本文主要是介绍《读懂财务报表》手绘版读书笔记:通过报表找好公司,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过财报的三张表判断好公司: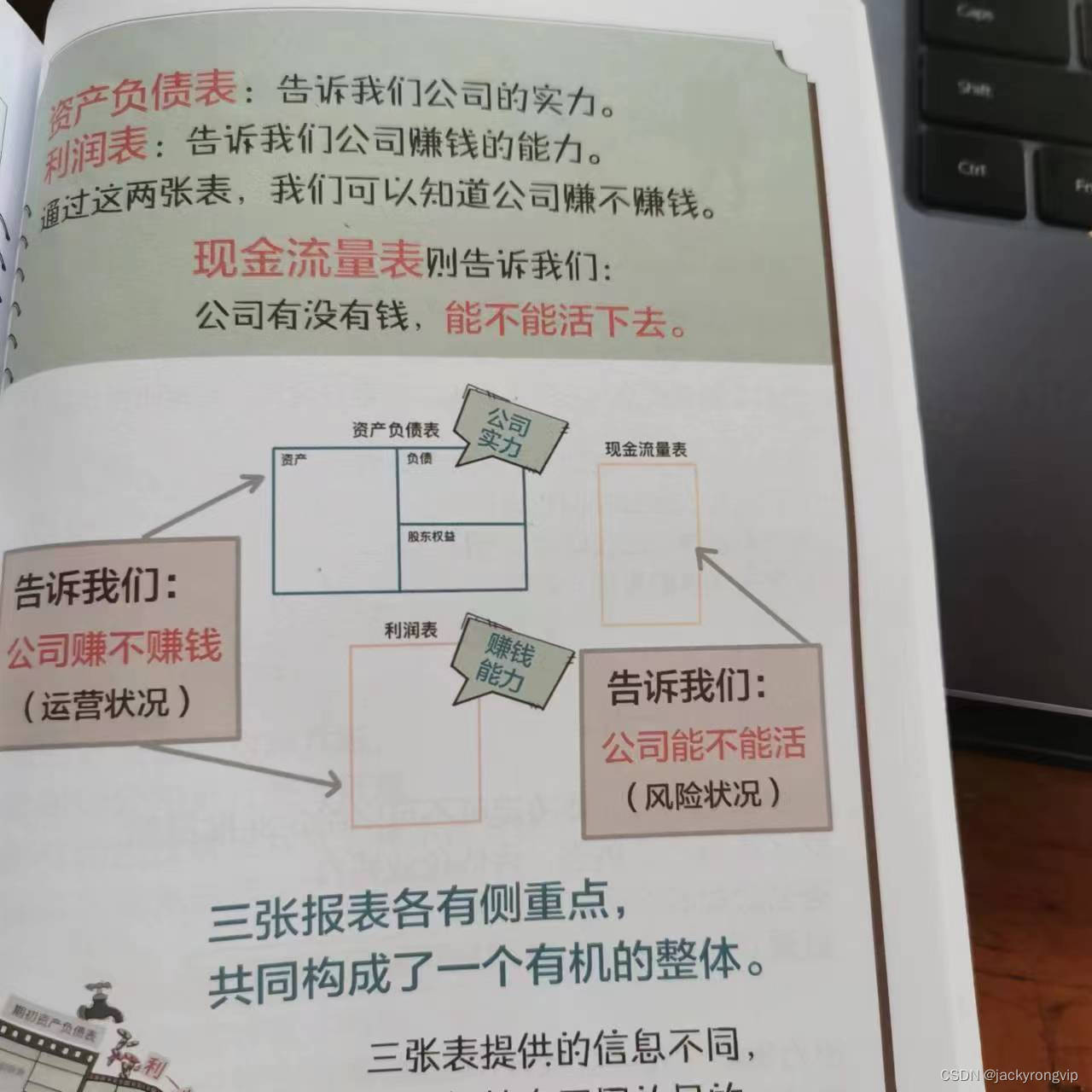
然后是在三表中,计算各个项目占总体的比例,以及做比率分析,

比率分析,从偿还能力,运营能力,盈利能力三方面分析:
1) 偿还能力


2)盈利能力:




3) 企业运营能力




这篇关于《读懂财务报表》手绘版读书笔记:通过报表找好公司的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
本文主要是介绍《读懂财务报表》手绘版读书笔记:通过报表找好公司,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过财报的三张表判断好公司:
然后是在三表中,计算各个项目占总体的比例,以及做比率分析,
比率分析,从偿还能力,运营能力,盈利能力三方面分析:
1) 偿还能力
2)盈利能力:
3) 企业运营能力
这篇关于《读懂财务报表》手绘版读书笔记:通过报表找好公司的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
http://www.chinasem.cn/article/952288。
23002807@qq.com









