本文主要是介绍Pulsar 和 Kafka 架构对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文作者是 David Kjerrumgaard,目前任职于 Splunk,Apache Pulsar 和 Apache NiFi 项目贡献者。译者为 Sijia@StreamNative。原文链接:https://searchdatamanagement.techtarget.com/post/Apache-Pulsar-vs-Kafka-and-other-data-processing-technologies,翻译已获授权。
关于 Apache Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
GitHub 地址:http://github.com/apache/pulsar/
相比于 Kafka 等数据处理中间件,分布式消息平台 Apache Pulsar 如何存储数据?本文基于架构,对比了 Apache Kafka 等传统数据处理中间件和分布式消息平台 Apache Pulsar 的优劣势,供大家参考。
存储可扩展
Apache Pulsar 的多层架构将消息服务层与存储层完全解耦,从而使各层可以独立扩展。传统的分布式数据处理中间件(如 Hadoop、Spark)则在同一集群节点/实例上处理和存储数据。这种设计可以降低通过网络进行传输的数据量,使得架构更简洁,性能也有所提升,但同时扩展性、弹性、运维受到了影响。
Pulsar 的分层架构在云原生解决方案中独树一帜。如今,大幅提升的网络带宽为此架构提供了坚实基础,有利于计算和存储的分离。Pulsar 的架构将服务层与存储层解耦:无状态 broker 节点负责数据服务;bookie 节点负责数据存储(如图 1)。
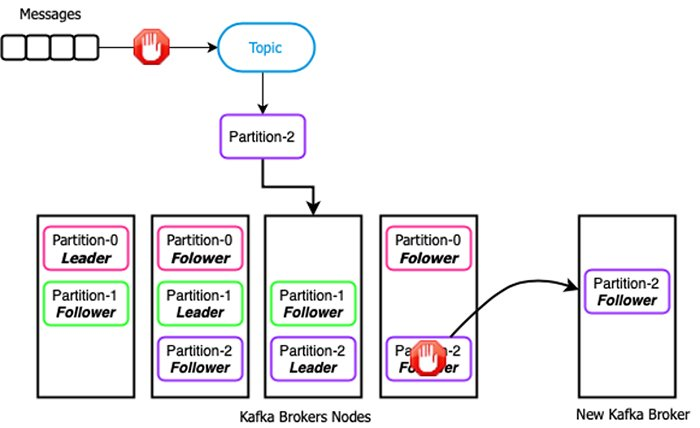
图 1. 服务层与存储层解耦
服务层与存储层解耦的架构有很多优势。首先,各层都可以弹性扩展,彼此之间互不影响。借助云和容器等环境的弹性能力,各层可以自动扩缩容,动态适应流量高峰。其次,通过显著降低集群扩展和升级复杂性,提高了系统可用性和可管理性。再次,这种设计还属于容器友好型设计,使 Pulsar 成为托管云原生流系统的最佳方案。Apache Pulsar 使用高可扩展的 BookKeeper 作为存储层,实现了强大的持久保证与分布式数据存储和复制,并原生支持跨地域复制。
多层设计可以轻松实现分层存储,从而可以将访问频率较低的数据卸载到低成本的持久化存储(如 AWS S3、Azure 云)中。Pulsar 支持配置预定义的存储大小或时间段,自动将存储在本地磁盘的数据卸载至云存储平台,释放本地磁盘,同时安全备份事件数据。
Pulsar vs. Kafka
Apache Pulsar 和 Apache Kafka 都具有类似的消息传递概念。客户端通过 topic(逻辑上分为多个分区)与二者进行交互。通常而言,写入 topic 的无限数据流会被分为分区(特定数量、大小相等的分组),从而使数据均匀分布在系统中,并被多个客户端同时使用。
Apache Pulsar 和 Apache Kafka 之间的本质区别在于存储分区的基础架构。Apache Kafka 是基于分区的发布/订阅系统,旨在作为整体架构运行,服务层和存储层位于同一节点上。

图 2. Kafka 分区
Kafka 存储:基于分区
在 Kafka 中,分区数据作为 leader 节点上的单个连续数据存储,然后复制到副本节点上(副本节点可预配置),实现数据多副本。这种设计通过两种方式限制了分区的容量,并扩展了 topic。首先,由于分区只能存储在本地磁盘中,分区大小取决于主机上最大的单个磁盘大小(“新”安装用户的磁盘大小约为 4 TB);其次,由于必须复制数据,所以分区的大小不能超过副本节点上最小磁盘空间的大小。

图 3. Kafka 故障和扩容
假设可以将 leader 存储在新节点上,磁盘大小为 4 TB 且只用于分区存储,两个副本节点的存储容量都为 1 TB 。在向 topic 发布 1 TB 数据后,Kafka 将检测到副本节点无法继续接收数据,并且在副本节点释放空间之前,不能继续向该 topic 发布消息(如图 3)。如果 producer 在中断期间无法缓冲消息,则可能会造成数据丢失。
面对这一问题,有两种解决方案:删除磁盘上的数据,存储现有副本节点,但由于来自其他 topic 的数据可能还没有被消费,可能会导致数据丢失;或为 Kafka 集群添加新节点并“重平衡”分区,将新增节点用作副本节点。但是这需要重新复制整个 1 TB 的分区,耗时、易出错,对网络带宽和磁盘 IO 要求高,且代价高昂。此外,对于具有严格 SLA 的程序而言,离线复制的方案并不可取。
使用 Kafka,不仅在扩展集群时需要重新复制分区数据,其他故障也可能需要重新复制分区数据,如副本故障、磁盘故障、计算机故障等。如果没有在生产环境中出现故障,我们通常会忽视 Kafka 的这一弊端。
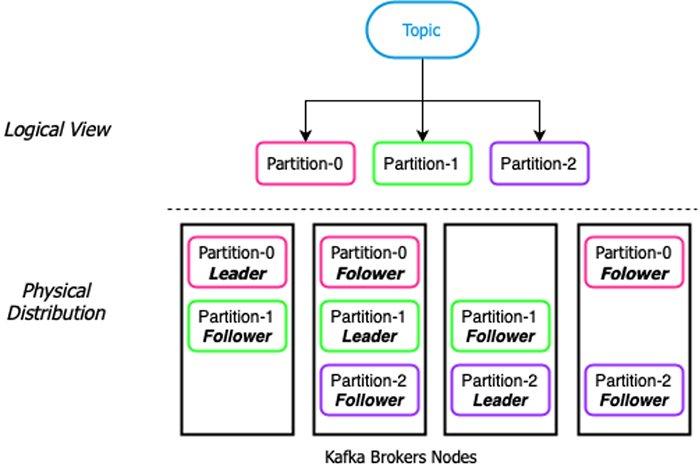
图 4. Pulsar 分片
Pulsar 存储:基于分片
在基于分片的存储架构(如 Apache Pulsar 使用的架构)中,分区被进一步分成分片,可以根据预先配置的时间或大小进行滚动。分片均匀分布在存储层的 bookie 中,实现数据多副本和扩容。
当 bookie 磁盘空间用尽,不能继续向其中写入数据时,Kafka 需要重新复制数据,Pulsar 如何应对这种场景呢?由于分区被进一步分成分片,因此无需复制整个 bookie 的内容到新增 bookie 中。在添加新 bookie 前,Pulsar 可以继续接收新数据分片,并写入存储容量未满的 bookie 中。添加新 bookie 时,新节点和新分区上的流量立即自动增加,无需重新复制旧数据。
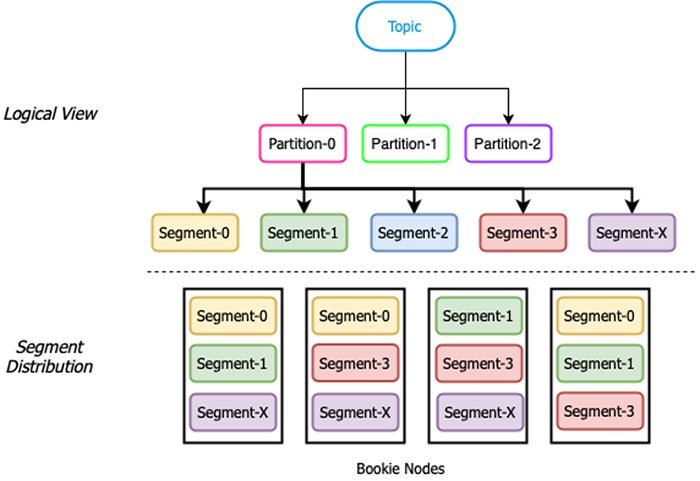
图 5. Pulsar 故障和扩容
如图 5 所示,在第 4 个 bookie 节点不再继续接收新消息分片时,消息分片 4-7 被路由到其他活跃 bookie 上。新增 bookie 后,分片自动被路由到新 bookie 上。整个过程中,Pulsar 始终在运行,并且可以为 producer 和 consumer 提供服务。在这种情况下,Pulsar 的存储系统更加灵活,高可扩展。
这篇关于Pulsar 和 Kafka 架构对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






