cid-version><multicodec><multihash>)
其中,base( ) 应该是指使用某种基数编码方法,对括号中的内容进行基数编码。
让我们来分析两个 CID 的字符串形式示例:
CIDv0:
QmbWqxBEKC3P8tqsKc98xmWNzrzDtRLMiMPL8wBuTGsMnR
CIDv1:
bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi
易知第一个 CID 是一个 CIDv0,因为它以 Qm 开头。所有以 Qm 开头的哈希,都可以解释为采用的是 base58btc 基数编码。第二个示例以 b 开头,这是 base32 的基数编码前缀标识符,大多数 IPFS 实现默认使用 base32。
4 One hash, multiple CID versions
我们可以将任何的 IPFS CID 粘贴到 CID Inspector 中,以可视化其所有前缀及其代表的内容。
4.1 示例 1:CIDv1
bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi
通过 CID Inspector 工具查看结果:

我这里只截取了一部分,请自行查看剩余部分。
我们可以看到工具为我们解析了许多部分:
- 人类可读 CID:将 CID 的每个部分分解为人类可以轻松阅读的形式;
- 多基数:基数的标识符,在这个例子中是
b,代表base32; - 多编码:编码的标识符,在这个例子中是
0x70,代表dag-pb,一种 IPLD 格式; - 多哈希:将多哈希分解为所使用的哈希算法、哈希的长度、内容哈希本身。
其中,18 是哈希算法 sha2-256 的代码,哈希的长度是 256 位即 32 字节,内容哈希本身是十六进制的摘要。
从 “人类可读 CID” 中,我们可以看到在添加 CIDv1 的前缀之前,内容的原始哈希是:
C3C4733EC8AFFD06CF9E9FF50FFC6BCD2EC85A6170004BB709669C31DE94391A
4.2 示例 2:CIDv0
QmbWqxBEKC3P8tqsKc98xmWNzrzDtRLMiMPL8wBuTGsMnR
通过 CID Inspector 工具查看结果:
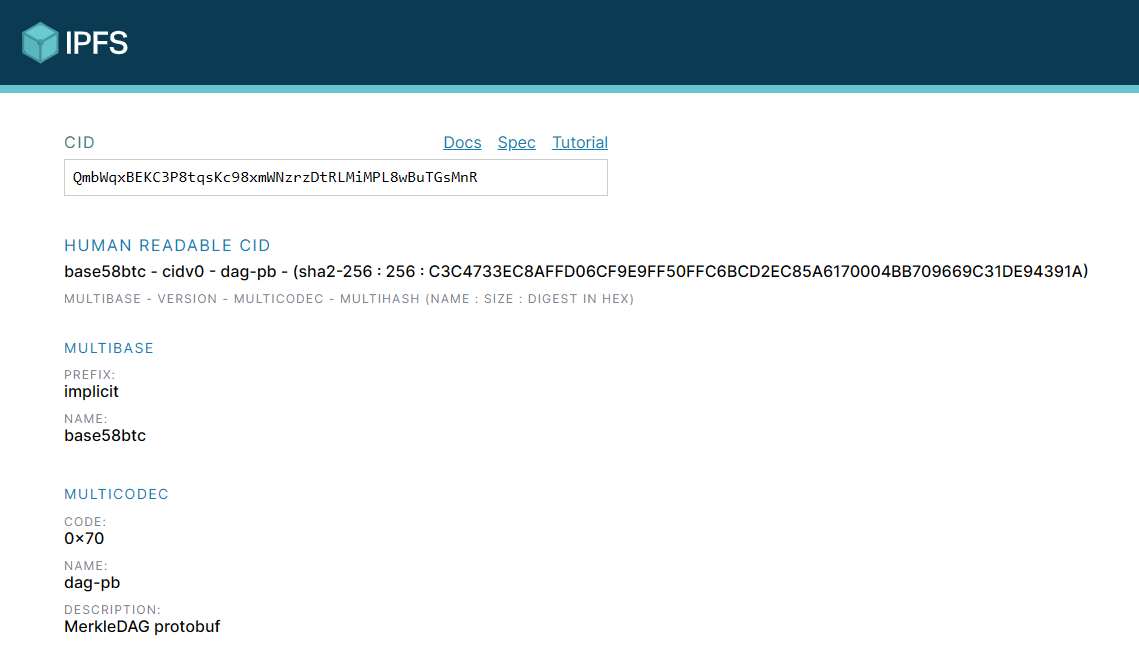
在 CIDv0 的结果中,多基数和多编码都显示为 “implicit”。这是由于 CIDv0 没有这两个前缀,因此它们被分别默认为 base58btc 和 dag-pb。
在原文的截图中,两个前缀都显示的是 “implicit”,但是我查看到的多编码并不是 “implicit”。
在 CIDV1(Base32) 标签下,我们看到:
bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi
这与第一个示例中的 CID 完全相同!CID 检查器为我们提供了从 CIDv0 到 CIDv1 的转换。
注意,CIDv0 示例与 CIDv1 示例中的 “人类可读 CID” 的末尾完全相同:
C3C4733EC8AFFD06CF9E9FF50FFC6BCD2EC85A6170004BB709669C31DE94391A
这是因为这两个 CID 指向相同的内容,即本质上两个 CID 代表的是相同的哈希。
4.3 转换 CID 的版本
我们可以将任何的 CIDv0 转换为 CIDv1,但不能将任何的 CIDv1 转换为 CIDv0 。这是由于 CIDv1 支持多编码和多基数,而 CIDv0 不支持。事实上,只有具有以下属性的 CIDv1 可以转换为 CIDv0:
- 多基数 =
base58btc - 多编码 =
dag-pb - 多哈希算法 =
sha2-256 - 多哈希长度 = 32 字节
为了测试这个理论,你可以查看我们亲爱的 土豚 图片,它托管在 IPFS 网络上:
https://ipfs.io/ipfs/QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
首先,从 URL 末尾复制 CID:
QmcRD4wkPPi6dig81r5sLj9Zm1gDCL4zgpEj9CfuRrGbzF
然后,将 CID 粘贴到 CID Inspector 工具中,并在页面底部找到等效的 CIDv1 值:
bafybeigrf2dwtpjkiovnigysyto3d55opf6qkdikx6d65onrqnfzwgdkfa
最后,将原始 URL 中的 CID 替换为转换后的 CID:
https://ipfs.io/ipfs/bafybeigrf2dwtpjkiovnigysyto3d55opf6qkdikx6d65onrqnfzwgdkfa
你应该看到的是相同的土豚图片。
这篇关于区块链 | IPFS:CID的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





