本文主要是介绍LinkedHashMap实现原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LinkedHashMap实现了Map接口,继承于HashMap,与HashMap不同的是它维持有一个双链表,从而可以保证迭代时候的顺序。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

可以看出LinkedhashMap在HashMap 基础上,用一个双向的链表维持的插入时候的顺序(默认,即accessOrder = false)。
转自:http://blog.csdn.net/qq_28051453/article/details/71169801
先来说说它的特点,然后在一一通过分析源码来验证其实现原理
1、能够保证插入元素的顺序。深入一点讲,有两种迭代元素的方式,一种是按照插入元素时的顺序迭代,比如,插入A,B,C,那么迭代也是A,B,C,另一种是按照访问顺序,比如,在迭代前,访问了B,那么迭代的顺序就是A,C,B,比如在迭代前,访问了B,接着又访问了A,那么迭代顺序为C,B,A,比如,在迭代前访问了B,接着又访问了B,然后在访问了A,迭代顺序还是C,B,A。要说明的意思就是不是近期访问的次数最多,就放最后面迭代,而是看迭代前被访问的时间长短决定。
2、内部存储的元素的模型。entry是下面这样的,相比HashMap,多了两个属性,一个before,一个after。next和after有时候会指向同一个entry,有时候next指向null,而after指向entry。这个具体后面分析。

3、linkedHashMap和HashMap在存储操作上是一样的,但是LinkedHashMap多的东西是会记住在此之前插入的元素,这些元素不一定是在一个桶中,画个图。
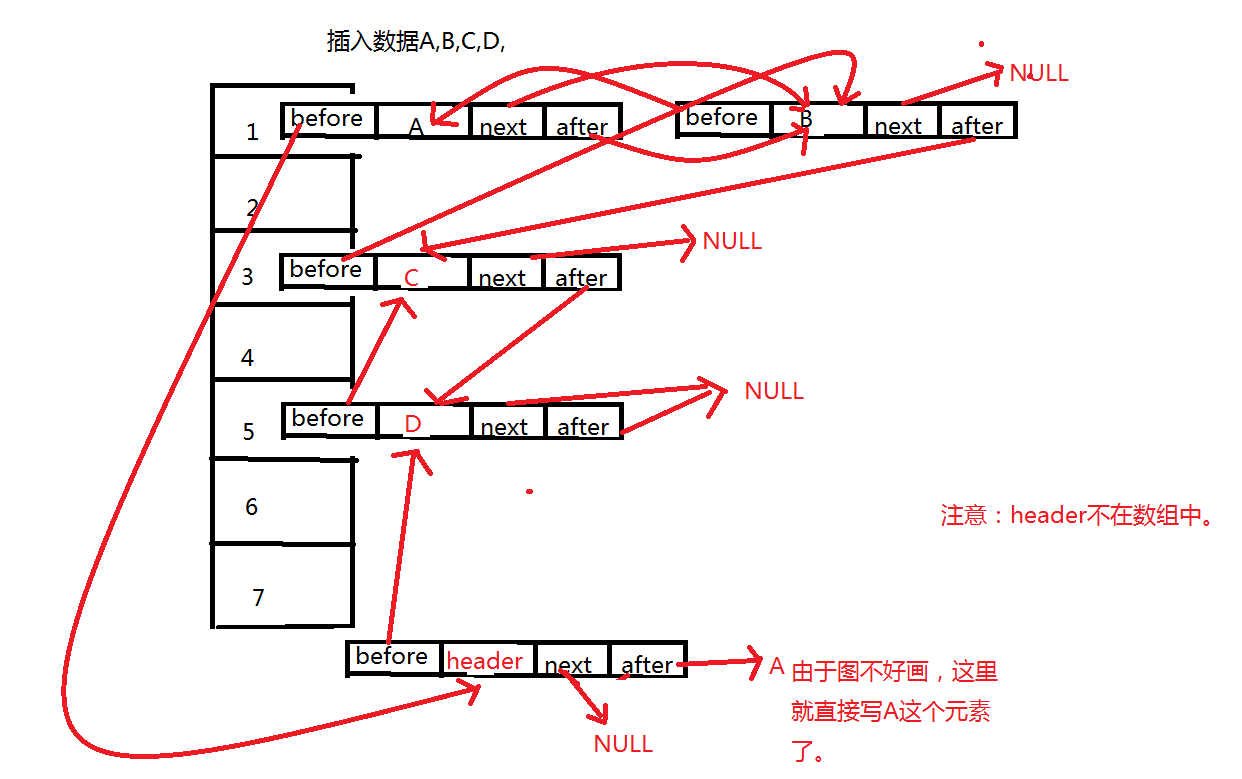
也就是说,对于linkedHashMap的基本操作还是和HashMap一样,在其上面加了两个属性,也就是为了记录前一个插入的元素和记录后一个插入的元素。也就是只要和hashmap一样进行操作之后把这两个属性的值设置好,就OK了。注意一点,会有一个header的实体,目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。
实际上存储的样子就像上面这个图一样,这里要分清楚哦。实际上的存储方式是和hashMap一样,但是同时增加了一个新的东西就是 双向循环链表。就是因为有了这个双向循环链表,LinkedHashMap才和HashMap不一样。
4、其他一些比如如何实现的循环双向链表,插入顺序和访问顺序如何实现的就看下面的详细讲解了。
LinkedHashMap底层是由数组和循环双向链表实现的转自:http://www.cnblogs.com/whgk/p/6169622.html
这篇关于LinkedHashMap实现原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



