本文主要是介绍产业结构-整体升级、合理化、高级化数据集(1990-2022年),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、数据介绍
数据名称:产业结构协调-高级化、合理化
数据年份:1990-2022年
数据范围:全国31个省份
数据来源:中国统计NJ、国家TJ局
数据类型:内含原始版本、线性插值版本、ARIMA填补版本
数据说明:参考干春晖(2011)《经济研究》的文章 ,测算产业整体升级、高级化、合理化水平
二、参考文献
干春晖,郑若谷,余典范.中国产业结构变迁对经济增长和波动的影响[J].经济研究,2011,46(05):4-16+31.
测算方式:

三、计算公式
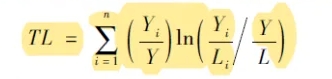
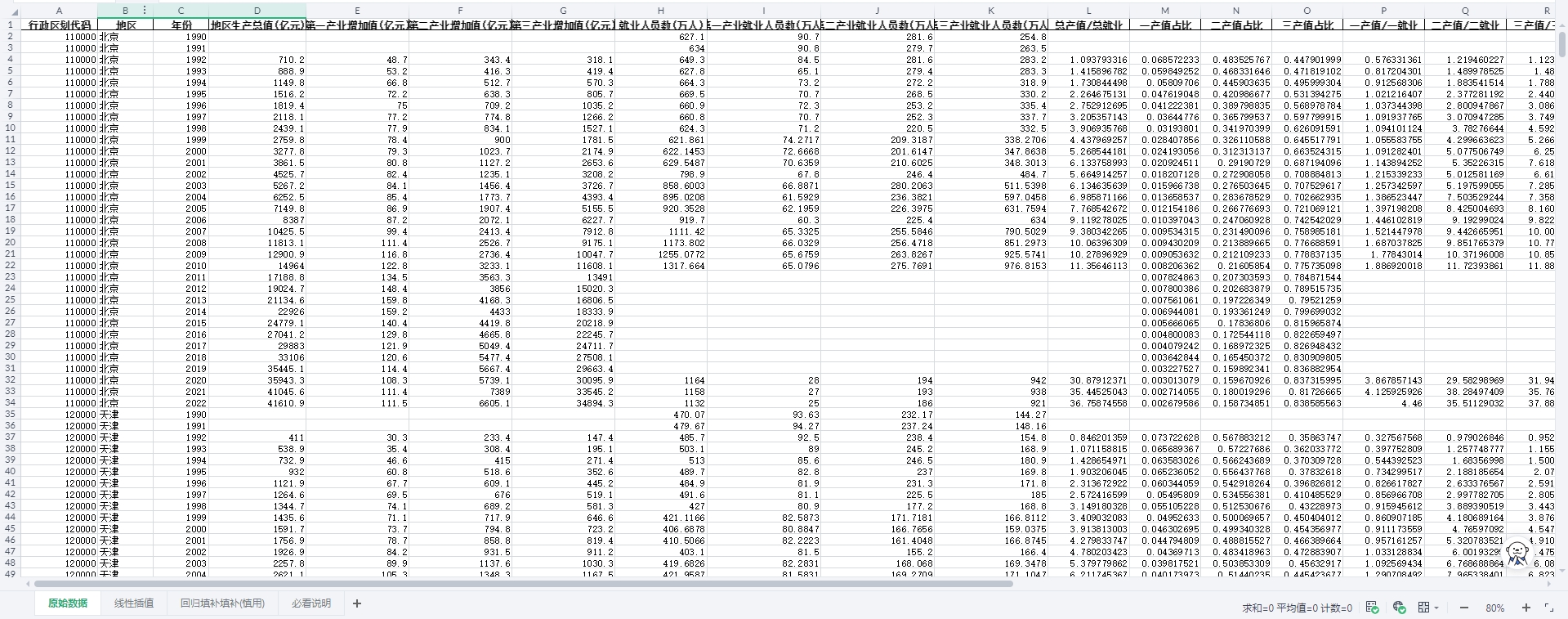
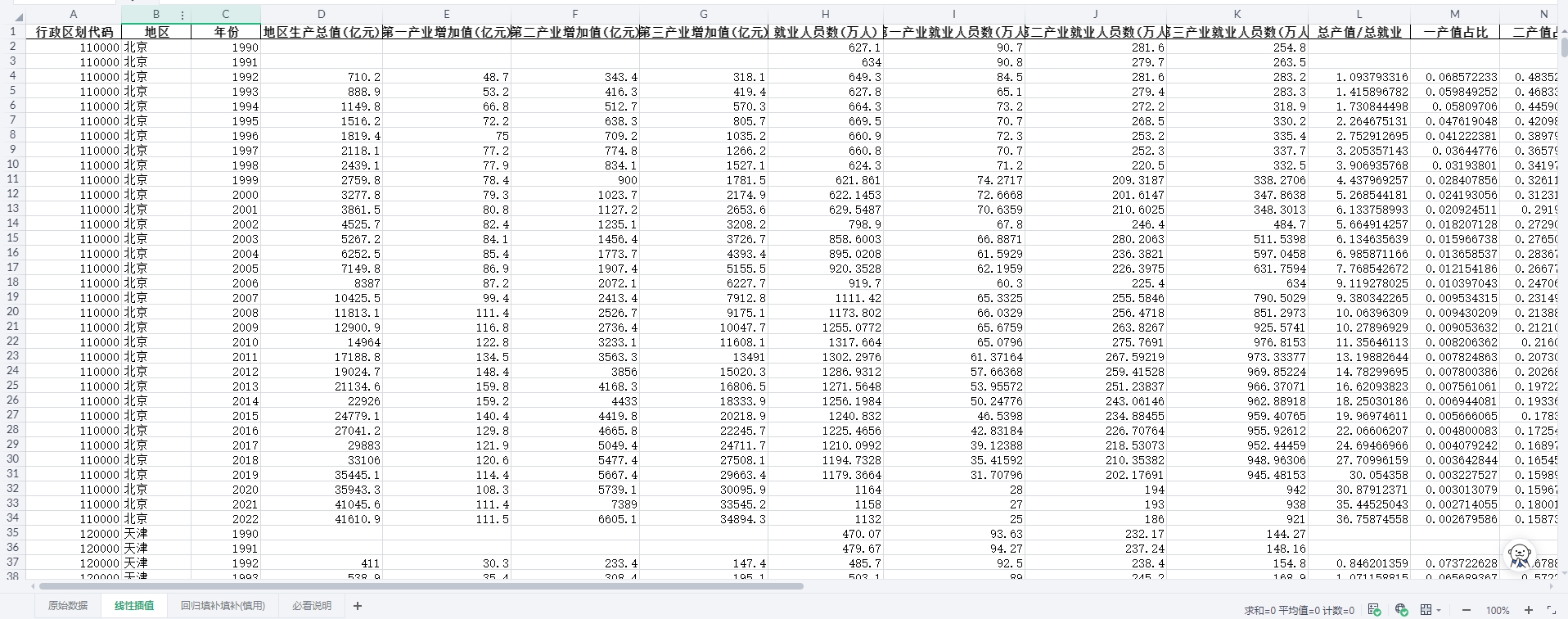
四、数据概览
包含字段:
| 行政区划代码 | 地区 | 年份 | 地区生产总值(亿元) | 第一产业增加值(亿元) | 第二产业增加值(亿元) | 第三产业增加值(亿元) | 就业人员数(万人) | 第一产业就业人员数(万人) | 第二产业就业人员数(万人) | 第三产业就业人员数(万人) | 总产值/总就业 | 一产值占比 | 二产值占比 | 三产值占比 | 一产值/一就业 | 二产值/二就业 | 三产值/三就业 | (一产值/一就业) /(总产值/总就业) | (二产值/二就业) /(总产值/总就业) | (三产值/三就业) /(总产值/总就业) | 产业结构整体升级 | 产业结构合理化指数(泰尔) | 产业结构高级化指数 |
五、下载链接:https://download.csdn.net/download/li514006030/89252698
这篇关于产业结构-整体升级、合理化、高级化数据集(1990-2022年)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







