本文主要是介绍一张图轻松掌握 Flink on YARN 基础架构与启动流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Flink on YARN 应用启动流程图
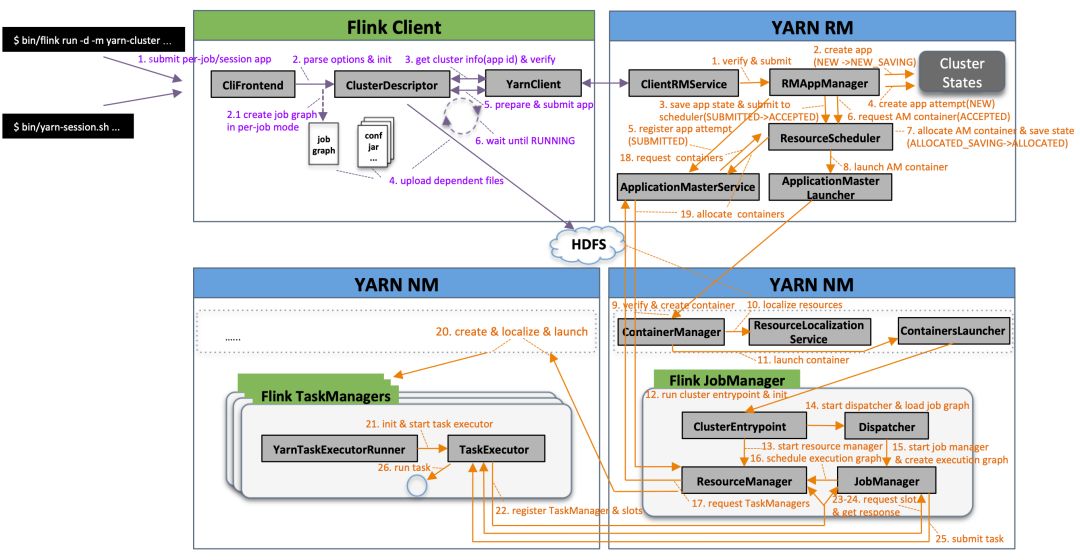
客户端提交流程
1.执行命令:bin/flink run -d -m yarn-cluster ...或bin/yarn-session.sh ...来提交 per-job 运行模式或 session 运行模式的应用;
2.解析命令参数项并初始化,启动指定运行模式,如果是 per-job 运行模式将根据命令行参数指定的 Job 主类创建 job graph;
如果可以从命令行参数(-yid <APPLICATION_ID>)或 YARN properties 临时文件(${java.io.tmpdir}/.yarn-properties-${user.name})中获取应用 ID,向指定的应用中提交 Job;
否则当命令行参数中包含 -d(表示detached模式)和 -m yarn-cluster(表示指定 YARN 集群模式),启动 per-job 运行模式;
否则当命令行参数项不包含 -yq(表示查询YARN集群可用资源)时,启动 session 运行模式;
3.获取 YARN 集群信息、新应用 ID 并启动运行前检查;
通过 YarnClient 向 YARN ResourceManager (下文缩写为:YARN RM,YARN Master 节点,负责整个集群资源的管理和调度)请求创建一个新应用(YARN RM 收到创建应用请求后生成新应用 ID 和 container 申请的资源上限后返回),并且获取 YARN Slave 节点报告(YARN RM 返回全部 slave 节点的 ID、状态、rack、http 地址、总资源、已使用资源等信息);
运行前检查:(1) 简单验证YARN集群能否访问;(2) 最大 node 资源能否满足 flink JobManager/TaskManager vcores 资源申请需求;(3) 指定 queue 是否存在(不存在也只是打印WARN信息,后续向YARN提交时排除异常并退出);(4)当预期应用申请的Container资源会超出YARN资源限制时抛出异常并退出;(5) 当预期应用申请不能被满足时(例如总资源超出YARN集群可用资源总量、Container申请资源超出NM可用资源最大值等)提供一些参考信息。
4.将应用配置(flink-conf.yaml、logback.xml、log4j.properties)和相关文件(flink jars、ship files、user jars、job graph等)上传至分布式存储(例如 HDFS)的应用暂存目录(/user/${user.name}/.flink/);
5.准备应用提交上下文(ApplicationSubmissionContext,包括应用的名称、类型、队列、标签等信息和应用 Master 的 container 的环境变量、classpath、资源大小等),注册处理部署失败的 shutdown hook(清理应用对应的 HDFS 目录),然后通过 YarnClient 向 YARN RM 提交应用;
6.循环等待直到应用状态为 RUNNING,包含两个阶段:
循环等待应用提交成功(SUBMITTED):默认每隔 200ms 通过 YarnClient 获取应用报告,如果应用状态不是 NEW 和 NEW_SAVING 则认为提交成功并退出循环,每循环 10 次会将当前的应用状态输出至日志:"Application submission is not finished, submitted application <APPLICATION_ID> is still in <APP_STATE>",提交成功后输出日志:"Submitted application <APPLICATION_ID>"
循环等待应用正常运行(RUNNING):每隔 250 ms 通过 YarnClient 获取应用报告,每轮循环也会将当前的应用状态输出至日志:"Deploying cluster, current state <APP_STATE>"。应用状态成功变为 RUNNING 后将输出日志"YARN application has been deployed successfully."并退出循环,如果等到的是非预期状态如 FAILED/FINISHED/KILLED,就会在输出 YARN 返回的诊断信息("The YARN application unexpectedly switched to state <APP_STATE> during deployment. Diagnostics from YARN: ...")之后抛出异常并退出。
Flink Cluster 启动流程
1.YARN RM 中的 ClientRMService(为普通用户提供的 RPC 服务组件,处理来自客户端的各种 RPC 请求,比如查询 YARN 集群信息,提交、终止应用等)接收到应用提交请求,简单校验后将请求转交给 RMAppManager(YARN RM 内部管理应用生命周期的组件);
2.RMAppManager 根据应用提交上下文内容创建初始状态为 NEW 的应用,将应用状态持久化到 RM 状态存储服务(例如 ZooKeeper 集群,RM 状态存储服务用来保证 RM 重启、HA 切换或发生故障后集群应用能够正常恢复,后续流程中的涉及状态存储时不再赘述),应用状态变为 NEW_SAVING;
3.应用状态存储完成后,应用状态变为 SUBMITTED;RMAppManager 开始向 ResourceScheduler(YARN RM 可拔插资源调度器,YARN 自带三种调度器 FifoScheduler/FairScheduler/CapacityScheduler,其中 CapacityScheduler 支持功能最多使用最广泛,FifoScheduler 功能最简单基本不可用,今年社区已明确不再继续支持 FairScheduler,建议已有用户迁至 CapacityScheduler)提交应用,如果无法正常提交(例如队列不存在、不是叶子队列、队列已停用、超出队列最大应用数限制等)则抛出拒绝该应用,应用状态先变为 FINAL_SAVING 触发应用状态存储流程并在完成后变为 FAILED;如果提交成功,应用状态变为 ACCEPTED;
4.开始创建应用运行实例(ApplicationAttempt,由于一次运行实例中最重要的组件是 ApplicationMaster,下文简称 AM,它的状态代表了 ApplicationAttempt 的当前状态,所以 ApplicationAttempt 实际也代表了AM),初始状态为 NEW;
5.初始化应用运行实例信息,并向 ApplicationMasterService(AM&RM 协议接口服务,处理来自 AM 的请求,主要包括注册和心跳)注册,应用实例状态变为 SUBMITTED;
6.RMAppManager 维护的应用实例开始初始化 AM 资源申请信息并重新校验队列,然后向 ResourceScheduler 申请 AM Container(Container 是 YARN 中资源的抽象,包含了内存、CPU 等多维度资源),应用实例状态变为 ACCEPTED;
7.ResourceScheduler 会根据优先级(队列/应用/请求每个维度都有优先级配置)从根队列开始层层递进,先后选择当前优先级最高的子队列、应用直至具体某个请求,然后结合集群资源分布等情况作出分配决策,AM Container 分配成功后,应用实例状态变为 ALLOCATED_SAVING,并触发应用实例状态存储流程,存储成功后应用实例状态变为 ALLOCATED;
8.RMAppManager 维护的应用实例开始通知 ApplicationMasterLauncher(AM 生命周期管理服务,负责启动或清理 AM container)启动 AM container,ApplicationMasterLauncher 与 YARN NodeManager(下文简称 YARN NM,与 YARN RM 保持通信,负责管理单个节点上的全部资源、Container 生命周期、附属服务等,监控节点健康状况和 Container 资源使用)建立通信并请求启动 AM container;
9.ContainerManager(YARN NM 核心组件,管理所有 Container 的生命周期)接收到 AM container 启动请求,YARN NM 开始校验 Container Token 及资源文件,创建应用实例和 Container 实例并存储至本地,结果返回后应用实例状态变为 LAUNCHED;
10.ResourceLocalizationService(资源本地化服务,负责 Container 所需资源的本地化。它能够按照描述从 HDFS 上下载 Container 所需的文件资源,并尽量将它们分摊到各个磁盘上以防止出现访问热点)初始化各种服务组件、创建工作目录、从 HDFS 下载运行所需的各种资源至 Container 工作目录(路径为: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/<APPLICATION_ID>/<CONTAINER_ID>);
11.ContainersLauncher(负责container的具体操作,包括启动、重启、恢复和清理等)将待运行 Container 所需的环境变量和运行命令写到 Container 工作目录下的 launch_container.sh 脚本中,然后运行该脚本启动 Container;
12.Container 进程加载并运行 ClusterEntrypoint(Flink JobManager 入口类,每种集群部署模式和应用运行模式都有相应的实现,例如在 YARN 集群部署模式下, per-job 应用运行模式实现类是 YarnJobClusterEntrypoint,session 应用运行模式实现类是 YarnSessionClusterEntrypoint),首先初始化相关运行环境:
输出各软件版本及运行环境信息、命令行参数项、classpath 等信息;
注册处理各种 SIGNAL 的 handler :记录到日志
注册 JVM 关闭保障的 shutdown hook:避免 JVM 退出时被其他 shutdown hook 阻塞打印 YARN 运行环境信息:用户名
从运行目录中加载 flink conf
初始化文件系统
创建并启动各类内部服务(包括 RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore 等)
将 RPC address 和 port 更新到 flink conf 配置
13.启动 ResourceManager(Flink 资源管理核心组件,包含 YarnResourceManager 和 SlotManager 两个子组件,YarnResourceManager 负责外部资源管理,与 YARN RM 建立通信并保持心跳,申请或释放 TaskManager 资源,注销应用等;SlotManager 则负责内部资源管理,维护全部 Slot 信息和状态)及相关服务,创建异步 AMRMClient,开始注册 AM,注册成功后每隔一段时间(心跳间隔配置项:${yarn.heartbeat.interval},默认 5s)向 YARN RM 发送心跳来发送资源更新请求和接受资源变更结果。YARN RM 内部该应用和应用运行实例的状态都变为 RUNNING,并通知 AMLivelinessMonitor 服务监控 AM 是否存活状态,当心跳超过一定时间(默认 10 分钟)触发 AM failover 流程;
14.启动 Dispatcher(负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager)及相关服务(包括 REST endpoint 等),在 per-job 运行模式下,Dispatcher 将直接从 Container 工作目录加载 JobGraph 文件;在 session 运行模式下,Dispatcher 将在接收客户端提交的 Job(_通过 BlockServer 接收 job graph 文件)后再进行后续流程;
15.根据 JobGraph 启动 JobManager(负责作业调度、管理 Job 和 Task 的生命周期),构建 ExecutionGraph(JobGraph 的并行化版本,调度层最核心的数据结构);
16.JobManager 开始执行 ExecutionGraph,向 ResourceManager 申请资源;
17.ResourceManager 将资源请求加入等待请求队列,并通过心跳向 YARN RM 申请新的 Container 资源来启动 TaskManager 进程;后续流程如果有空闲 Slot 资源,SlotManager 将其分配给等待请求队列中匹配的请求,不用再通过 18. YarnResourceManager 申请新的 TaskManager;
18.YARN ApplicationMasterService 接收到资源请求后,解析出新的资源请求并更新应用请求信息;
19.YARN ResourceScheduler 成功为该应用分配资源后更新应用信息,ApplicationMasterService 接收到 Flink JobManager 的下一次心跳时返回新分配资源信息;
20.Flink ResourceManager 接收到新分配的 Container 资源后,准备好 TaskManager 启动上下文(ContainerLauncherContext,生成 TaskManager 配置并上传至分布式存储,配置其他依赖和环境变量等),然后向 YARN NM 申请启动 TaskManager 进程,YARN NM 启动 Container 的流程与 AM Container 启动流程基本类似,区别在于应用实例在 NM 上已存在并未 RUNNING 状态时则跳过应用实例初始化流程,这里不再赘述;
21.TaskManager 进程加载并运行 YarnTaskExecutorRunner(Flink TaskManager入口类),初始化流程完成后启动 TaskExecutor(负责执行Task相关操作);
22.TaskExecutor 启动后先向 ResourceManager 注册,成功后再向 SlotManager 汇报自己的 Slot 资源与状态;SlotManager 接收到 Slot 空闲资源后主动触发 Slot 分配,从等待请求队列中选出合适的资源请求后,向 TaskManager 请求该 Slot 资源
23.TaskManager 收到请求后检查该 Slot 是否可分配(不存在则返回异常信息)、 Job 是否已注册(没有则先注册再分配 Slot),检查通过后将 Slot 分配给 JobManager;
24.JobManager 检查 Slot 分配是否重复,通过后通知 Execution 执行部署 task 流程,向 TaskExecutor 提交 task;TaskExecutor 启动新的线程运行 Task。
参考资料
Flink Release-1.9 SourceCode
https://github.com/apache/flink/tree/release-1.9.0
Flink Release-1.9 Documents
FLIP-6 - Flink Deployment and Process Model - Standalone, Yarn, Mesos, Kubernetes, etc.
YARN 3.2 SourceCode
YARN 3.2.0 Documents
上文对 Flink on YARN 应用启动全流程进行了梳理,下篇内容会根据社区大群反馈,解答客户端和 Flink Cluster 的常见问题,分享相关问题的排查思路,敬请期待!

11 月 28-30 日,Flink Forward Asia 2019 核心技术专场,届时 Apache Flink 核心贡献者们将与多位来自一线的业界资深专家带你全方位解锁 Flink 核心技术。购票及了解更多大会详情请扫描下下图二维码。
(11月28日下午,专场议程)
(11月29日上午,专场议程)
这篇关于一张图轻松掌握 Flink on YARN 基础架构与启动流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






