本文主要是介绍LuaJIT源码分析(三)字符串,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LuaJIT源码分析(三)字符串
要表示一个字符串,核心就是需要知道字符串的长度,以及存放字符串具体数据的地址。lua的字符串是内化不可变的,也就是lua字符串变量存放的不是字符串的拷贝,而是字符串的引用。那么,每当新建一个字符串时,lua都会去检查当前虚拟机中是否已经存在相同的数据,如果有就可以直接拿来用,没有再进行创建。
为了实现这一机制,lua必然有一个全局的地方存放当前用到的所有字符串。luajit内部使用了散列桶来管理字符串,在已知字符串的hash值时,只需要一次整数比较就可以快速查找。基于此,相同的字符串在虚拟机中只存在一个副本。
luajit中用于表示字符串的数据结构如下:
// lj_obj.h
/* String object header. String payload follows. */
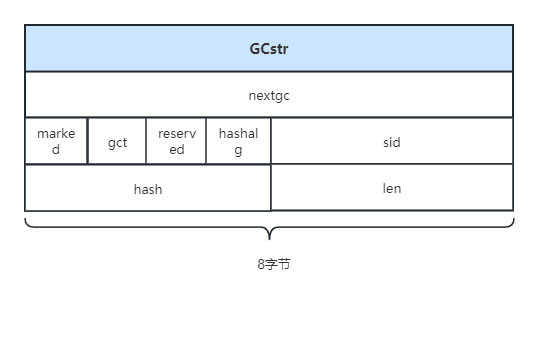
typedef struct GCstr {GCHeader;uint8_t reserved; /* Used by lexer for fast lookup of reserved words. */uint8_t hashalg; /* Hash algorithm. */StrID sid; /* Interned string ID. */StrHash hash; /* Hash of string. */MSize len; /* Size of string. */
} GCstr;
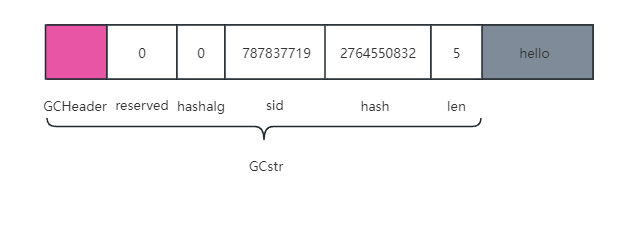
GCHeader就是上一节所说的用于gc管理的通用数据结构;reserved用来表示是否为lua的保留关键字,它是一个uint8_t类型,对应保留字列表的下标;hashalg表示该字符串是否被二次hash;sid保存了该字符串的全局ID,而hash则是该字符串的hash值。最后len字段表示整个字符串的长度。然后,实际字符串的内容保存在len字段之后。假如有一个字符串"hello",那么它在luajit内部所填充的GCstr数据结构可能长这样:
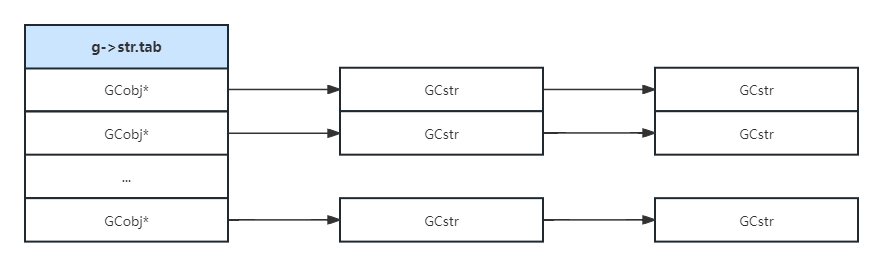
系统中的所有字符串都保存在luajit中global_state的str字段,这个字段是StrInternState类型:
// lj_obj.h
/* String interning state. */
typedef struct StrInternState {GCRef *tab; /* String hash table anchors. */MSize mask; /* String hash mask (size of hash table - 1). */MSize num; /* Number of strings in hash table. */StrID id; /* Next string ID. */uint8_t idreseed; /* String ID reseed counter. */uint8_t second; /* String interning table uses secondary hashing. */uint8_t unused1;uint8_t unused2;LJ_ALIGN(8) uint64_t seed; /* Random string seed. */
} StrInternState;
tab字段保存了所有字符串,它是个链表数组,每个新建的字符串先根据hash算法计算出自身的hash值,再根据当前StrInternState的mask,得到数组的索引,如果已经有元素,就插入到链表的头部。
下面我们来看下创建字符串的具体过程吧。入口是lj_str_new这个函数,它接受原始字符串指针和字符串长度作为参数:
// lj_str.c
/* Intern a string and return string object. */
GCstr *lj_str_new(lua_State *L, const char *str, size_t lenx)
{global_State *g = G(L);if (lenx-1 < LJ_MAX_STR-1) {MSize len = (MSize)lenx;StrHash hash = hash_sparse(g->str.seed, str, len);MSize coll = 0;int hashalg = 0;/* Check if the string has already been interned. */GCobj *o = gcref(g->str.tab[hash & g->str.mask]);
#if LUAJIT_SECURITY_STRHASHif (LJ_UNLIKELY((uintptr_t)o & 1)) { /* Secondary hash for this chain? */hashalg = 1;hash = hash_dense(g->str.seed, hash, str, len);o = (GCobj *)(gcrefu(g->str.tab[hash & g->str.mask]) & ~(uintptr_t)1);}
#endifwhile (o != NULL) {GCstr *sx = gco2str(o);if (sx->hash == hash && sx->len == len) {if (memcmp(str, strdata(sx), len) == 0) {if (isdead(g, o)) flipwhite(o); /* Resurrect if dead. */return sx; /* Return existing string. */}coll++;}coll++;o = gcnext(o);}
#if LUAJIT_SECURITY_STRHASH/* Rehash chain if there are too many collisions. */if (LJ_UNLIKELY(coll > LJ_STR_MAXCOLL) && !hashalg) {return lj_str_rehash_chain(L, hash, str, len);}
#endif/* Otherwise allocate a new string. */return lj_str_alloc(L, str, len, hash, hashalg);} else {if (lenx)lj_err_msg(L, LJ_ERR_STROV);return &g->strempty;}
}
首先,luajit会根据字符串的内容,使用hash_sparse这个函数计算它的hash值。hash_sparse接受3个参数,全局的seed,字符串的内容,以及字符串的长度。使用seed来辅助生成hash,有助于防止Hash DoS攻击。由于每次新建字符串时都需要计算一次hash,这个函数调用会比较频繁,因此它是一个稀疏的hash函数,内部实现使用了lookup3 hash算法,只会取字符串中的常数个字节进行计算,所以函数的运行是一个常数的时间。
得到hash值之后,根据当前字符串hash数组的大小,就能得到索引值。luajit为了速度考虑,实际保存的是mask,也就是hash数组的大小减一,数组大小永远是2的幂,那么mask就可以作为掩码,通过按位与就能迅速算出索引。luajit初始化时默认的hash数组大小为256。
// lj_def.h
#define LJ_MIN_STRTAB 256 /* Min. string table size (pow2). */
hash数组存放的是字符串链表,需要从链表头开始遍历,看看当前的字符串是否已经内化过了。这里的比较逻辑也是有讲究的,首先比较的是hash值和长度,只有两者都相等时,再调用更加费时的memcmp函数进行精确比较,这也是最大化地提升了比较的效率。
如果找到了相同的字符串,那么直接返回即可,如果没有,则需要调用lj_str_alloc函数进行真正的字符串创建。
// lj_str.c
static GCstr *lj_str_alloc(lua_State *L, const char *str, MSize len,StrHash hash, int hashalg)
{GCstr *s = lj_mem_newt(L, lj_str_size(len), GCstr);global_State *g = G(L);uintptr_t u;newwhite(g, s);s->gct = ~LJ_TSTR;s->len = len;s->hash = hash;
#ifndef STRID_RESEED_INTERVALs->sid = g->str.id++;
#elif STRID_RESEED_INTERVALif (!g->str.idreseed--) {uint64_t r = lj_prng_u64(&g->prng);g->str.id = (StrID)r;g->str.idreseed = (uint8_t)(r >> (64 - STRID_RESEED_INTERVAL));}s->sid = g->str.id++;
#elses->sid = (StrID)lj_prng_u64(&g->prng);
#endifs->reserved = 0;s->hashalg = (uint8_t)hashalg;/* Clear last 4 bytes of allocated memory. Implies zero-termination, too. */*(uint32_t *)(strdatawr(s)+(len & ~(MSize)3)) = 0;memcpy(strdatawr(s), str, len);/* Add to string hash table. */hash &= g->str.mask;u = gcrefu(g->str.tab[hash]);setgcrefp(s->nextgc, (u & ~(uintptr_t)1));/* NOBARRIER: The string table is a GC root. */setgcrefp(g->str.tab[hash], ((uintptr_t)s | (u & 1)));if (g->str.num++ > g->str.mask) /* Allow a 100% load factor. */lj_str_resize(L, (g->str.mask<<1)+1); /* Grow string table. */return s; /* Return newly interned string. */
}
这里主要可以分为两部分,一是创建填充GCstr数据结构,二是将GCstr链接到全局hash数组的正确位置上。GCstr有一个sid字段,它表示字符串的唯一ID,所有字符串都是不同的,生成方式与STRID_RESEED_INTERVAL宏定义有关。这个宏表示使用伪随机函数重新生成一个字符串id的间隔。
// lj_str.c
/* Reseed String ID from PRNG after random interval < 2^bits. */
#if LUAJIT_SECURITY_STRID == 1
#define STRID_RESEED_INTERVAL 8
#elif LUAJIT_SECURITY_STRID == 2
#define STRID_RESEED_INTERVAL 4
#elif LUAJIT_SECURITY_STRID >= 3
#define STRID_RESEED_INTERVAL 0
#endif
这个宏的值取决于LUAJIT_SECURITY_STRID宏的定义。
// lj_arch.h
#ifndef LUAJIT_SECURITY_STRID
/* String IDs: 0 = linear, 1 = reseed < 255, 2 = reseed < 15, 3 = random. */
#define LUAJIT_SECURITY_STRID 1
#endif
通过代码注释得知,sid的生成有4种模式,当LUAJIT_SECURITY_STRID定义为0时,sid是以线性递增的方式生成的,这样速度快,但是安全性较低;当定义为3时,sid则是以随机的方式生成的,每次都会调用伪随机函数得到新的sid,安全性高,但相应速度也会慢;当定义为1或2时,则以不同的间隔随机生成sid,随机数生成时,取二进制位前STRID_RESEED_INTERVAL位,记录在全局的idreseed字段上,作为下次调用伪随机函数的间隔。这样既保证了一定的安全性,又没有牺牲太多的性能,算是一个折衷的方案。伪随机数生成的函数名为lj_prng_u64,它是一个周期为 2 223 2^{223} 2223的函数,因此基本不用担心随机数会生成重复。
当然,字符串内容也需要填充到GCstr中。实际分配GCstr的内存块大小,包含了GCstr和字符串,还有对齐字节:
// lj_str.h
#define lj_str_size(len) (sizeof(GCstr) + (((len)+4) & ~(MSize)3))
在LJ_GC64模式下,GCstr本身所占的内存大小为24字节,已经是4字节对齐了:
那么,这里的对齐字节是为了让字符串对齐使用的,而且是向上取整,意味着如果len的大小已经是4字节对齐了,还是会多分配4个字节。之所以这么做,是为了快速填充字符串结尾的’\0’,它是不包含在字符串的长度中,但是又是实际需要填充进来的字符。这样luajit就可以快速地将最后4个字节先清零,然后再进行字符串拷贝,保证字符串是以’\0’结尾。
GCstr构造完毕后就要把它链接到hash数组中,这一步其实很简单,根据GCstr的hash值,与mask按位与得到数组的索引,然后作为链表的头部插入到链表中。自此,理想情况下字符串的构建工作就完成了。现在,让我们回过头来想一想不理想的情况。
前面说过,luajit为了快速计算字符串的hash值,使用的是一种稀疏的算法,只取了字符串的某些位来做hash运算。那么不可避免地,如果有大量相似的字符串,会导致明显的hash冲突。luajit会检测生成字符串时hash冲突的数量,也就是相同hash值下链表的长度,如果长度超过LJ_STR_MAXCOLL,就会把这个链表上的所有字符串重新hash一次,二次映射到不同的hash值上,以解决hash碰撞。
// lj_str.c
#define LJ_STR_MAXCOLL 32
rehash的函数名为lj_str_rehash_chain:
// lj_str.c
/* Rehash and rechain all strings in a chain. */
static LJ_NOINLINE GCstr *lj_str_rehash_chain(lua_State *L, StrHash hashc,const char *str, MSize len)
{global_State *g = G(L);int ow = g->gc.state == GCSsweepstring ? otherwhite(g) : 0; /* Sweeping? */GCRef *strtab = g->str.tab;MSize strmask = g->str.mask;GCobj *o = gcref(strtab[hashc & strmask]);setgcrefp(strtab[hashc & strmask], (void *)((uintptr_t)1));g->str.second = 1;while (o) {uintptr_t u;GCobj *next = gcnext(o);GCstr *s = gco2str(o);StrHash hash;if (ow) { /* Must sweep while rechaining. */if (((o->gch.marked ^ LJ_GC_WHITES) & ow)) { /* String alive? */lj_assertG(!isdead(g, o) || (o->gch.marked & LJ_GC_FIXED),"sweep of undead string");makewhite(g, o);} else { /* Free dead string. */lj_assertG(isdead(g, o) || ow == LJ_GC_SFIXED,"sweep of unlive string");lj_str_free(g, s);o = next;continue;}}hash = s->hash;if (!s->hashalg) { /* Rehash with secondary hash. */hash = hash_dense(g->str.seed, hash, strdata(s), s->len);s->hash = hash;s->hashalg = 1;}/* Rechain. */hash &= strmask;u = gcrefu(strtab[hash]);setgcrefp(o->gch.nextgc, (u & ~(uintptr_t)1));setgcrefp(strtab[hash], ((uintptr_t)o | (u & 1)));o = next;}/* Try to insert the pending string again. */return lj_str_new(L, str, len);
}
对于需要重新hash的链表,luajit会把链表头的地址设置为(uintptr_t)1,作为二次hash的标记,同时设置全局的second字段为1,表示luajit启用了二次hash。然后开始遍历原来的链表,对于没有引用需要gc清理的字符串,会直接进行回收。存活的字符串,如果已经二次hash过了,依旧是留在原来的链表中,它的hash值保持不变;否则调用hash_dense函数重新计算hash。hash_dense函数会用到字符串的所有数据计算,所以它是线性的运行时间,要比之前的hash_sparse运行时间要慢,但是生成的hash值质量会更高,更难发生hash碰撞。
无论最后字符串的hash值是否发生变化,都需要重新做一次链接操作,也就是将字符串插入到对应hash值的链表头部。链表头部可能包含二次hash的特殊标记,所以还要插入的同时,把这个标记一直保留在链表头部。这里的实现方式很巧妙,首先是取出当前的链表头,然后通过u & ~(uintptr_t)1得到字符串对象地址,再通过u & 1得到标记本身,这样就能把标记转移到新的链表头部,以及清理掉旧链表头的标记。那么,这样就有一个疑问了,luajit如何能保证字符串的地址不会被标记所污染呢?这是因为luajit在进行内存分配时,是默认8字节对齐的,因此分配返回的地址,末3位均为0,可以拿来做一些附加的工作。
// lj_alloc.c
#define MALLOC_ALIGNMENT ((size_t)8U)
我们可以运行时通过断点来进行验证:

加入了二次hash之后,查找字符串是否已被内化的逻辑,也需要进行修改。在使用hash_sparse计算出字符串的原始hash值之后,还需要判断是否需要再次hash。检查对应索引下的链表头是否带有特殊标记,如有则使用hash_dense计算新的hash值,取出字符串真正所在的链表头。
// lj_str.c
if (LJ_UNLIKELY((uintptr_t)o & 1)) { /* Secondary hash for this chain? */hashalg = 1;hash = hash_dense(g->str.seed, hash, str, len);o = (GCobj *)(gcrefu(g->str.tab[hash & g->str.mask]) & ~(uintptr_t)1);
}
理想情况下,hash数组每一项都只存放一个字符串,也就是不存在hash冲突。luajit会检测当前系统中的字符串数量,如果超过hash数组的长度,则会进行2倍扩容。调整hash数组大小的函数为lj_str_resize:
// lj_str.c
/* Resize the string interning hash table (grow and shrink). */
void lj_str_resize(lua_State *L, MSize newmask)
{global_State *g = G(L);GCRef *newtab, *oldtab = g->str.tab;MSize i;/* No resizing during GC traversal or if already too big. */if (g->gc.state == GCSsweepstring || newmask >= LJ_MAX_STRTAB-1)return;newtab = lj_mem_newvec(L, newmask+1, GCRef);memset(newtab, 0, (newmask+1)*sizeof(GCRef));#if LUAJIT_SECURITY_STRHASH/* Check which chains need secondary hashes. */if (g->str.second) {int newsecond = 0;/* Compute primary chain lengths. */for (i = g->str.mask; i != ~(MSize)0; i--) {GCobj *o = (GCobj *)(gcrefu(oldtab[i]) & ~(uintptr_t)1);while (o) {GCstr *s = gco2str(o);MSize hash = s->hashalg ? hash_sparse(g->str.seed, strdata(s), s->len) :s->hash;hash &= newmask;setgcrefp(newtab[hash], gcrefu(newtab[hash]) + 1);o = gcnext(o);}}/* Mark secondary chains. */for (i = newmask; i != ~(MSize)0; i--) {int secondary = gcrefu(newtab[i]) > LJ_STR_MAXCOLL;newsecond |= secondary;setgcrefp(newtab[i], secondary);}g->str.second = newsecond;}
#endif/* Reinsert all strings from the old table into the new table. */for (i = g->str.mask; i != ~(MSize)0; i--) {GCobj *o = (GCobj *)(gcrefu(oldtab[i]) & ~(uintptr_t)1);while (o) {GCobj *next = gcnext(o);GCstr *s = gco2str(o);MSize hash = s->hash;
#if LUAJIT_SECURITY_STRHASHuintptr_t u;if (LJ_LIKELY(!s->hashalg)) { /* String hashed with primary hash. */hash &= newmask;u = gcrefu(newtab[hash]);if (LJ_UNLIKELY(u & 1)) { /* Switch string to secondary hash. */s->hash = hash = hash_dense(g->str.seed, s->hash, strdata(s), s->len);s->hashalg = 1;hash &= newmask;u = gcrefu(newtab[hash]);}} else { /* String hashed with secondary hash. */MSize shash = hash_sparse(g->str.seed, strdata(s), s->len);u = gcrefu(newtab[shash & newmask]);if (u & 1) {hash &= newmask;u = gcrefu(newtab[hash]);} else { /* Revert string back to primary hash. */s->hash = shash;s->hashalg = 0;hash = (shash & newmask);}}/* NOBARRIER: The string table is a GC root. */setgcrefp(o->gch.nextgc, (u & ~(uintptr_t)1));setgcrefp(newtab[hash], ((uintptr_t)o | (u & 1)));
#elsehash &= newmask;/* NOBARRIER: The string table is a GC root. */setgcrefr(o->gch.nextgc, newtab[hash]);setgcref(newtab[hash], o);
#endifo = next;}}/* Free old table and replace with new table. */lj_str_freetab(g);g->str.tab = newtab;g->str.mask = newmask;
}
所谓的resize,就是重新分配一个指定大小的hash数组,然后把原来hash数组里的所有字符串链接到新的hash数组上去。不过由于有二次hash的存在,事情变得稍微复杂了些。首先,原先需要二次hash的链表,在resize之后,不一定还需要二次hash了。luajit判断链表需要二次hash的标准是,链表的长度超过LJ_STR_MAXCOLL,所以在新的hash数组中,luajit统计了每个索引的链表长度。特别注意一点,如果原链表中的字符串是二次hash的,那需要重新计算一下它的原始hash值。统计完毕后,luajit遍历新的hash数组,如果某个索引下的链表长度超过了LJ_STR_MAXCOLL,需要重新hash,则会将它的链表头设置为1,否则为0。这里的1就是前面所说的特殊标记。
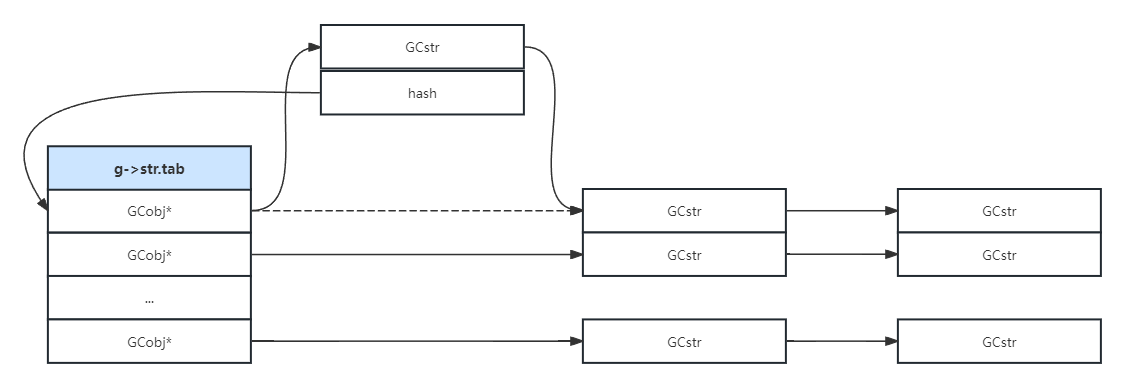
准备工作完成后,就可以把所有的字符串链接到新的hash数组中。链接分为以下4种情况:
- 字符串没有二次hash过,链表不需要二次hash;
- 字符串没有二次hash过,链表需要二次hash;
- 字符串二次hash过,链表不需要二次hash;
- 字符串二次hash过,链表需要二次hash。
第一种情况,直接插入即可:
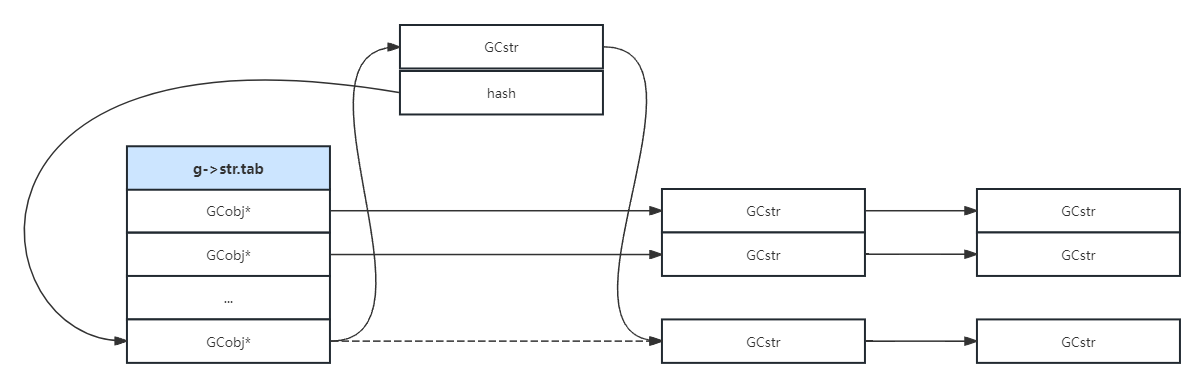
第二种情况,需要计算字符串的二次hash值,然后插入到正确的位置,同时需要修改字符串的hash值为二次hash,以及二次hash的标记为1:
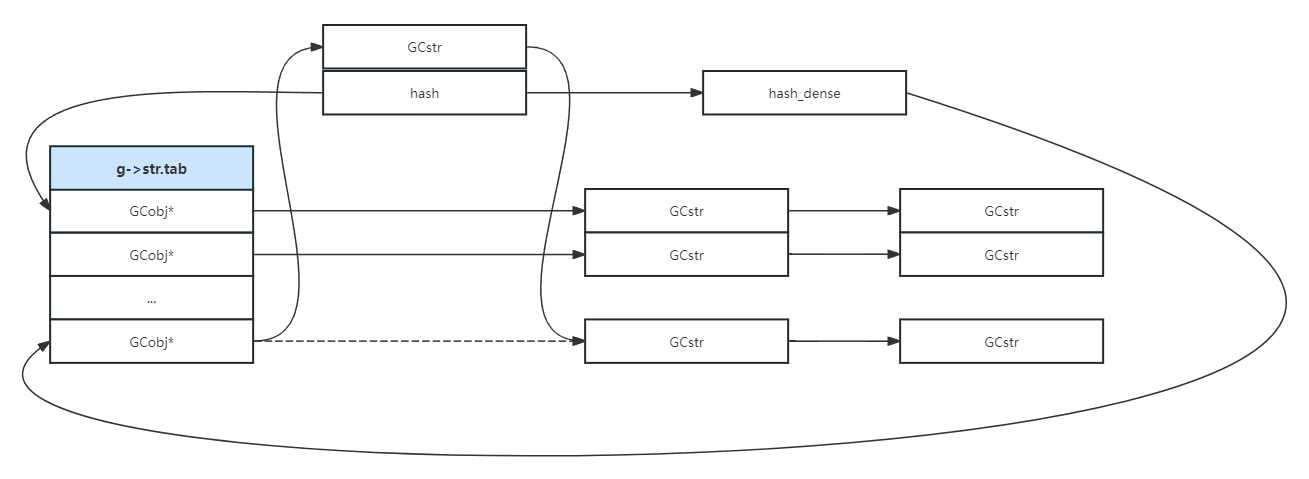
第三种情况,需要计算字符串的原始hash值,然后插入到正确的位置,同时需要修改字符串的hash值为原始hash,以及二次hash的标记为0:
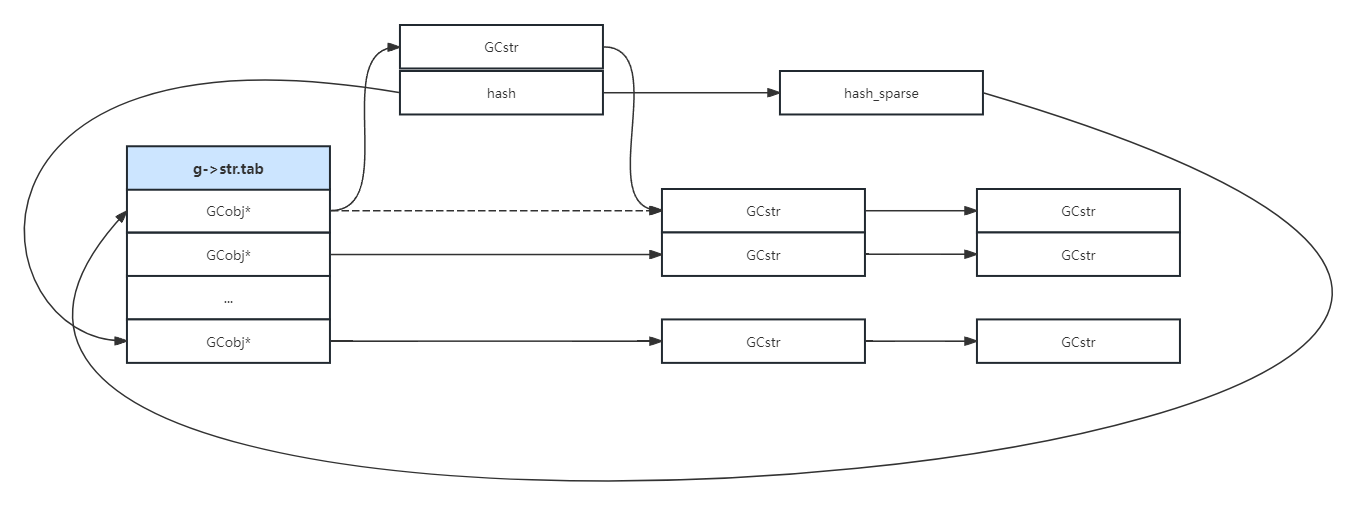
最后一种情况,直接插入即可。
自此,我们算是把luajit中字符串的数据结构,内存管理的内容梳理完毕了。通过一系列的分析可以看出,luajit在字符串的执行效率上和内存占用上下了很大的功夫,做了很多的考虑。我们从中也能看到两个比较明显的性能热点,一是hash冲突导致的rehash过程,这个会让链表上的所有字符串重新hash;二是hash数组大小不够导致的resize过程,这个需要把所有的字符串重新链接。
Reference
[1] Luajit String Interning
[2] Speeding Up Strings
[3] Lua string 哈希碰撞
[4] Lua string hash 算法
[5] Reduce string hash collisions
这篇关于LuaJIT源码分析(三)字符串的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





