本文主要是介绍大白话 Manacher算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Manacher 算法
Manacher 算法简介
Manacher 算法用于解决字符串中最长回文子串最大长度问题。
解释一下:
-
回文:这个很好理解了,就是字符串正序和逆序是相同的
-
字符串长度为奇数时,该回文字符串一定会有个中心对称轴,例如 “abcba” 关于中间的 ‘c’ 左右对称
-
字符串长度为偶数时,只有一个虚拟的对称轴,例如"abba",只需要左右相同即可。
-
-
子串:字符串中连续的字符序列
- 一定注意了,必须得是连续的,例如对于字符串 “abcde”,“abc”、“bcd”…都是它的子串,但是类似"abd"、"ace"这种就不是它的子串了。
例如:
str=“123”,其中的最长回文子串为"1"、“2"或者"3”,所以返回 1。
str=“abbac”,其中的最长回文子串为"aabb",所以返回 4。
str=“abc1234321ab”,其中的最长回文子串为"1234321",所以返回 7。
整体思路
从左到右遍历字符串,遍历到每个字符的时候,都看看以这个字符作为中心能够产生多大的回文字符串。比如 str=“abacaba”,以 str[0]=='a’为中心的回文字符串最大长度为 1,以 str[1]==‘b’ 为中心的回文字符串最大长度为 3,……其中最大的回文子串是以 str[3]=='c’为中心的时候。
字符串预处理
上面的处理方式中会有一个问题,当回文字符串长度为偶数时,由于没有实际存在的中心轴,就没有办法通过上面方式求解了。
我们可以通过填充值的方式来避免出现偶数的回文串,可以对str 进行处理,把每个字符开头、结尾和中间插入一个特殊字符’#'来得到一个新的字符串数组。比如 str=“bcbaa”,处理后为"#b#c#b#a#a#",然后从每个字符左右扩出去的方式找最大回文子串就方便多了。
-
对奇回文来说,不这么处理也能通过扩的方式找到,比如"bcb",从’c’开始向左右两侧扩出去能找到最大回文。处理后为"#b#c#b#",从’c’开始向左右两侧扩出去依然能找到最大回文。
-
对偶回文来说,不处理而直接通过扩的方式是找不到的,比如"aa",因为没有确定的轴,但是处理后为"#a#a#",就可以通过从中间的’#'扩出去的方式找到最大回文。
代码如下
private static char[] manacherString(String s) {char[] chars = s.toCharArray();int n = (chars.length << 1) + 1;char[] ans = new char[n];int index = 0;for (int i = 0; i < n; i++) {ans[i] = (i & 1) == 0 ? '#' : chars[index++];}return ans;}
几个概念
假设 str 处理之后的字符串记为 charArr。对每个字符(包括特殊字符)都进行“优化后”的扩充过程。
为了后面能更加方便地介绍 Manacher 算法,这里先介绍几个概念。
回文半径
由于charArr中回文串长度都是奇数,那么它一定会有一个中心对称轴,回文半径就是该中心对称轴到两端的距离(包括端点)。
例如,对于"#a#b#c#b#a#",它中心为 ‘c’,中心点+左边是 “#a#b#c”,中心点+右边是 “c#b#a#”,它们的长度都是6,因此回文半径长度是6。可以看到,如果还原为原始字符串,那么原始字符串的长度为5,因此原始回文字符串长度=回文半径-1。
再比如,对于"#a#b#b#a#",它中心为正中间的 ‘#’,中心点+左边是 “#a#b#”,中心点+右边是 “#b#a#”,它们的长度都是5,因此回文半径长度是5。可以看到,如果还原为原始字符串,那么原始字符串的长度为4,因此也有原始回文字符串长度=回文半径-1。
所以,无论原始回文字符串长度为奇数还是偶数,它的长度都是扩展后回文半径-1。
回文半径数组pArr
长度与 charArr 长度一样。
pArr[i]的意义是以 i 位置上的字符(charArr[i])作为回文中心的情况下,扩出去得到的最大回文半径是多少。
举例说明,对"#c#a#b#a#c#"来说,pArr[0…9]为[1,2,1,2,1,6,1,2,1,2,1]。整个过程就是在从左到右遍历的过程中,依次计算每个位置的最大回文半径值。
最右扩展位置pR及对应中心c
这个变量的意义是之前遍历的所有字符的所有回文半径中,最右即将到达的位置。
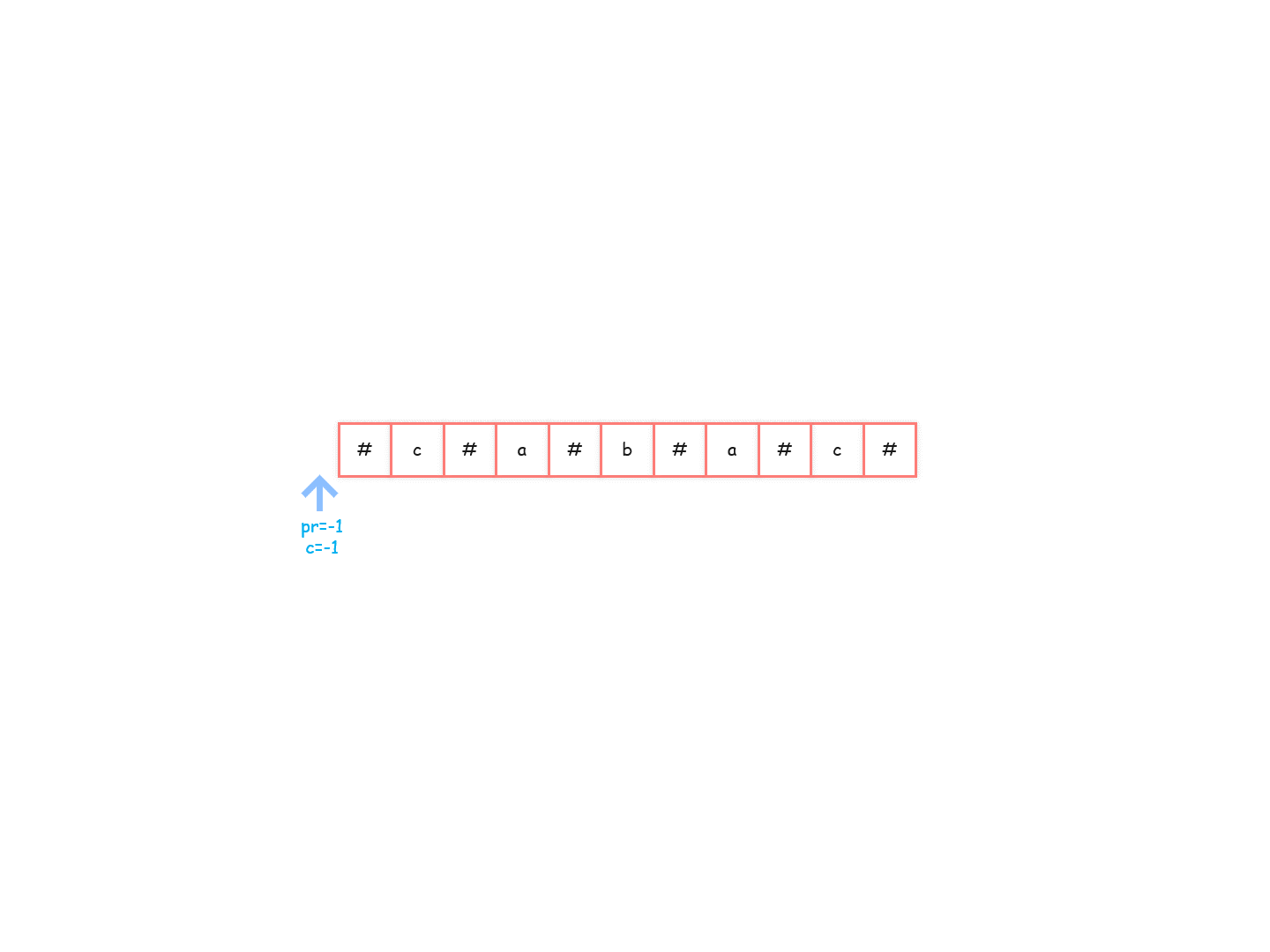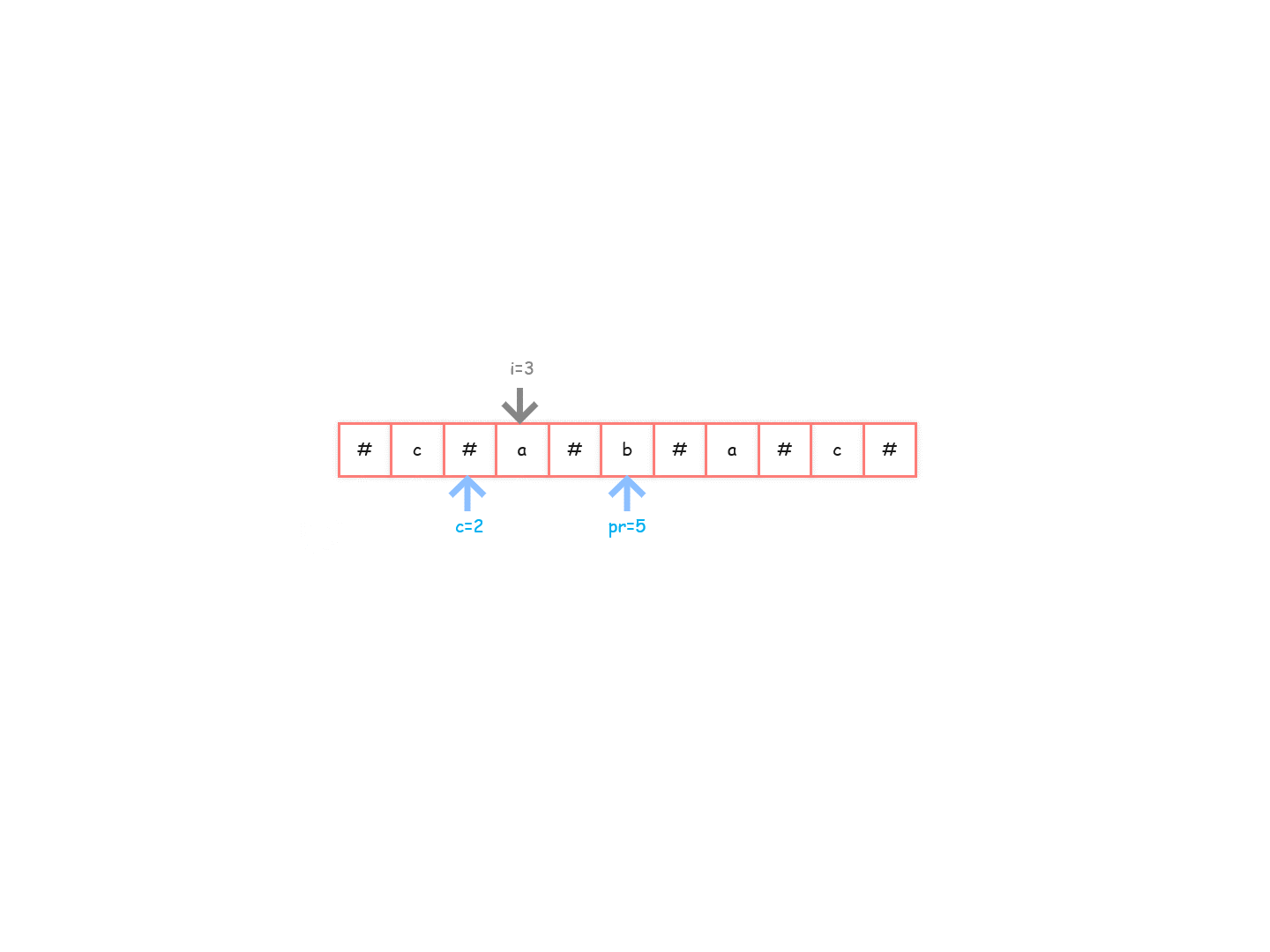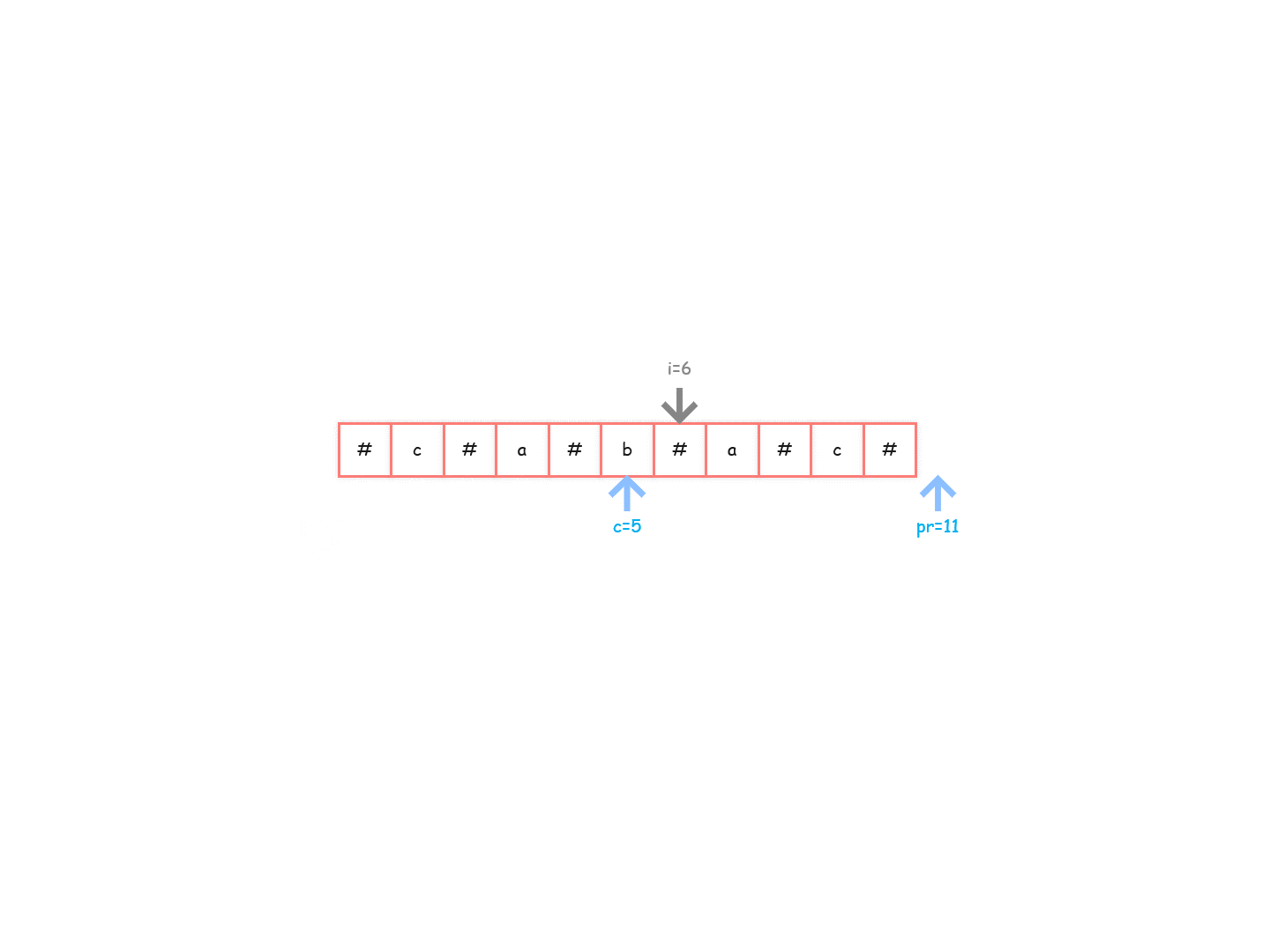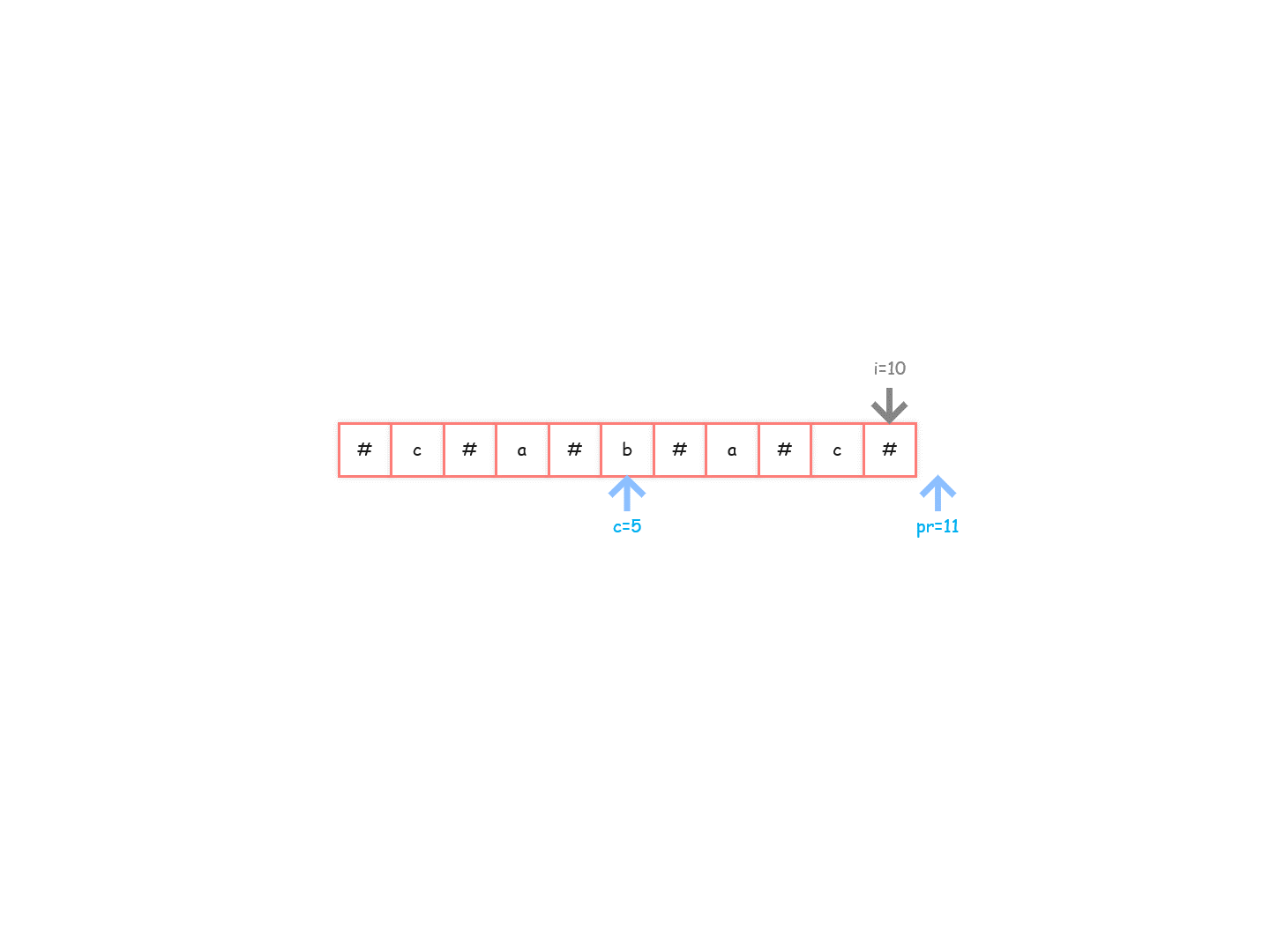
还是以 “#c#a#b#a#c#” 为例来说,还没遍历之前,pR 初始设置为-1。
-
charArr[0]==‘#’:回文半径为 1,所以目前回文半径向右只能扩到位置 0,回文半径最右即将到达的位置变为 1(pR=1),此时对应的中心位置更新,也即是 c == 0。
-
charArr[1]=='c’的回文半径为 2,此时所有的回文半径向右能扩到位置 2,所以回文半径最右即将到达的位置变为 3(pR=3),此时对应的中心位置更新,也即是 c == 1。
-
charArr[2]=='#'的回文半径为 1,所以位置 2 向右只能扩到位置 2,回文半径最右即将到达的位置不变,仍是 3(pR=3),c不变。
-
charArr[3]=='a’的回文半径为 2,所以位置 3 向右能扩到位置 4,回文半径最右即将到达的位置变为 5(pR=5),此时对应的中心位置更新,也即是 c == 3。
-
charArr[4]=='#'的回文半径为 1,所以位置 4 向右只能扩到位置 4,回文半径最右即将到达的位置不变,仍是 5(pR=5),c不变。
-
charArr[5]=='b’的回文半径为 6,所以位置 4 向右能扩到位置 10,回文半径最右即将到达的位置变为 11(pR=11),此时对应的中心位置更新,也即是 c == 5。此时已经到达整个字符数组的结尾,所以之后的过程中pR 和c也都将不再变化。
换句话说,pR 就是遍历过的所有字符中向右扩出来的最大右边界。只要右边界更往右,pR 就更新。
算法流程
主流程
只要能够从左到右依次算出数组 pArr 每个位置的值,最大的那个值实际上就是处理后的 charArr 中最大的回文半径,根据最大的回文半径,再对应回原字符串,整个问题就解决了。
假设现在计算到位置 index 的字符 charArr[i],在 i 之前位置的计算过程中,都会不断地更新pR 和 c 的值,即位置 index 之前的 c 这个回文中心扩出了一个目前最右的回文边界 pR。
再次强调一下,pR是c点所在回文区域最右侧+1的位置
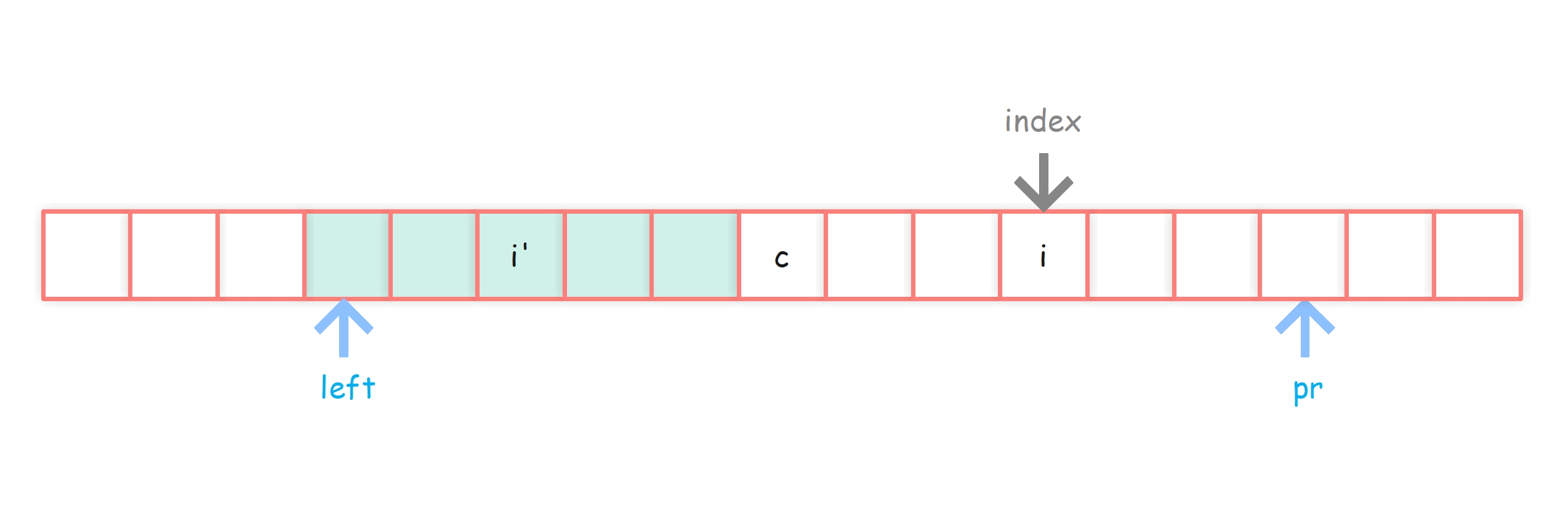
走到index会有以下几种情况:
情况1:index < pR,此时,之前的回文串已经罩不住index了
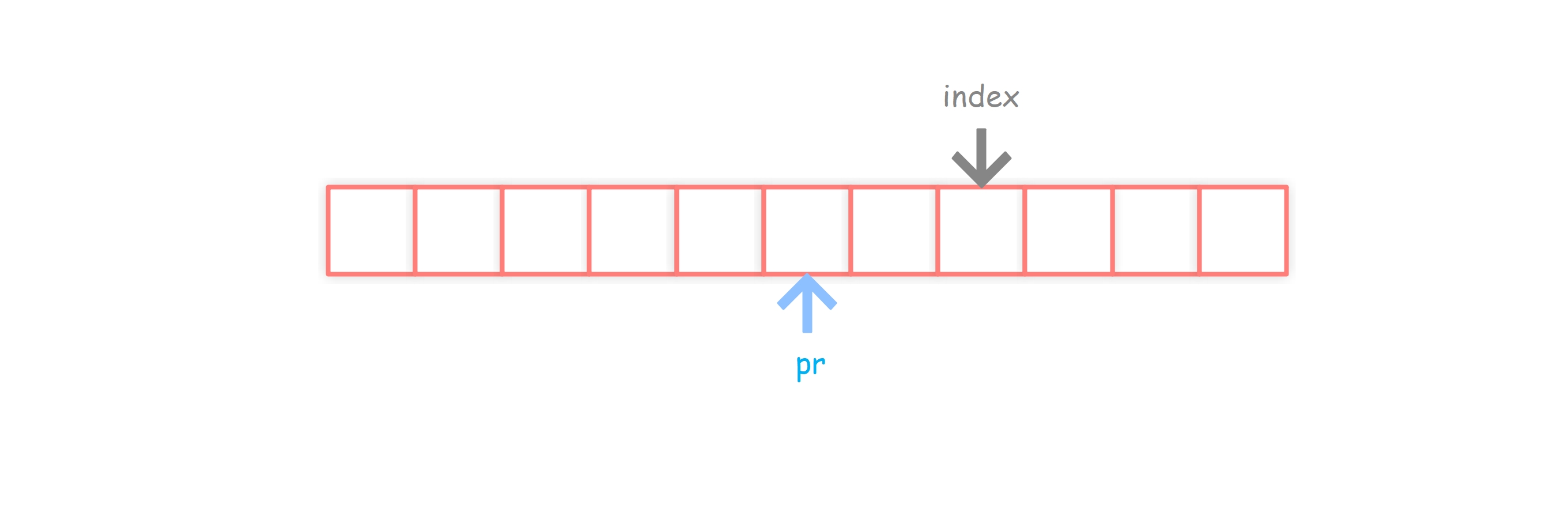
情况2:index >= pR,此时,之前的回文串还能罩住index
此时 i 关于 c 的对称点为 i’,此时又可以分为以下三种情况
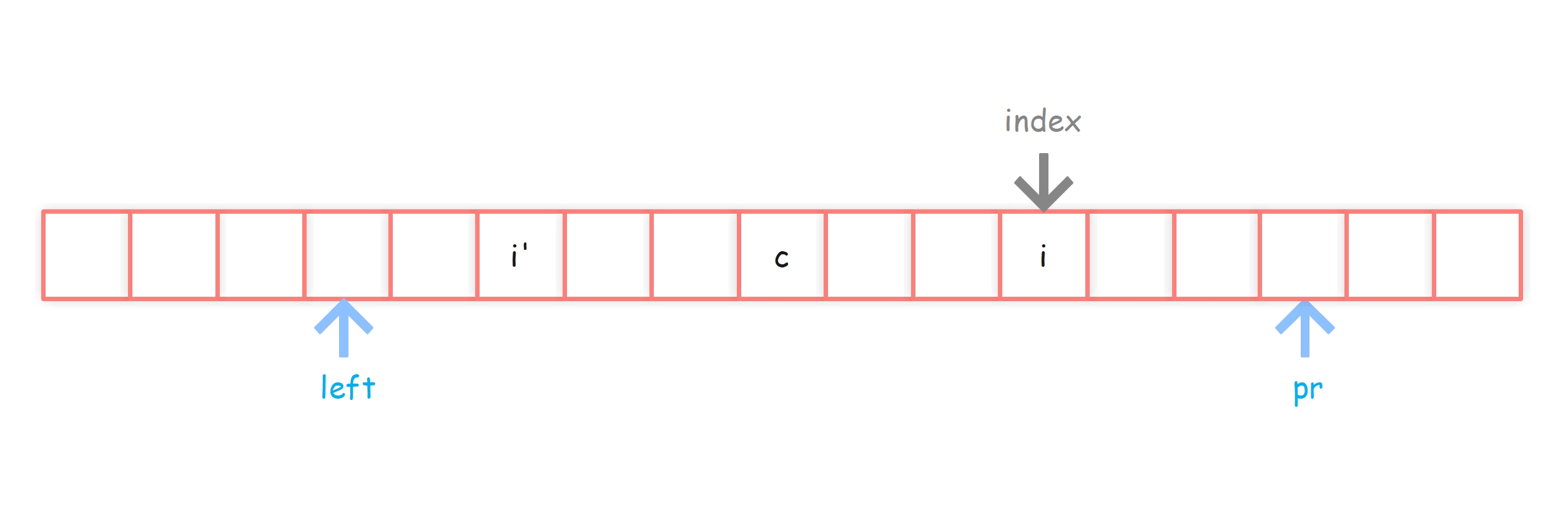
情况2-1:i’ 的回文半径覆盖区域(下图绿色区域)还仍在c覆盖区域内部
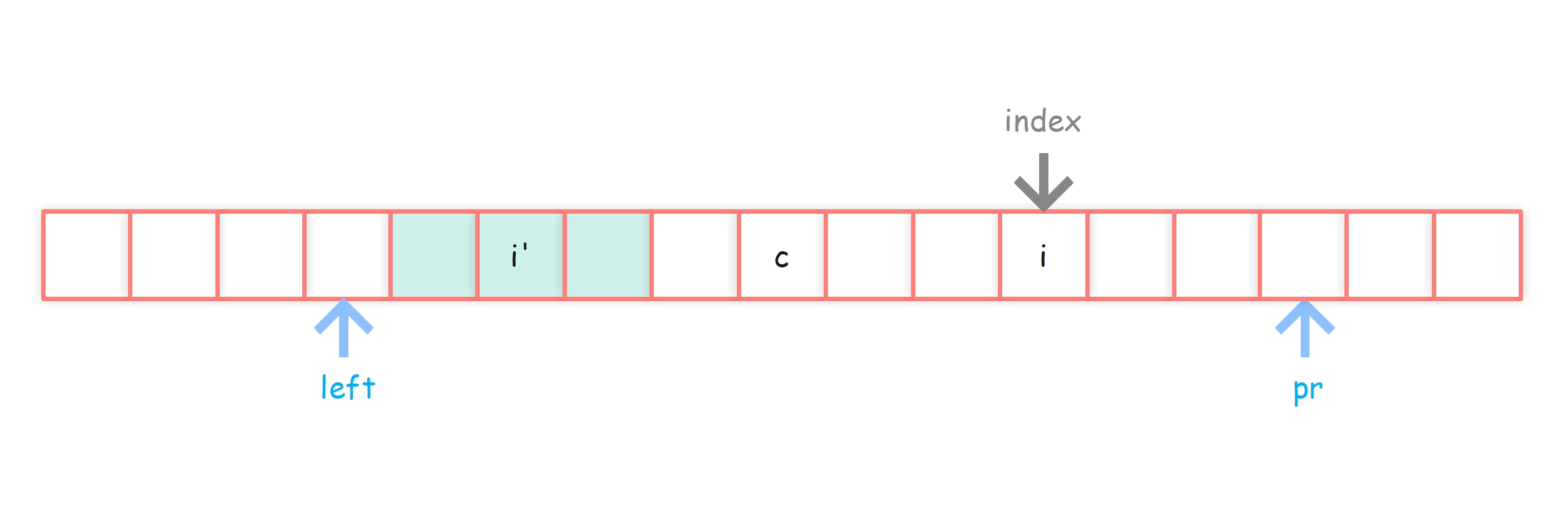
情况2-2:i’ 的回文半径覆盖区域(下图绿色区域)已经越过了 c 点覆盖的区域
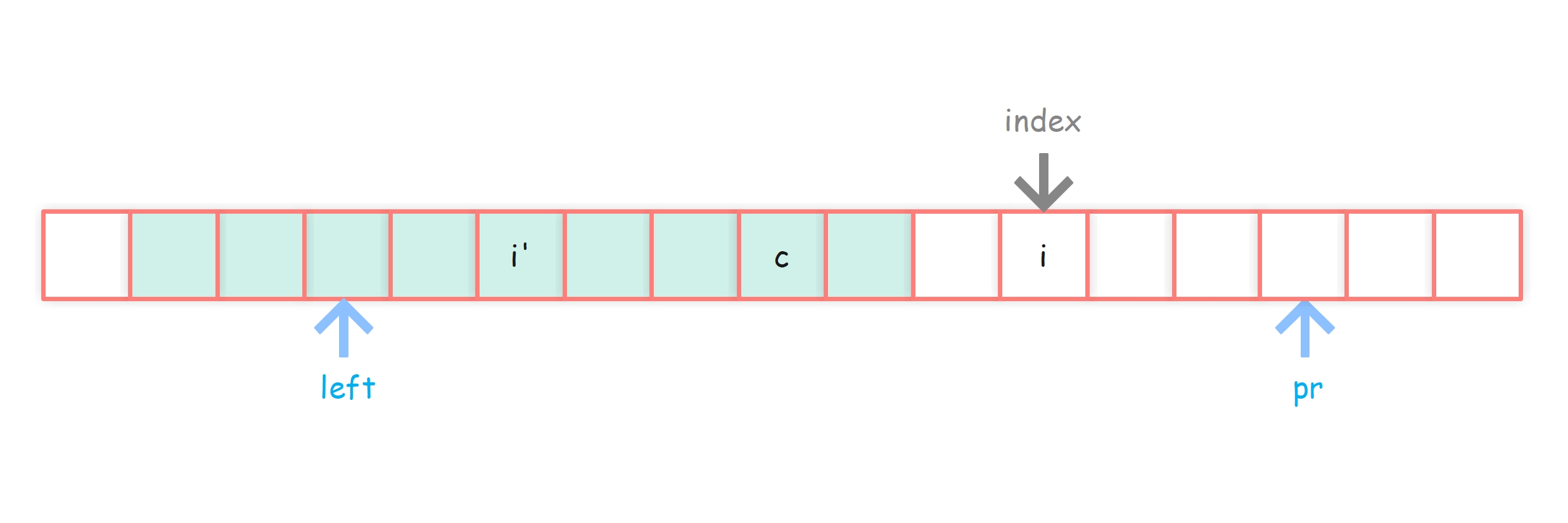
情况2-3:i’ 的回文半径覆盖区域(下图绿色区域)刚好到达c点覆盖区域的左侧
具体分析
情况1:之前的回文串已经罩不住index
此时,没有优化空间,我们从 index 位置开始,向左右两侧扩出去检查,此时的“扩”过程没有获得加速。
情况2-1:之前的回文串能罩住index,i’ 回文范围未到达c回文范围左侧
我们假设i’ 回文半径覆盖范围,记做A,A左边为a位置,右边为b位置
那么一定可以在 i 周围画一个和 i’ 回文半径覆盖相同半径的区域,记做X,假设X区域左边是x位置,右边是y位置。
那么由于原始字符串关于c在 left ~ pr-1 范围内都是对称的,则 A 区域与 X 区域构成的字符串必然是逆序的,又因为 A 区域关于 i’ 是对称的,那么 X 区域一定是关于 i 对称的。则pArr[i] 至少与 pArr[i’] 是相等的。
那么 pArr[i] 能不能 > pArr[i’] 呢?答案是不能的。
我们假设 pArr[i] > pArr[i’],则必然有 x 位置的值 == y位置的值
由于对称性,a位置的值 == y 位置的值,b位置的值 == x 位置的值
那么可以得到 a位置的值 == b 位置的值,阔到了i’ 回文覆盖的范围外面了,明显矛盾了。
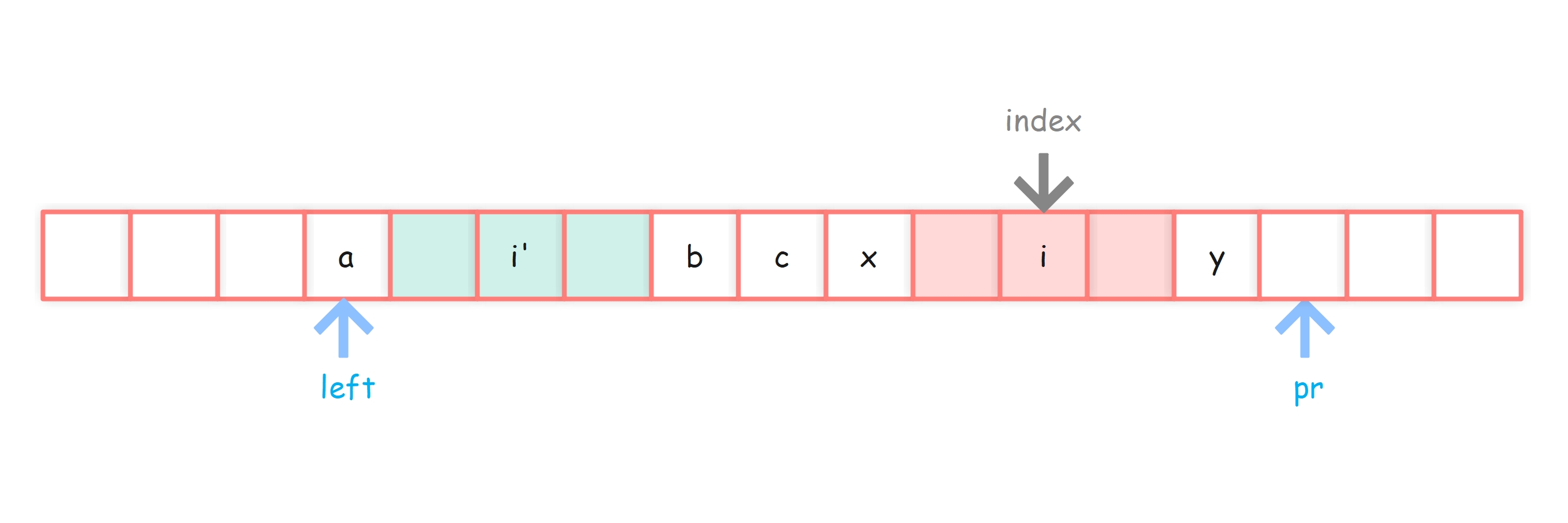
也就是说,这种情况下,pArr[i] = pArr[i’],且 pR以及c 都不变
情况2-2:之前的回文串能罩住index,i’ 回文范围越过了c回文范围左侧
我们假设c覆盖的回文的最左侧为 left 位置,left位置左边为a位置(a=left-1),a关于i’的对称位置为b。
再假设pr指向的位置为y位置,y关于i对称的位置为x。
现在要证明 pArr[i] == pr - index。
首先,由于i’的范围已经越过 left 了,在 left ~ pr-1范围内 i 与 i’ 又是对称的,那么i点的回文半径必定是可以取到 pr - index 的。
现在来证明 pArr[i] 不可能 > pr - index。
还是采用反证法,如果可i的回文半径可以 > pr - index,那么y位置的值 == x位置的值
由于 c 的回文范围为 left~pr-1(也就是y-1),那么a位置的值必然 != y位置的值
而由于对称性 a位置的值 == b位置的值 == x位置的值,于是得到:
x位置的值 != y位置的值,这与前面的假设是矛盾的,因此 pArr[i] = pr - index 成立。
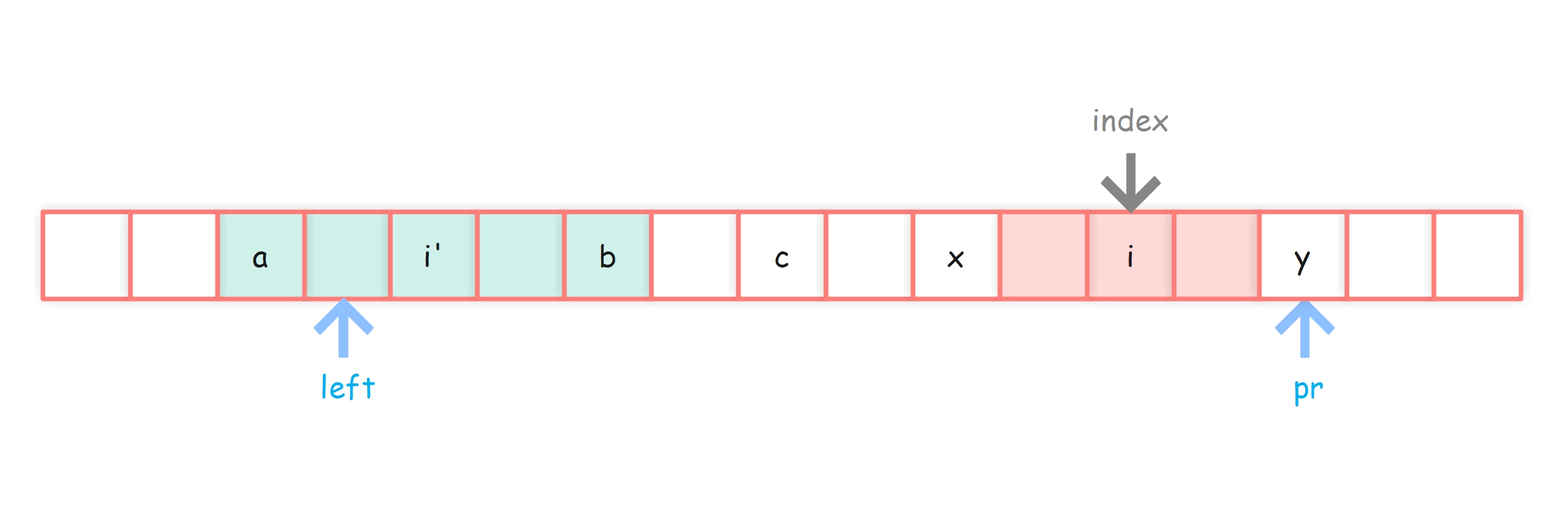
这种情况下,pR与c也不用进行更新。
情况2-3:之前的回文串能罩住index,i’ 回文范围正好到达c回文范围左边界
这种情况下,无法直接获得答案,需要对 i 的回文范围进行扩充
由于对称性,我们知道 pArr[i] >= pr - index,于是可以将半径从 pr - index + 1 开始逐一比较 i 的左右字符是否相等,直到取到最大的回文半径。
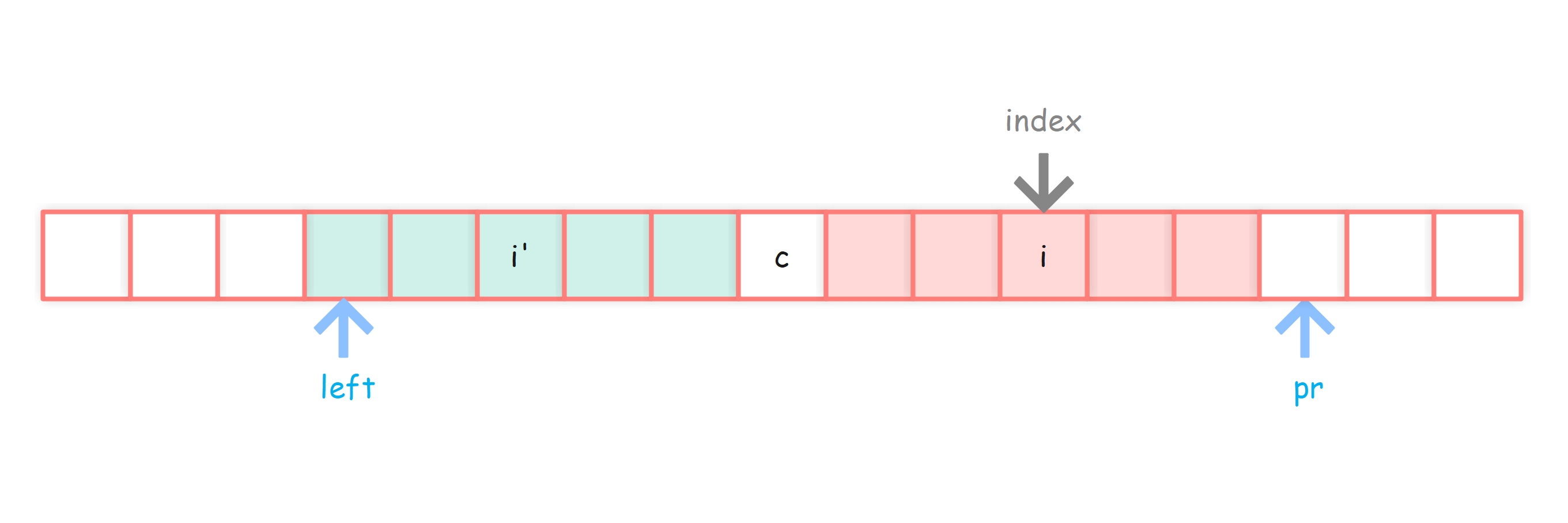
代码实现
逐行翻译上面的实现思路,代码如下
public static int manacher(String s) {if (s == null || s.isEmpty()) {return 0;}char[] str = manacherString(s);int n = str.length;// 之前遍历的所有字符的所有回文半径中,最右即将到达的位置的下一个位置// 一开始 pR 还没有扩充,指向-1int pR = -1;// 当前 pR 对应的中心回文子串的中心位置int c = -1;// 记录每个位置的回文半径int[] pArr = new int[n];// 记录回文半径的最大值int max = 0;// 临时变量int r;for (int index = 0; index < n; index++) {if (index < pR) { // 当前最右点可以包住 index// 3 4 5 6 7 8 9 10 11 12// i' c i pR// i' 正好到达 L 时,半径应当为 pR - iint rRange = pR - index;// i 关于 c 的对称点int iLeft = 2 * c - index;if (pArr[iLeft] < rRange) { // i'的半径 在 [L..R] 内部,不用扩pArr[index] = pArr[iLeft];// 半径 小于 c 半径,max不用更新} else if (pArr[iLeft] > rRange) { // i'的半径 在 [L..R] 外部,不用扩pArr[index] = rRange;// 半径 小于 i‘ 半径,max不用更新} else {// 接着扩,半径至少为 rangeR 了r = rRange;while (index - r > -1 && index + r < n && str[index - r] == str[index + r]) {r++;}pArr[index] = r;max = Math.max(max, r);}} else { // 当前最右点可以包不住 index// 3 4 5 6 7 8 9 10 11 12 13 14 15 16// pR i// 一次也匹配不上时的半径也应当为1r = 1;while (index - r > -1 && index + r < n && str[index - r] == str[index + r]) {r++;}pArr[index] = r;max = Math.max(max, r);}// 更新 pRif (index + pArr[index] > pR) {pR = index + pArr[index];c = index;}}return max - 1;}
当然,上面这段代码在结构上还能略做优化
我们可以将这四种情况都抽象为下面过程:
-
初始化一个 回文半径
-
迭代获取最大回文半径(如果有必要)
-
更新 pArr
-
更新 pR 以及 c(如果有必要)
public static int manacher(String s) {if (s == null || s.isEmpty()) {return 0;}char[] str = manacherString(s);int n = str.length;int pR = -1;int c = -1;int[] pArr = new int[n];int max = 0;int r = 0;for (int index = 0; index < n; index++) {// 情况1: r = 1// 情况2-1: r = pArr[2 * c - index]// 情况2-2: 情况2-3: r = pR - indexr = index < pR ? Math.min(pR - index, pArr[2 * c - index]) : 1;// 情况1、情况2-3才会走进这个循环,然后扩充r// 情况2-3以及情况2-2直接略过while (index + r < n && index - r > -1 && str[index - r] == str[index + r]) {r++;}// 填充 pArrpArr[index] = r;max = Math.max(max, r);// 如有必要(情况1、情况2-3),更新 pR 以及 cif (index + pArr[index] > pR) {pR = index + pArr[index];c = index;}}return max - 1;}
时间复杂度
分析迭代过程,对于情况 2-1 以及 情况 2-2,都只需要有限步都能获取答案,由于 index 取值从 0~n 单增,那么走到这两个分支的情况下,最多只需要 O(n) 的复杂度。
再来看 情况1 以及 情况2-2 两个分支,这两个步骤中迭代次数都是将 qR 从前一个更新到 当前步的次数,而 qR 的取值范围是 -1 ~ n,因此时间复杂度也为O(n)。
由于这几个分支只会走其中一个,因此整体的时间复杂度是 O(n)。
完整代码及对数器
public class Manacher {public static void main(String[] args) {// comp();System.out.println(longestPalindrome("cbbd"));}public static int manacher(String s) {if (s == null || s.isEmpty()) {return 0;}char[] str = manacherString(s);int n = str.length;// 之前遍历的所有字符的所有回文半径中,最右即将到达的位置的下一个位置// 一开始 pR 还没有扩充,指向-1int pR = -1;// 当前 pR 对应的中心回文子串的中心位置int c = -1;// 记录每个位置的回文半径int[] pArr = new int[n];// 记录回文半径的最大值int max = 0;// 临时变量int r = 0;for (int index = 0; index < n; index++) {r = index < pR ? Math.min(pR - index, pArr[2 * c - index]) : 1;while (index + r < n && index - r > -1 && str[index - r] == str[index + r]) {r++;}pArr[index] = r;max = Math.max(max, r);if (index + pArr[index] > pR) {pR = index + pArr[index];c = index;}}return max - 1;}public static int manacher2(String s) {if (s == null || s.isEmpty()) {return 0;}char[] str = manacherString(s);int n = str.length;// 之前遍历的所有字符的所有回文半径中,最右即将到达的位置的下一个位置// 一开始 pR 还没有扩充,指向-1int pR = -1;// 当前 pR 对应的中心回文子串的中心位置int c = -1;// 记录每个位置的回文半径int[] pArr = new int[n];// 记录回文半径的最大值int max = 0;// 临时变量int r;for (int index = 0; index < n; index++) {if (index < pR) { // 当前最右点可以包住 index// 3 4 5 6 7 8 9 10 11 12// i' c i pR// i' 正好到达 L 时,半径应当为 pR - iint rRange = pR - index;// i 关于 c 的对称点int iLeft = 2 * c - index;if (pArr[iLeft] < rRange) { // i'的半径 在 [L..R] 内部,不用扩pArr[index] = pArr[iLeft];// 半径 小于 c 半径,max不用更新} else if (pArr[iLeft] > rRange) { // i'的半径 在 [L..R] 外部,不用扩pArr[index] = rRange;// 半径 小于 i‘ 半径,max不用更新} else {// 接着扩,半径至少为 rangeR 了r = rRange;while (index - r > -1 && index + r < n && str[index - r] == str[index + r]) {r++;}pArr[index] = r;max = Math.max(max, r);}} else { // 当前最右点可以包不住 index// 3 4 5 6 7 8 9 10 11 12 13 14 15 16// pR i// 一次也匹配不上时的半径也应当为1r = 1;while (index - r > -1 && index + r < n && str[index - r] == str[index + r]) {r++;}pArr[index] = r;max = Math.max(max, r);}// 更新 pRif (index + pArr[index] > pR) {pR = index + pArr[index];c = index;}}return max - 1;}/*** 扩展字符串,abba => #a#b#b#a#* <p>主要是可以将偶数个数的回文串转换为奇数个中心对称的回文串,方便统一处理*/private static char[] manacherString(String s) {char[] chars = s.toCharArray();int n = (chars.length << 1) + 1;char[] ans = new char[n];int index = 0;for (int i = 0; i < n; i++) {ans[i] = (i & 1) == 0 ? '#' : chars[index++];}return ans;}/*** for test:暴力解,求解每一个位置的回文字符串的长度,时间复杂度O(n^2)*/public static int right(String s) {if (s == null || s.isEmpty()) {return 0;}char[] str = manacherString(s);int max = 0;for (int i = 0; i < str.length; i++) {int l = i - 1;int r = i + 1;while (l >= 0 && r < str.length && str[l] == str[r]) {l--;r++;}max = Math.max(max, r - l - 1);}return max / 2;}/*** for test*/public static String getRandomString(int possibilities, int size) {char[] ans = new char[(int) (Math.random() * size) + 1];for (int i = 0; i < ans.length; i++) {ans[i] = (char) ((int) (Math.random() * possibilities) + 'a');}return String.valueOf(ans);}private static void comp() {int possibilities = 25;int strSize = 20;int testTimes = 5000000;System.out.println("test begin");for (int i = 0; i < testTimes; i++) {String str = getRandomString(possibilities, strSize);int ans1 = manacher(str);int ans2 = manacher2(str);int ans3 = right(str);if (ans1 != ans2 || ans1 != ans3) {System.out.println(str);System.out.println(ans1);System.out.println(ans2);throw new RuntimeException("Oops!");}}System.out.println("test finish");}}
参考资料
https://www.bilibili.com/video/BV1YH4y1h7MU/
https://leetcode.cn/problems/longest-palindromic-substring/solutions/255195/zui-chang-hui-wen-zi-chuan-by-leetcode-solution/
这篇关于大白话 Manacher算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









