本文主要是介绍JVM(2)-指令重排、乱序、对象的内存分布,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 乱序问题,指令重排
问题抛出: DCL单例
package com.tzw.single;import static java.lang.Thread.sleep;public class SingleMode {private static volatile SingleMode singleMode;private int i = 9;private SingleMode(){}/*** 双重锁较验。* 可能会出现问题:* 由于乱序的问题,* singleMode = new SingleMode();在加载的时候,* 1 new* 2 调用构造方法* 3 赋默认值,此时i=0* 4 赋初始值,i=9* 5 将空间指向singleMode* 如果每次加载都按照这个顺序,是没有问题的。** 但是由于乱序的存在,将空间指向singleMode如果在赋值之前就执行* 那么当第一个线程正在加载这个对象的时候,赋默认值后,先将空间赋值给singleMode,半初始化状态* 第二个线程过来判断时singleMode就不为空,就将半初始化状态的对象返回。* 那么这两个线程获取的对象就不是同一个。** 解决办法:* 加 voletir 关键字* private static volatile SingleMode singleMode;** @return*/public static SingleMode getInstance(){if(singleMode!=null){return singleMode;}synchronized (SingleMode.class) {if (singleMode == null) {singleMode = new SingleMode();}}return singleMode;}
}1.1 对DCL单例模式的解释说明:
以上DCL单例,双重检查单例,引出指令重排问题。
singleMode = new SingleMode();
指令重排问题。到底是先给成员变量赋值初始化,还是先将new内存地址指向变量t。
- 如果是先初始化,在指向变量t。 这是正确的。这也是正常情况。
- 但是如果发生了指令重排,可能会先指向t,在初始化。相当于是半初始化状态。成员变量还没赋值成功。当其他线程来获取的时候就可能出现获取的这个单例对象是一个半初始化状态。
- 解决办法:利用volatile可以解决这个问题。
1.2 引发的两个问题:
问题1.什么是指令重排呢?
就是说我们在编写代码的时候是按照一定的顺序编写的。在翻译成指令后,理论上来说,jvm在运行的时候也是会按照我们的顺序去执行。
对于单线程来说,指令就是按照我们的变写顺序依次执行。不会指令重排。
但是当多线程的时候,为了提高性能,就会进行指令重排。
代码在JVM执行的时候,为了提高性能,编译器和处理器都会对代码编译后的指令进行重排序。
指令重排分3种:
1:编译器优化重排:
编译器的优化前提是在保证不改变单线程语义的情况下,对重新安排语句的执行顺序。
例如:
A a = new A();
int b = a.x;
int c = a.x;//这段代码编译器可能会进行优化,将int c=a.x变为下面:
int c = b;
2:指令并行重排:
如果代码中某些语句之间不存在数据依赖,处理器可以改变语句对应机器指令的顺序
如:int x = 10;int y = 5;对于这种x y之间没有数据依赖关系的,机器指令就会进行重新排序。
但是对于:int x = 10; int y = 5; int z = x+y;这种的,因为z和x y之间存在数据依赖(z=x+y)关系。在这种情况下,机器指令就不会把z排序在xy前面。
解释:
对于这种重排,指的是相互之间没有依赖的,指令就可能进行重排。
CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系。
3:内存系统的重排序,cpu的指令重排
通过之前的学习,我们知道了处理器和主内存之间还存在一二三级缓存。这些读写缓存的存在,使得程序的加载和存取操作,可能是乱序无章的。
问题2:为什么加上volatile就能解决这个问题?
volatile关键在在翻译成指令后,就是在volatile前后分别加了读写屏障, 具体详细见一下说明。
2. 硬件层的并发优化基础知识
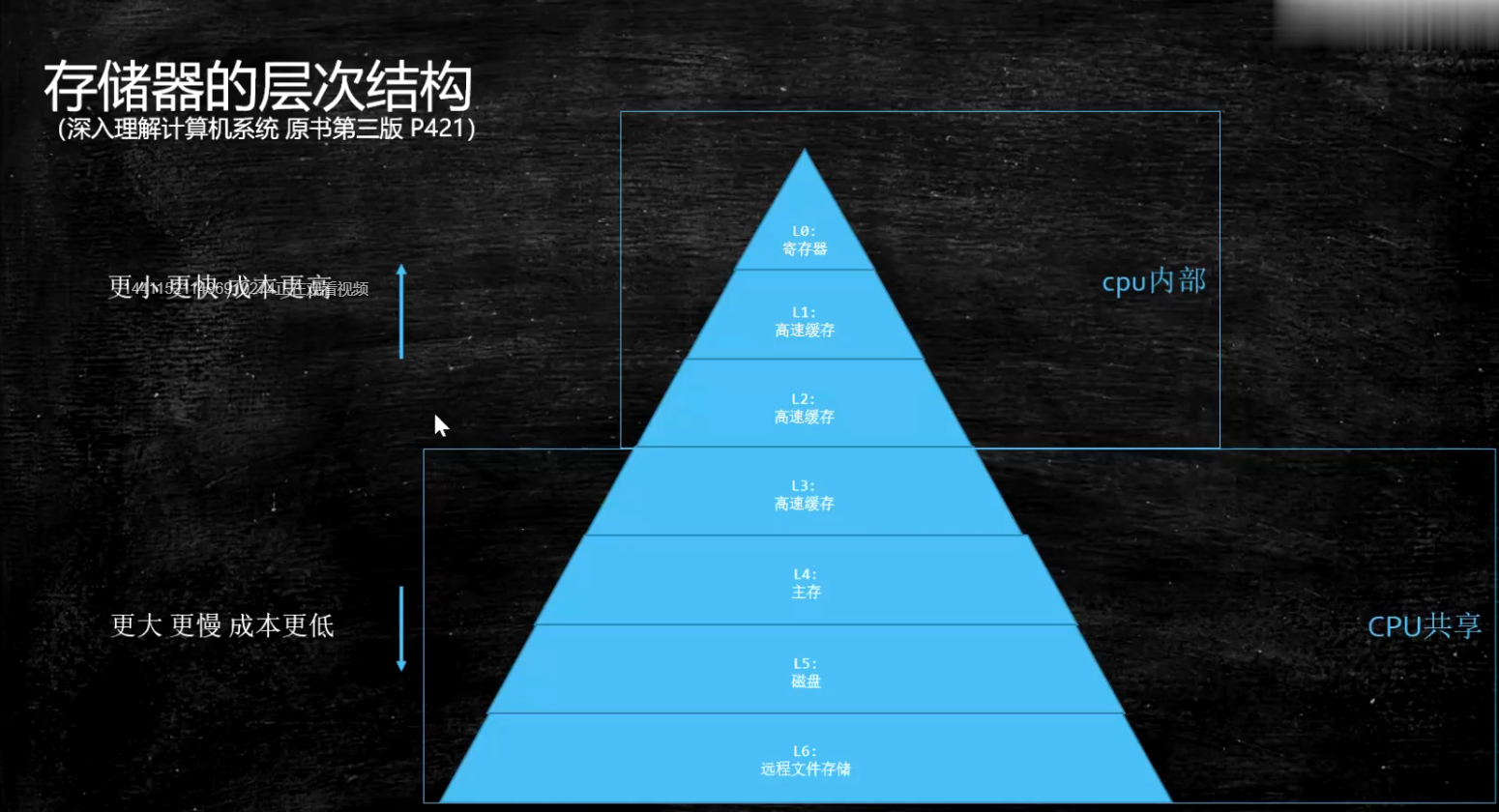
上图是对硬件上的存储层次。越往上执行越快。
CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系。
硬件层数据一致性 mesi catch一致性协议(inter) cpu每个cache line标记四种状态。缓存锁实现之一。
现代一致性的的实现 总线锁+缓存锁(mesi…)读取缓存 读取缓存以cache line为基本单位,目前64bytes
伪共享 位于同一缓存行的两个不同数据,被两个不同CPU锁定,产生互相影响的伪共享问题.
缓存行对齐方式能够提供伪共享带来的问题。
3. 乱序问题
CPU为了提高指令执行效率,会在一条指令执行过程中(比如去内存读数据(慢100倍)),去同时执行另一条指令,前提是,两条指令没有依赖关系。
写操作也可以进行合并。WriteCombining。wcBuffer缓冲区。比L1 L2效率高。但是只有4位。
当cpu往L2中写数据的同时,数据又进行了修改,则会在wcBuffer缓存中计算并合并到wcBuffer缓存中,当4位都占满时,一次性同步到L2中。效率快。
4. 如何保证在特定情况的有序性
4.1 硬件层面的有序性保障
硬件级别有序性保障,通过硬件的内存屏障或者原子指令,不同的硬件有不同的内存屏障。
- 内存屏障,在特定地方插入屏障,屏障两边的顺序不能乱。
inter 的cpu比较简单,X86的内存屏障:
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。 lfence:load |
在lfence指令前的读操作当必须在lfence指令后的读操作前完成。 mfence:modify/mix |
在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
- 原子指令
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
4.2. JVM级别如何规范
四类屏障
LoadLoad屏障:
StoreStore屏障:
LoadStore屏障:
StoreLoad屏障:
备注:load可以理解为读,store理解为写。
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2,
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2,
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
4.3 volatile的实现细节
volatile到底是怎么实现的呢?
-
字节码层面
在字节码上就是加了一个 ACC_VOLATILE标记。 -
JVM层面
然后jvm会在ACC_VOLATILE前后加屏障。
volatile内存区的读写 都加屏障。
写操作,前加StoreStore屏障。后加StoreLoad屏障
读操作,前加LoadLoad屏障。后加LoadStore屏障StoreStoreBarrier
volatile 写操作
StoreLoadBarrierLoadLoadBarrier
volatile 读操作
LoadStoreBarrier -
OS和硬件层面
在硬件时,则是在最后加一个lock指令(锁住一个指令)进行实现。https://blog.csdn.net/qq_26222859/article/details/52235930
hsdis - HotSpot Dis Assembler
windows lock 指令实现 | MESI实现
4.4 synchronized的具体实现
synchronized实现细节
-
字节码层面
ACC_SYNCHRONIZED
monitorenter monitorexit -
JVM层面
C C++ 调用了操作系统提供的同步机制 -
OS和硬件层面
X86 : lock cmpxchg / xxx
5. 对象的内存布局
5.1 通过命令观察jvm虚拟机配置
java -XX:+PrintCommandLineFlags -version
执行结果:
-XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
openjdk version "1.8.0_302"
OpenJDK Runtime Environment (Zulu 8.56.0.23-CA-macos-aarch64) (build 1.8.0_302-b08)
OpenJDK 64-Bit Server VM (Zulu 8.56.0.23-CA-macos-aarch64) (build 25.302-b08, mixed mode)
5.2. 回忆一下对象的创建过程
创建一个Object对象:Object obj = new Object()
-
loading
-
linking(verification,preparation,resoulusion)
- Verification 验证问津是否符合JVM规定
- Preparation 静态成员变量赋默认值。
- Resolution 就是将符合引用变成真实的地址指针,指向真正的地址
将类、方法、属性等符号引用解析为直接引用
换句话说,就是常量池中的各种符合引用解析为指针,偏移量的内存地址直接引用
- initializing
调用类初始化代码 ,给静态成员变量赋初始值
- new 申请对象内存
- 成员变量赋默认值
- 调用构造方法。
成员变量顺序赋初始值。执行构造方法方法体,第一步就是调用父类,super()。
5.3. 对象在内存中的存储布局
5.3.1普通对象
T t = new T() 会在内存中开辟一个空间,就是占一块内存。这个内存中分一下几部分:
- 对象头:在hotSpot中称为markword 8字节
- ClassPointer指针: new出来的这个对象属于那个Class的,这个指针指Class对象,执行t.class获取的Class对象。
-XX:+UseCompressedClassPointers 开启压缩的意思。开启压缩,则会被压缩成4个字节。不开启压缩是8个字节 - 实例数据,指成员变量
引用类型,如果String,就是指向引用。
如果是int m=1;就会有存储m。
-XX:+UseCompressedOops。开启压缩的意思。开启压缩,则会被压缩成4个字节。不开启压缩是8个字节,基础类型,就是i=8. - Padding对齐。
为保证对象长度8的倍数,padding自动补齐。读取时是按块读取,一次读取16个,速度快。
5.3.2 数组对象
- 对象头:在hotSpot中称为markword 8字节
- ClassPointer指针: 这个指针指向class对象,执行t.class对象。
- 数组长度,比普通数据多了一个长度。
- 数组数据
- Padding对齐,为保证对象长度8的倍数,padding自动补齐。读取时是按快读取,一次读取16个,速度快。
5.3.2 对象的长度到底是多大呢?
通过javaAgent代理。在创建一个对象的过程中,通过Agent代理截获这个对象,获取这个对象的大小。
5.3.3. 对象头到底是什么
对象头结构总结:
下图表格其实是32位的图(25hasCode+4+3=32)。64类似(没有使用的25位+31位hasCode+4+1(没有使用)+3=64)。
- 对象头一共是8个字节,共64位。不同的jvm有不同的实现。有些就是32位。
以下是32位说明: - 对象在不同的状态,对象头的情况都不一样。
无锁态: 25 位存储hashCode, 4 位用来存储分代年龄,1位存储是否偏移锁,2位存储锁标志。
其他状态如图:
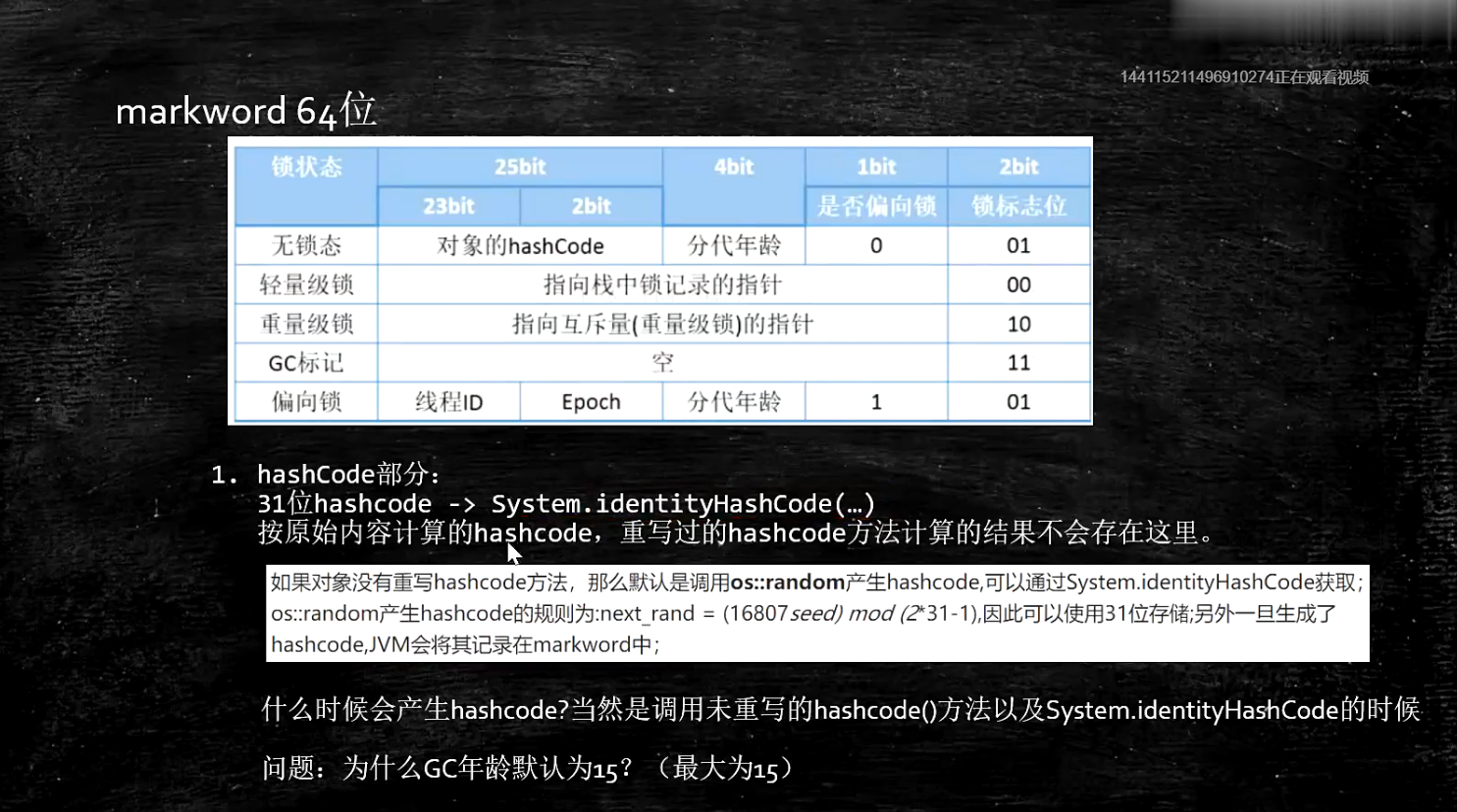
32 位和64位比较
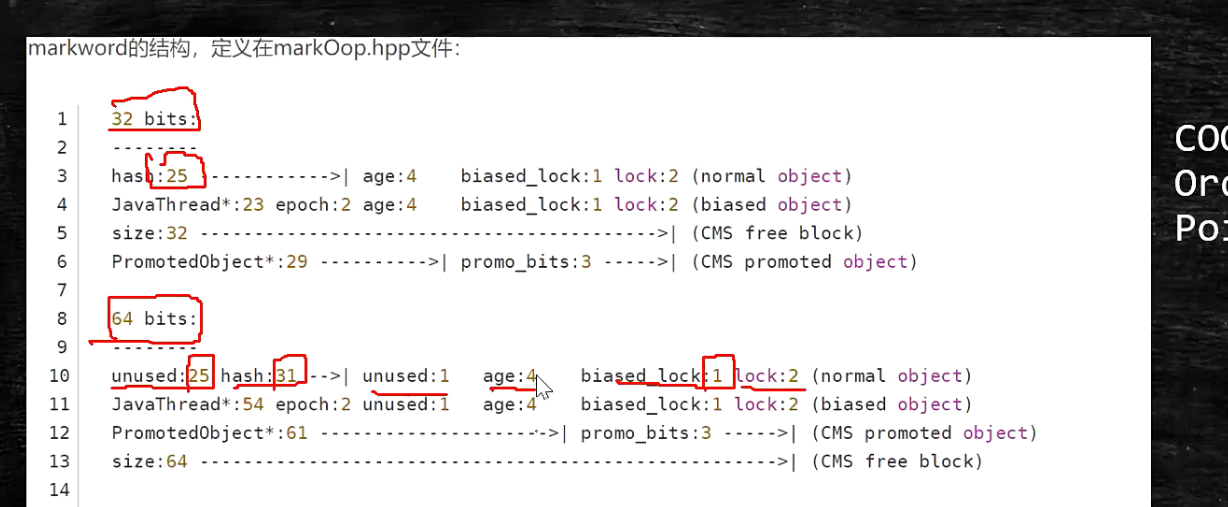
- 两问题
(1)已经计算过hashcode的对象,是否可以进入偏向锁状态?
答案是不能的。因为计算过hashCode,那么前25位已经存储了hashCode,不能再用来存储线程ID,Epoch等,所以不能。
(2)为什么说GC年龄默认为15.(最大是15)?
因为分代年龄在对象头中占4位,最大就是1111,换成10进制,就是15.
6. 对象定位,怎么获取对象的位置?
例如:T t = new T(); t是怎么找到new 的对象呢?
两种方式:
-
句柄池
使用时效率低,但是GC时效率高
t 同时指向两个指针,一个是指向new对象T,一个是T对应的class对象
t----> new T()
t-----> T.class -
直接指针(Hospot jvm是这么实现的)
t 直接指向new 对象T,而T对象指向T对象的Class对象。通过pointClass指针,具体见上述 对象在内存中的存储布局。
t------>new T()
new T()------>T.class
这篇关于JVM(2)-指令重排、乱序、对象的内存分布的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





