本文主要是介绍【数学建模】2024五一数学建模C题完整论文代码更新,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最新更新:2024五一数学建模C题 煤矿深部开采冲击地压危险预测:建立基于多域特征融合与时间序列分解的信号检测与区间识别模型完整论文已更新
2024五一数学建模题完整代码和成品论文获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/gyoz9ou5upvkv6nx?singleDoc#
2024五一数学建模C题 煤矿深部开采冲击地压危险预测:建立基于多域特征融合与时间序列分解的信号检测与区间识别模型。
A题和B题思路代码论文也已经更新,可见文末参考
本文文章较长,建议先看目录,完整文章参考可见文末
经过不懈的努力,2024五一数学建模C题48页完整论文和代码已完成,代码为C题全部问题的代码,论文包括摘要、问题重述、问题分析、模型假设、符号说明、模型的建立和求解(问题1模型的建立和求解、问题2模型的建立和求解、问题3模型的建立和求解)、模型的评价等等,文章的目录如下

摘要
摘要略
问题分析
首先是对2024五一数学建模的C题的问题分析,如下:
问题1分析
根据附件1中给出的2019年1月9日至2020年1月7日期间采集的电磁辐射和声发射数据,以及对应的数据类型标记,可以提取出干扰信号数据的一些典型特征。例如,可以分析干扰信号的振幅、频率、持续时间、周期性等特征,看它们与正常信号有何区别。还可以研究干扰信号前后的信号变化情况,探索识别干扰信号的新方法。通过对这些特征的分析和建模,可以给出至少3个识别干扰信号的显著特征。
在问题(1.2)中,需要利用问题(1.1)中得到的干扰信号特征,对2022年的部分电磁辐射和声发射信号数据进行分析,识别并给出最早发生的5个干扰信号所在的时间区间。这需要将特征量化,设计识别算法,遍历所有数据,一旦发现符合干扰信号特征的区间,即记录下来。由于需要分别对电磁辐射和声发射信号进行处理,可以分别建立不同的模型,也可以尝试建立一个统一的模型。最终需要将识别出的时间区间整理到表1和表2中。处理好干扰信号是进行后续分析的基础和前提 。
问题2分析
对于该问题,首先需要建立模型分析前兆特征信号的变化趋势及其它特征。根据题目中的说明和图2的示意图,前兆特征信号呈现出一种周期性增大的变化趋势,这是其最显著的特征。但除此之外,还可以进一步分析信号的其他统计特征,如方差、波动范围、极值等,看它们与正常工作信号有何区别。同时还可以尝试对信号进行时频域分析,从频域角度去识别前兆特征。通过模型分析和总结,给出至少3个可用于识别前兆特征信号的特征。
在问题(2.2)中,需要利用问题(2.1)中得到的前兆特征识别特征,对2020年、2021年和2022年的部分电磁辐射和声发射信号数据进行分析,分别识别出最早发生的5个前兆特征信号所在的时间区间,并将结果填入表3和表4中。这一过程需要遍历所有数据,一旦发现符合前兆特征的区间,即记录下来。前兆特征识别对于及时发现潜在的冲击地压风险至关重要,是确保煤矿安全生产的关键。
问题3分析
针对这一问题,需要基于问题2中获得的前兆特征识别模型,对每个时间点采集到的数据进行实时分析。根据信号数据的统计特征、变化趋势等,判断它们是否已经符合前兆特征的定义和特征,若符合则视为已经出现了前兆特征。由于仅有单个时间点的数据,难以从趋势角度判断,因此需要设计更精细的识别策略,如滑动窗口分析等。同时还需要将判断结果量化为发生概率的形式。
在附件3中给出了一些非连续时间段的电磁辐射和声发射信号数据。针对每个时间段的最后一个时间点,需要应用上述模型和方法,分别计算出该时刻出现前兆特征的概率,并将结果填入表5中。由于仅给出了单个时间点数据,其发生概率计算的难度会比较大,需要设计更为精细的方法进行评估。这一问题反映了实时预警的重要性,通过对每个时间点风险状态的评估,可以尽早发现异常并作出反应。
模型假设
下面是2024五一建模C题的模型假设:本文问题1到问题3的模型建立与求解过程中使用的主要模型假设如下:
-
在问题1中,我们针对干扰信号特征提取任务,提出了一种基于时域、频域和时频域特征融合的模型。该模型的主要假设包括:
-
干扰信号在时域、频域和时频域上都有独特的特征表现,通过融合这三个域的特征,可以全面刻画干扰信号的特性,提高识别的准确性。
-
时域统计特征(如最大值、均值、标准差等)可以反映信号的幅值分布特性。
-
频域特征(如频谱熵和频谱重心)可以刻画信号在频域的能量分布特性。
-
时频域特征(如小波分解系数的统计量)可以刻画信号在时间-频率平面上的能量分布特性。
-
通过滑动窗口分段和特征标准化,可以提高特征提取的效率和模型的性能。
-
在问题1中,我们提出了一种基于支持向量机(SVM)和滑动窗口的干扰信号检测模型。该模型的主要假设包括:
-
(后略,完整见文末参考)
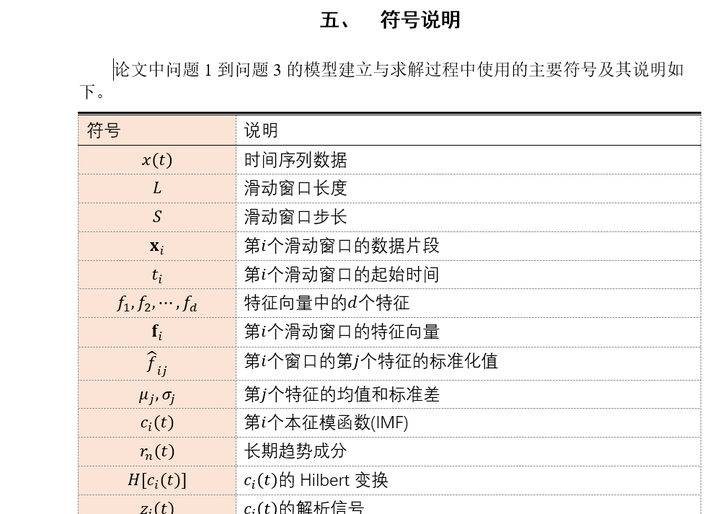
符号说明
论文中问题1到问题3的模型建立与求解过程中使用的主要符号及其说明如下(部分,完整见文末参考)。
问题一模型的建立与求解
下面是2024年五一数学建模竞赛C题具体的模型建立过程:
数据预处理与可视化
在问题1的模型建立和求解过程中,需要对原始电磁辐射和声发射数据进行预处理和可视化,以提高数据质量和增强对数据的理解。具体的预处理和可视化方法如下:
数据预处理方法:
1) 去噪处理:原始数据中可能存在噪声和异常值,需要进行去噪处理。常用的去噪方法包括小波变换去噪、中值滤波、卡尔曼滤波等。通过这些方法可以有效去除高频噪声和孤立的异常点,提高数据的信噪比。 2) 插值处理:由于各种原因,原始数据可能存在缺失值或断层。为了保证数据的连续性和完整性,需要使用插值方法对缺失值进行估计和填充。常用的插值方法包括线性插值、三次样条插值、最近邻插值等。
数据可视化方法:
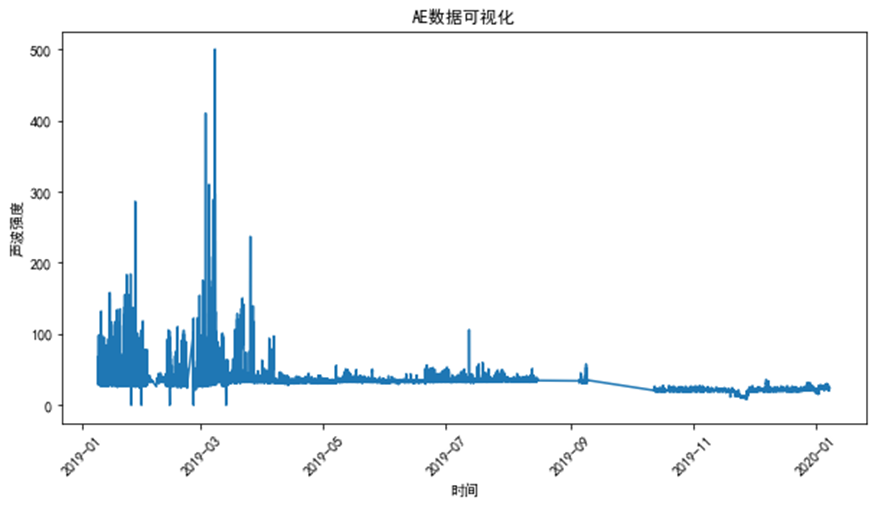
1) 时间序列可视化:将预处理后的电磁辐射和声发射数据绘制为时间序列图,直观展示数据在时间上的变化趋势和特征。可以使用不同颜色或线型区分不同类别的数据,如正常工作数据、前兆特征数据、干扰信号数据等。
-
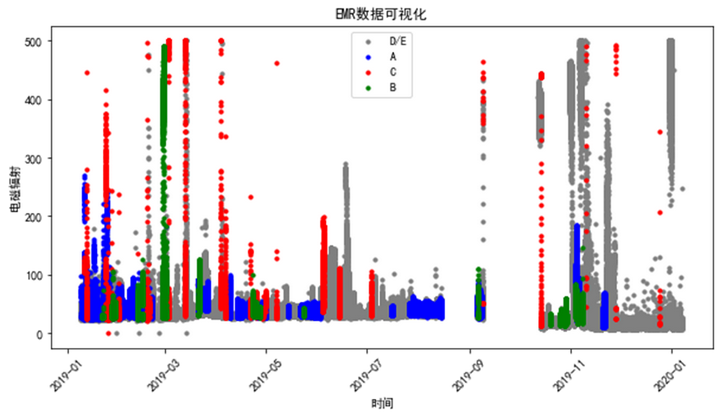
散点图可视化:将不同类别的数据在同一坐标系中用散点的形式绘制出来,可以直观地观察到不同类别数据在数值分布上的差异,有助于理解它们的特征区分度。
多域特征融合模型建立
针对问题1.1,即识别电磁辐射和声发射信号中的干扰信号并提取其特征,我们提出了一种基于时域、频域和时频域特征融合的干扰信号特征提取方法。下面给出详细的分析与建模过程:
干扰信号特征选择与提取思路分析
干扰信号在时域、频域和时频域上都有其独特的特征表现。为了全面刻画干扰信号的特性,我们从这三个域中提取有区分度的特征。
在时域上,干扰信号通常表现为突发的高幅值脉冲或异常的波形,与正常信号有明显差异。因此,我们可以提取时域统计特征,如最大值、最小值、均值、标准差、偏度和峰度等,来刻画信号的幅值分布特性。
在频域上,干扰信号的频谱分布可能与正常信号不同。通过对信号进行频谱分析,提取频域统计特征,如频谱熵和频谱重心等,可以刻画信号在频域的能量分布特性。
在时频域上,干扰信号的时频能量分布可能更加集中或散乱。采用小波变换等时频分析工具,提取时频域特征,如小波系数的统计特征等,可以刻画信号在时间-频率平面上的能量分布特性。
基于上述分析,我们选择从时域、频域和时频域三个方面提取特征,构建一个全面的干扰信号特征集合。通过特征融合,可以充分利用不同域的信息,提高干扰信号识别的准确性。
多域特征融合模型建立
针对干扰信号特征提取问题,我们提出了一种多域特征融合模型。该模型通过滑动窗口对时间序列数据进行分段,在每个窗口内提取时域、频域和时频域特征,并将它们融合为一个高维特征向量。


干扰信号特征提取算法步骤
基于多域特征融合模型,干扰信号特征提取的主要步骤如下:
(略,完整见文末参考)
通过以上步骤,可以从时间序列数据中提取出一系列多域融合特征向量,用于后续的干扰信号识别任务。通过以上数学公式,我们定义了14个多域特征,包括6个时域特征、2个频域特征和6个时频域特征。这些特征从不同角度刻画了信号的时间、频率和时频特性,提供了全面的信号表示。
在特征提取过程中,我们使用滑动窗口对时间序列数据进行分段,在每个窗口内计算这14个特征,形成一个特征向量。通过滑动窗口,我们可以获得一系列特征向量,每个特征向量对应一个数据片段。这种滑动窗口的方式可以捕捉信号的局部特征,同时考虑了时间的连续性。提取的特征可以用于后续的干扰信号识别任务,如训练分类器、异常检测等。通过融合多域特征,我们可以更全面地刻画干扰信号的特性,提高识别的准确性和可靠性。
综上所述,我们提出了一种基于多域特征融合的干扰信号特征提取方法。该方法结合了时域、频域和时频域的特征,通过滑动窗口对时间序列数据进行分段,在每个窗口内提取14个多域特征,形成特征向量。这种方法可以全面刻画干扰信号的特性,为后续的干扰信号识别任务提供有效的特征表示。同时,我们给出了特征提取的数学公式和解释,明确了每个特征的物理意义和计算方式。通过标准化处理,我们可以消除特征之间的量纲差异,使得特征对分类器的贡献更加平衡。

综上,干扰信号特征提取是干扰信号识别的关键步骤,直接影响识别的性能。本文提出的多域特征融合方法,结合了时域、频域和时频域的特征,提供了全面的信号表示。通过滑动窗口和特征标准化等技术,我们可以有效地提取干扰信号的特征,为后续的识别任务奠定基础。
# 可视化EMR数据
plt.figure(figsize=(10, 5))
colors = {'A': 'blue', 'B': 'green', 'C': 'red', 'D/E': 'gray'}
for category in emr_data['类别 (class)'].unique():data = emr_data[emr_data['类别 (class)'] == category]plt.scatter(data['时间 (time)'], data['电磁辐射 (EMR)'], c=colors[category], label=category, s=10)
plt.xlabel('时间')
plt.ylabel('电磁辐射')
plt.title('EMR数据可视化')
plt.legend()
plt.xticks(rotation=45)
plt.show()# 可视化AE数据
plt.figure(figsize=(10, 5))
for category in ae_data['类别 (class)'].unique():data = ae_data[ae_data['类别 (class)'] == category]plt.scatter(data['时间 (time)'], data['声波强度 (AE)'], c=colors[category], label=category, s=10)
plt.xlabel('时间')
plt.ylabel('声波强度')
plt.title('AE数据可视化')
plt.legend()
plt.xticks(rotation=45)
plt.show()# 提取EMR干扰信号特征
def extract_emr_features(data):features = []# 时域特征max_value = np.max(data)min_value = np.min(data)mean_value = np.mean(data)std_value = np.std(data)skewness = skew(data)kurtosis_value = kurtosis(data)# 频域特征
(略,完整见文末参考)# 时频域特征coeffs = pywt.wavedec(data, 'db4', level=5)wavelet_std = [np.std(coeff) for coeff in coeffs]features.extend([max_value, min_value, mean_value, std_value, skewness, kurtosis_value,spectral_entropy, spectral_centroid] + wavelet_std)return features基于支持向量机(SVM)和滑动窗口的干扰信号检测模型
2024年五一数学建模C题问题1.2模型建立:针对问题1.2,即识别电磁辐射和声发射信号中干扰信号所在的时间区间,我们提出了一种基于支持向量机(SVM)和滑动窗口的干扰信号检测方法。下面给出详细的分析与建模过程:
问题分析与思路
在实际应用中,干扰信号通常呈现出突发性、持续性或周期性等特点,与正常信号在时域、频域和时频域上都有明显差异。因此,我们可以将干扰信号检测问题转化为时间序列异常检测问题,即从时间序列数据中识别出异常区间。
为了实现干扰信号的精确定位,我们采用滑动窗口的方式对时间序列数据进行局部分析。具体思路如下:
-
特征提取:使用滑动窗口对时间序列数据进行分段,在每个窗口内提取多域特征,包括时域统计特征、频域特征和时频域特征等,形成特征向量。
-
模型训练:将提取的特征向量和对应的标签(正常或干扰)作为训练数据,使用SVM算法训练二分类模型。SVM通过寻找最大间隔超平面,对特征空间进行划分,实现异常区间的判别。
-
滑动检测:使用训练好的SVM模型,对测试数据进行滑动窗口检测。对每个滑动窗口提取特征向量,并使用SVM模型进行分类,判断该窗口是否为干扰信号。
-
区间合并:将连续的异常窗口合并为干扰信号区间,得到干扰信号的起始时间和结束时间。
通过以上步骤,我们可以实现干扰信号的精确定位,确定其在时间序列数据中的位置和持续时间。
支持向量机(SVM)模型建立
支持向量机(SVM)是一种经典的二分类模型,通过在特征空间中寻找最大间隔超平面,将不同类别的样本分开。在本问题中,我们使用SVM模型来实现干扰信号的判别。
完整版见↓↓↓↓↓
2024五一数学建模题完整代码和成品论文获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/gyoz9ou5upvkv6nx?singleDoc#
这篇关于【数学建模】2024五一数学建模C题完整论文代码更新的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







