本文主要是介绍【经典算法】LeetCode112. 路径总和(Java/C/Python3/Go实现含注释说明,Easy),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者主页: 🔗进朱者赤的博客
精选专栏:🔗经典算法
作者简介:阿里非典型程序员一枚 ,记录在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名)
❤️觉得文章还不错的话欢迎大家点赞👍➕收藏⭐️➕评论,💬支持博主,记得点个大大的
关注,持续更新🤞
————————————————-
题目描述
给定一个二叉树和一个目标和,判断该树中是否存在从根节点到叶子节点的路径,
这条路径上所有节点值相加等于目标和。说明: 叶子节点是指没有子节点的节点。
示例 1:
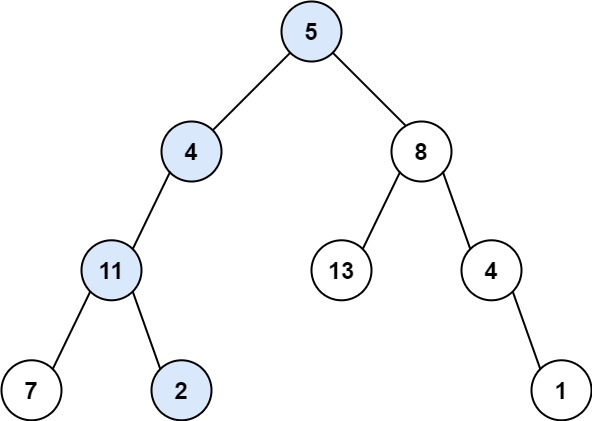
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
示例 2:
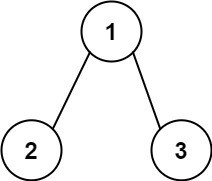
输入:root = [1,2,3], targetSum = 5
输出:false
解释:树中存在两条根节点到叶子节点的路径:
(1 --> 2): 和为 3
(1 --> 3): 和为 4
不存在 sum = 5 的根节点到叶子节点的路径。
示例 3:
输入:root = [], targetSum = 0
输出:false
解释:由于树是空的,所以不存在根节点到叶子节点的路径。
提示:
树中节点的数目在范围 [0, 5000] 内
-1000 <= Node.val <= 1000
-1000 <= targetSum <= 1000
原题:LeetCode 112
思路及实现
方式一:递归深度优先搜索(DFS)
思路
- 遍历树的每一个节点。
- 对于每个节点,判断当前节点到根节点的路径和是否等于目标和,如果等于且当前节点是叶子节点,则返回true。
- 如果不等于,则继续递归遍历左子树和右子树,并更新目标和为当前目标和减去当前节点的值。
代码实现
Java版本
class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) { val = x; }
}public class Solution {public boolean hasPathSum(TreeNode root, int sum) {if (root == null) {return false;}// 如果是叶子节点,且当前路径和等于目标和if (root.left == null && root.right == null) {return sum == root.val;}// 递归遍历左子树和右子树return hasPathSum(root.left, sum - root.val) || hasPathSum(root.right, sum - root.val);}
}
说明:Java版本使用了递归深度优先搜索的方式,遍历树的每个节点,并不断更新目标和值。
C语言版本
#include <stdbool.h>struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;
};bool hasPathSum(struct TreeNode* root, int sum){if (root == NULL) {return false;}if (root->left == NULL && root->right == NULL) {return sum == root->val;}return hasPathSum(root->left, sum - root->val) || hasPathSum(root->right, sum - root->val);
}
说明:C语言版本与Java版本类似,也使用了递归深度优先搜索的方式。
Python3版本
class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightclass Solution:def hasPathSum(self, root: TreeNode, sum: int) -> bool:if not root:return Falseif not root.left and not root.right:return sum == root.valreturn self.hasPathSum(root.left, sum - root.val) or self.hasPathSum(root.right, sum - root.val)
说明:Python3版本也使用了递归深度优先搜索的方式。
Golang版本
package mainimport ("fmt"
)type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode
}func hasPathSum(root *TreeNode, sum int) bool {if root == nil {return false}if root.Left == nil && root.Right == nil {return sum == root.Val}return hasPathSum(root.Left, sum-root.Val) || hasPathSum(root.Right, sum-root.Val)
}func main() {// 示例代码,实际使用时需要构建二叉树// ...fmt.Println(hasPathSum(/* root */, /* sum */))
}
说明:Golang版本同样使用了递归深度优先搜索的方式。
复杂度分析
- 时间复杂度:O(n),n是二叉树的节点数。每个节点只被访问一次。
- 空间复杂度:O(h),h是二叉树的高度。在递归过程中,系统需要为每一层递归调用分配栈空间,因此空间复杂度取决于二叉树的高度。在最坏情况下(树退化为链表),空间复杂度为O(n)。
方式二:迭代深度优先搜索(DFS)
思路
使用栈(Stack)来模拟递归过程,迭代遍历树的每个节点。在遍历过程中,需要额外存储当前路径的路径和(或者称为累积和)。栈中的元素可以是一个自定义的二元组(或结构体),包含当前节点和从根节点到当前节点的路径和。
代码实现
Java版本
import java.util.Stack;class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) { val = x; }
}public class Solution {public boolean hasPathSum(TreeNode root, int sum) {if (root == null) {return false;}Stack<TreeNode> nodeStack = new Stack<>();Stack<Integer> sumStack = new Stack<>();nodeStack.push(root);sumStack.push(root.val);while (!nodeStack.isEmpty()) {TreeNode node = nodeStack.pop();int currentSum = sumStack.pop();if (node.left == null && node.right == null) {if (currentSum == sum) {return true;}}if (node.left != null) {nodeStack.push(node.left);sumStack.push(currentSum + node.left.val);}if (node.right != null) {nodeStack.push(node.right);sumStack.push(currentSum + node.right.val);}}return false;}
}
说明:Java版本使用了两个栈,一个用于存储节点,另一个用于存储从根节点到当前节点的路径和。
C语言版本
#include <stdbool.h>
#include <stdlib.h>typedef struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;
} TreeNode;typedef struct StackNode {TreeNode *node;int sum;struct StackNode *next;
} StackNode;typedef struct Stack {StackNode *top;
} Stack;StackNode* createStackNode(TreeNode* node, int sum) {StackNode* newNode = (StackNode*)malloc(sizeof(StackNode));newNode->node = node;newNode->sum = sum;newNode->next = NULL;return newNode;
}bool isEmpty(Stack* stack) {return stack->top == NULL;
}void push(Stack* stack, StackNode* node) {node->next = stack->top;stack->top = node;
}StackNode* pop(Stack* stack) {if (isEmpty(stack)) {return NULL;}StackNode* top = stack->top;stack->top = stack->top->next;return top;
}bool hasPathSum(TreeNode* root, int sum) {if (root == NULL) {return false;}Stack stack;stack.top = NULL;push(&stack, createStackNode(root, root->val));while (!isEmpty(&stack)) {StackNode* curr = pop(&stack);TreeNode* node = curr->node;int currentSum = curr->sum;free(curr); // Don't forget to free memory allocated for the StackNodeif (node->left == NULL && node->right == NULL) {if (currentSum == sum) {return true;}}if (node->left != NULL) {push(&stack, createStackNode(node->left, currentSum + node->left->val));}if (node->right != NULL) {push(&stack, createStackNode(node->right, currentSum + node->right->val));}}return false;
}
说明:C语言版本使用了自定义的栈结构来模拟递归过程,同时管理节点和路径和。
C++版本
在上面的代码中,我们定义了一个二叉树节点结构TreeNode,并使用std::stack来实现了一个迭代版本的深度优先搜索(DFS)来检查二叉树中是否存在路径和等于给定值的路径。以下是对代码的一些额外说明和注释,以确保理解每个部分的作用。
#include <iostream>
#include <stack>using namespace std;// 二叉树节点的定义
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};// 检查是否存在路径和等于给定值的函数
bool hasPathSum(TreeNode* root, int sum) {if (root == nullptr) { // 如果根节点为空,则不存在路径return false;}// 使用栈来存储节点和路径和stack<pair<TreeNode*, int>> stk; // 栈中每个元素是一个pair,包含节点和到该节点的路径和stk.push({root, root->val}); // 初始时将根节点和它的值入栈// 当栈不为空时,继续迭代while (!stk.empty()) {// 弹出栈顶元素pair<TreeNode*, int> curr = stk.top();stk.pop();TreeNode* node = curr.first;int currentSum = curr.second;// 如果当前节点是叶子节点且路径和等于sum,则返回trueif (node->left == nullptr && node->right == nullptr && currentSum == sum) {return true;}// 如果左子节点存在,则将其和路径和的增量入栈if (node->left != nullptr) {stk.push({node->left, currentSum + node->left->val});}// 如果右子节点存在,则将其和路径和的增量入栈if (node->right != nullptr) {stk.push({node->right, currentSum + node->right->val});}}// 如果没有找到满足条件的路径,则返回falsereturn false;
}// 测试代码
int main() {// 构造一个简单的二叉树进行测试// ...(构造二叉树的代码省略)int targetSum = 22;bool result = hasPathSum(root, targetSum);cout << "Does the tree contain a path with sum " << targetSum << "? " << (result ? "Yes" : "No") << endl;// 释放二叉树内存(这里只是示例,实际中可能需要递归释放)// ...(释放二叉树内存的代码省略)return 0;
}
说明
在上面的代码中,我添加了注释来解释每个部分的作用。在hasPathSum函数中,我们使用了一个std::stack来存储节点和路径和的pair。我们首先将根节点和它的值压入栈中,然后进入一个循环,只要栈不为空就继续迭代。在每次迭代中,我们弹出栈顶元素,检查它是否满足路径和等于给定值sum的条件。如果不满足,我们就检查它的左子节点和右子节点是否存在,如果存在,我们就将它们和路径和的增量压入栈中。最后,如果栈为空且没有找到满足条件的路径,我们就返回false。
在main函数中,我们构造了一个二叉树,并调用了hasPathSum函数来检查是否存在路径和等于给定值的路径。然后,我们输出了结果,并注释了释放二叉树内存的部分(这部分在实际应用中需要根据具体的二叉树结构来实现)。
Python3 版本
# Definition for a binary tree node.
class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightdef hasPathSum(root: TreeNode, sum: int) -> bool:if not root: # 如果根节点为空,则不存在路径return Falseif not root.left and not root.right: # 如果是叶子节点,检查路径和是否等于sumreturn root.val == sum# 递归检查左子树和右子树left_has_path = hasPathSum(root.left, sum - root.val)right_has_path = hasPathSum(root.right, sum - root.val)# 只要左子树或右子树中存在满足条件的路径,就返回Truereturn left_has_path or right_has_path
Golang 版本
package mainimport ("fmt"
)// TreeNode represents a binary tree node.
type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode
}// hasPathSum checks if there's a path in the binary tree with the given sum.
func hasPathSum(root *TreeNode, sum int) bool {if root == nil { // 如果根节点为空,则不存在路径return false}if root.Left == nil && root.Right == nil { // 如果是叶子节点,检查路径和是否等于sumreturn root.Val == sum}// 递归检查左子树和右子树leftHasPath := hasPathSum(root.Left, sum-root.Val)rightHasPath := hasPathSum(root.Right, sum-root.Val)// 只要左子树或右子树中存在满足条件的路径,就返回truereturn leftHasPath || rightHasPath
}func main() {// ... (构造二叉树并调用函数的代码)// 例如:// root := &TreeNode{Val: 5}// root.Left = &TreeNode{Val: 4}// root.Right = &TreeNode{Val: 8}// ... (继续构造二叉树)// sum := 22// fmt.Println(hasPathSum(root, sum))
}
说明
复杂度分析
- 时间复杂度:O(N),其中N是二叉树的节点数。在最坏情况下,我们需要遍历二叉树中的所有节点。
- 空间复杂度:O(H),其中H是二叉树的高度。递归调用栈的深度最多为二叉树的高度。在平均情况下,树是平衡的,其高度为O(logN),但在最坏情况下(例如,树退化为链表),高度为O(N)。
总结
| 方式 | 优点 | 缺点 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 递归深度优先搜索(DFS) | 1. 代码简洁,逻辑清晰 2. 易于理解和实现 | 1. 对于大型树,可能引发栈溢出 2. 递归调用栈占用额外空间 | O(N) | O(H),其中H为树的高度,最坏情况下为O(N) |
| 迭代深度优先搜索(DFS) | 1. 避免了栈溢出问题 2. 空间复杂度相对较低 | 1. 需要使用辅助数据结构(如栈) 2. 代码实现相对复杂 | O(N) | O(N) 或 O(H),取决于使用的辅助数据结构 |
相似题目
以下是几个与“检查二叉树中是否存在路径和等于给定值”相似的题目,以及它们的难度和链接:
| 相似题目 | 难度 | 链接 |
|---|---|---|
| leetcode 112 路径总和 | 简单 | 力扣-112 |
| leetcode 113 路径总和 II | 中等 | 力扣-113 |
| leetcode 437 路径总和 III | 中等 | 力扣-437 |
| leetcode 129 求根到叶子节点数字之和 | 中等 | 力扣-129 |
| leetcode 543 二叉树的直径 | 简单 | 力扣-543 |
注意:以上链接均指向力扣(LeetCode)中国区的题目页面。如果需要访问国际版,可以将链接中的 “leetcode-cn.com” 替换为 “leetcode.com”。
欢迎一键三连(关注+点赞+收藏),技术的路上一起加油!!!代码改变世界
关于我:阿里非典型程序员一枚 ,记录在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名),回复暗号,更能获取学习秘籍和书籍等
—⬇️欢迎关注下面的公众号:
进朱者赤,认识不一样的技术人。⬇️—
这篇关于【经典算法】LeetCode112. 路径总和(Java/C/Python3/Go实现含注释说明,Easy)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




