本文主要是介绍Solr Getting Started,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原链接
安装Solr
A walkthrough of the Solr installation process.
Got Java
java版本需要再1.8以及其以上
java -version安装Solr
对于Linux/Unix/OSX系统, 需要下载.tgz文件.
对于Microsoft Windows 系统, 需要下载.zip 文件.
当开始的时候, 你需要做的就是提取Solr分布式压缩文件到你选择的目录, 当你准备启动在生产换进启动Solr时, 请注意TakingSolr to Production 页面提供的介绍.
为了保持简单, 提取Solr分布式压缩文件到你本地的主目录, 下面是Linux下的实例
tar zxf solr-x.y.z.tgz一旦提取,你现在可以运行Solr.
参考RunningSolr
运行Solr
An introduction to running Solr. Includes information on starting up the servers, adding documents, and running queries.
本节讲介绍 如何用一个例子模式(example schema)运行Solr, 如何添加文档, 如何进行查询
启动Server
在Solr的目录下,运行
bin/solr start如果你运行在Windows, 你需要运行bin\solr.cmd启动Solr
bin\solr.cmd start它将会在后台启动Solr, 监听着8983端口.
当你后台启动Solr, 这脚本将会等待, 确保在回到命令行提示之前, Solr正常启动.
这个bin/solr and bin\solr.cmd脚本 允许你自定义启动Solr. 让我们通过几个bin/solr简单的例子认识(如果你用的是windows, 使用bin\solr.cmd 一样起作用)
Solr Script Options
脚本帮助
bin/solr -help//指定的命令介绍
bin/solr start -help前台启动Solr
start Solr in the Foreground
因为Solr是一个服务器,他更多的运行的在后台, 尤其是在Unix/Linux.
然而, 前台启动Solr,可以简单的这么做
bin/solr start -f如果你运行在Windows, 你可以这么运行:
bin\solr.cmd start -f使用不同的接口启动Solr
为了改变Solr的监听接口, 你可以用-p 参数启动. 例如:
bin/solr start -p 8984停止Solr
当前台启动Solr时, 可以用Ctrl-c停止.
当后台启动时, 可以用stop命令, 例如:
bin/solr stop -p 8983这个停止命令需要你指定Solr监听的端口, 或是你可以用 -all 参数去停止所有运行中的Solr实例.
用具体的实例配置启动Solr
Solr也提供了一系列有用的列子,去帮助我们学习关键的特性. 你可以用-e标签启动例子examples, 例如启动’techproducts’ example, 你需要这么做:
bin/solr -e techproducts当前, 你可以运行的可用的例子有: techproducts, dish, schemaless, cloud.
观看 Running with Example Configurations章节, 可以看到没一个例子的详情
检查Solr是否在运行
如果你不确定Solr是否在本地运行,你可以用状态命令:
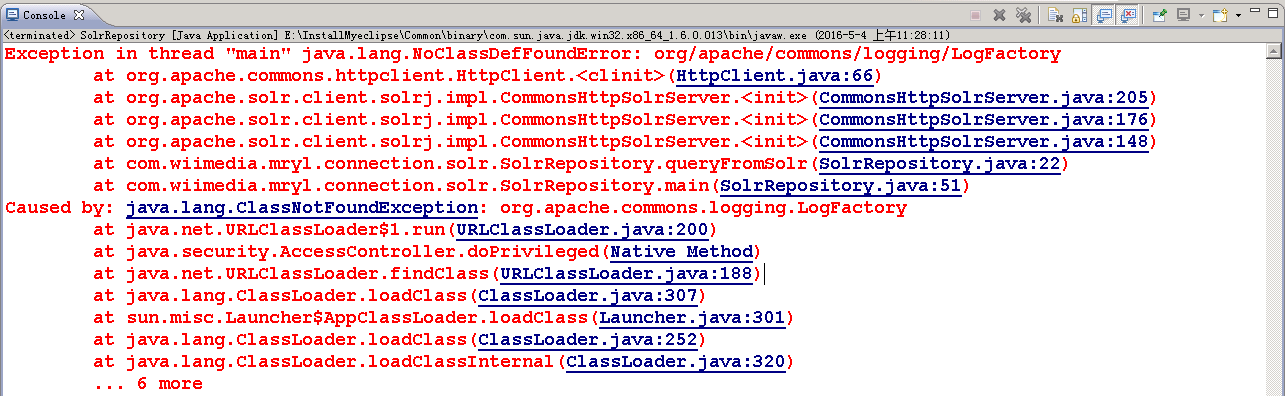
bin/solr status他将会搜索你电脑中运行中的Solr实例, 然后收集(gather)他们的基本信息, 例如这个版本和内存使用情况. 就是这样. Solr正在运行. 如果你需要具有说服的, 你可以用Web浏览器去看管理控制台(Admin Console)
http://localhost:8983/solr/将会出现Solr管理界面
如果Solr没有运行, 你的浏览器将会提示, 不能链接到服务器. 检测你的端口号,再尝试一次.
创建核心
如果你没用例子去启动Solr, 你需要创建一个核心确保能够索引和搜索. 你可以这么做去运行:
bin/solr creat -c <name>这个将会创建一个核心, 它用的是data-driven模式.
当你添加文档到索引中时, 这个模式将会尝试去猜测争取的字段类型(field type).
查看所有可用的选项去创建一个新的核心, 请执行:
bin/solr creat -help添加文档
构建Solr 是用来查找文档,匹配查询. Solr的模式提供了一个idea(内容如何被结构化的)和很多的schema, 没有文档,就找不到任何东西. Solr在做更多的事情前,需要输入.
在尝试见多你自己的内容之前, 你也许想添加一个简单的文档. Solr的安装已经自带了不同类型的实例文档, 他们位于安装目下的example/directory的子目录下.
在bin/目录下, 是post脚本. post脚本是一个命令行工具, 用来索引不同类型的文档. 不需要担心太多详情. 这个Indexing and Basic Data Operations 章节已经详细介绍了索引indexing.
为了了解更多的关于bin/post范围的信息, 请用-help 选项. Windows用户, 请看 Post Tool on Windows 章节.
bin/post 能够post 不同类型的内容给Solr, 包括Solr的本地XML, JSON, CSV 文件, 一个富文档目录树, 伸直一个简短的web爬的数据. 在运行’bin/post -help’ 命令后了解实例, 了解各种不同的命令, 这样就可以简单post你的内容到Solr.
来吧, 添加一些实例下的所有XML 文件:
bin/post -c gettingstarted example/exampledocs/*.xml就是这样, Solr已经索引了这些文件下的文档.
提问题
现在你已经索引了文档, 你就可以进行查询了. 这最简单的办法是去构建一个URL, 他包含查询参数. 这个实在类似于HTPP URL.
例如: 下面的查询会搜索所有文档的’video’字段:
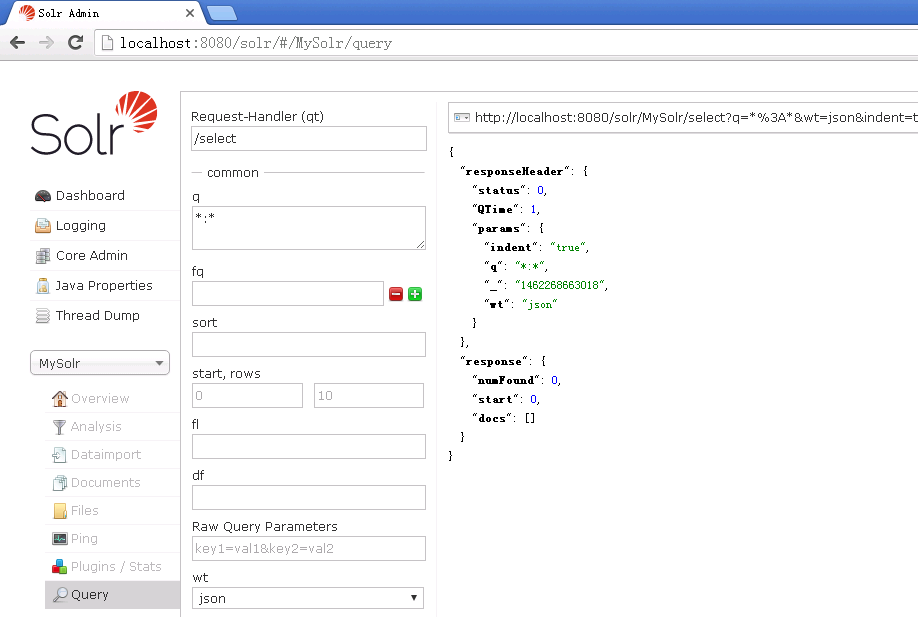
http://localhost:8983/solr/gettingstarted/select?q=video注意URL 是如何包含这个host name (localhost), the port number (Solr监听的接口) (8983), the application name (solr), 查询处理程序(request handler) (select), 最后, 是query 本身(q=video).
这个结果包含在XML 文档中, 你能够点击上面的链接,直接检索. 这个文档包含2个部分. 第一部分是<lst name="responseHeader">, 它包含响应自己的信息. 这个回复主要的部分是这个<result name="result " numFound="3" start="0">标签, 它包含一个或多个doc标签, 每一个都包含文档中的匹配查询出来的字段. 你可以用标准的XML 转换技术, 去塑造Solr结果为一种形式, 能够非常合适的展示给用户. 可选的, Solr能够用JSON, PHP, Ruby甚至用户自定义的格式输出结果.
docs标签代表 搜索结果
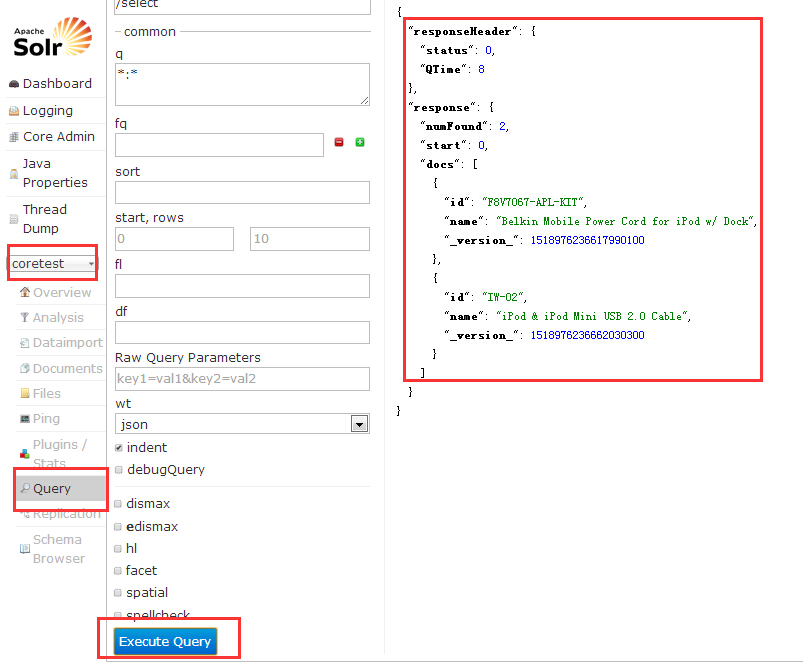
一旦你掌握了基本的查询思想, 就可以很容易的用来探索查询语法. 这个和之前的一样,但是结果仅仅包含了每一个返回文档的ID, name, price. 如果你不指定你想要的字段, 所有的字段都将会返回.
http://localhost:8983/solr/gettingstarted/select?q=video&fl=id,name,price下面是另一个实例, 他会搜索name 字段为’black’的. 如果你没有告诉Solr去搜索哪个字段, 他将会搜索schema中默认的字段.
http://localhost:8983/solr/gettingstarted/select?q=name:black你可以提供一个字段范围, 下面的查询会查找每一个文档中价格在$0-$400的字段
http://localhost:8983/solr/gettingstarted/select?q=price:[0%20TO%20400]&fl=id,name,priceFaceted browsing 是Solr查询结果的第三部分. 为了体验他的力量, 可以看一下接下来的查询. 它添加了facet=true and facet.field=cat.
http://localhost:8983/solr/gettingstarted/select?q=price:[0%20TO%20400]&fl=id,name,price&facet=true&facet.field=cat<lst name="facet_counts ">元素也出现在结果中
<lst name="facet_counts"><lst name="facet_queries"/><lst name="facet_fields"><lst name="cat"><int name="electronics">6</int><int name="memory">3</int><int name="search">2</int><int name="software">2</int><int name="camera">1</int><int name="copier">1</int><int name="multifunction printer">1</int><int name="music">1</int><int name="printer">1</int><int name="scanner">1</int><int name="connector">0</int><int name="currency">0</int><int name="graphics card">0</int><int name="hard drive">0</int><int name="monitor">0</int></lst></lst><lst name="facet_dates"/><lst name="facet_ranges"/>这个facet信息能够展示出查询结果: 每一个中cat字段有可能值有多少. 你能够轻松利用这些信息为用户提供一个快速的方法, 来缩小他们的查询结果. 你可以通过添加一个或更多个filter 查询参数到Solr的请求中来过滤结果. 下面请求添加了一个’software’ 类, 更进一步的限制了到文档的请求
http://localhost:8983/solr/gettingstarted/select?q=price:0%20TO%20400&fl=id,name,price&facet=true&facet.field=cat&fq=cat:software简要概述(Quick Overview)
A high-level overview of how Solr works.
下面是一个例子, solr被集成到一个应用中:
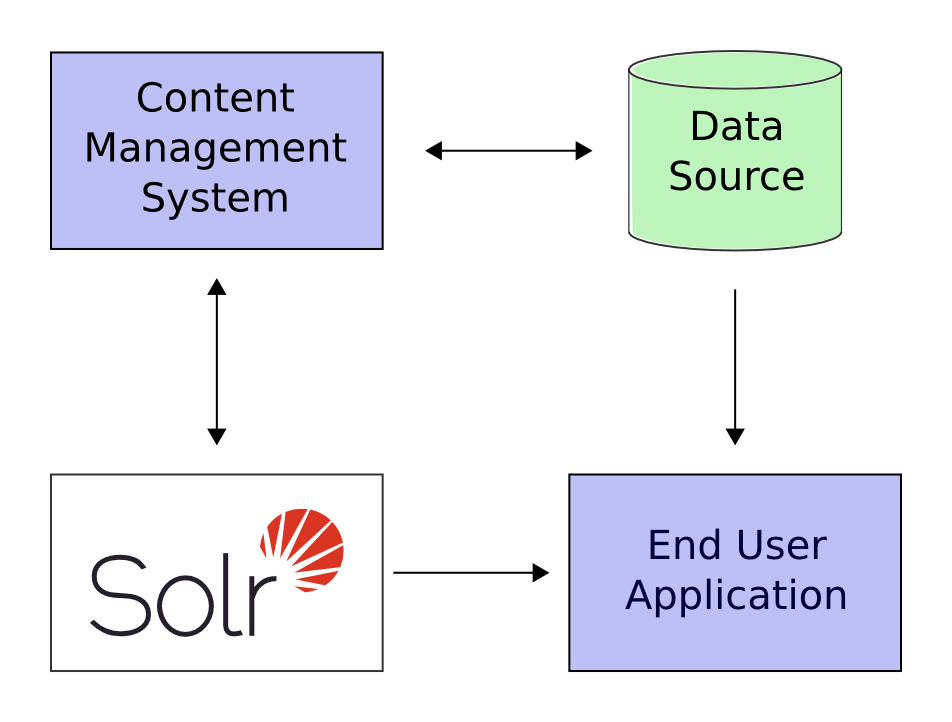
在上述情况下, Solr沿着其他服务程序运行. 例如一个在线的程序,为终端用户提供一个用户界面, 一个购物车,一个购买的方法; 然而一个库存管理程序允许店铺管理员编辑商品信息. 这个商品元数据将会保存在一些database或Solr中.
通过下面几步, Solr让在线商店具有更方便的搜索的能力:
1. 定义一个schema. 这个schema要告诉Solr, 哪些文档需要被索引. 在这个在线购物的例子中,这个schema将会定义字段,包括商品名称,描述, 价格,生产厂家等等. Solr的schema是很有力的,灵活的, 他允许你为你的应用程序, 制定(tailor)Solr的行为. 看 Documents, Fields, and Schema Design了解更多.
2. 部署Solr到你的应用程序服务端.
3. 更具用户的搜索要求, 制定Solr的文档
4. 在你的应用程序中暴露(Expose)搜索功能(functionality)
因为Solr基于开源标准, 所以他更具有高度扩展性. Solr查询是RESTful的, 这就意味着在本质上(in essence) 这个查询是一个简单的HTTP 请求URL 并且这个响应是一个结构化的文档: 主要是XML, 但是他可以是JSON, CSV 或是其他格式.这就意味各种各样的客户端都可以使用Solr, 从其他的web应用程序到浏览器客户端, 富客户端应用程序, 和移动设备. 任何兼容HTTP的平台都能和Solr对话. 更多ClientAPIs的信息,请看ClientAPIs
Solr是基于Apache Lucene project. Lucene是一个高性能, 全功能搜索引擎. Solr 提供了从最简单关键词的查询到复杂的多字段查询, 和faceted 搜索结果.
更多searching 和 queries的信息请看Searching
如果Solr的兼容性还不够深刻, 他解决大批量应用的能力应该有一些伎俩(trick).
一个相对常见的场景是: 你有很多数据, 很多查询, 以至于单个Solr服务器不能够处理你全部的工作量(workload). 在这种情况下, 你需要用SolrCloud扩展(scale up)你应用程序的容量(capabilities), 更好的分布数据, 请求的处理, 跨很多服务器. 根据你需要的拓展, 多个选项能够混合起来 去匹配.
例如: ‘分片’(sharding)是一个可缩放的技术, 一个集合被分割成多个被称作shards的逻辑片段, 目的是为了 扩展集合中文档的数量, 这个集合会超出单个服务器的物理容量. 接下来的问题是分配集合中的每一个切片, 这些分片用合并的结果进行响应. 另一个可用的技术是增加你集合的’ReplicationFactor’, 这个技术能让你添加带有额外集合拷贝的服务器, 通过传播请求到多台机器, 从而处理更多高并发(concurrent)查询. 分片和复制并不是相互互斥(mutually exclusive)的, 一起应用能让Solr成为一个极其强大的可拓展平台.
更重要的是(Best of all), 这些关于大批量应用的讨论并不仅仅是假设: 一些著名的互联网站点正在用Solr, 如Macy’s, EBay, Zappo’s.
更多信息请看PublicServers
更进一步的介绍
An introduction to Solr’s home directory and configuration options.
Solor目录结构和配置选项
这一章节将会介绍Solr的主目录和其他配置选项.
当Solr运行在应用服务器上时, 他需要访问一个主目录. 这个目录包含了重要的配置信息, 并且这是Solr存放索引的地方. 当你通过standalone(独立)模式或SolrCloud模式运行Solr时, 这个主目录的布局会不一样.
Standalong Mode
<solr-home-directory>/solr.xmlcore_name1/core.propertiesconf/solrconfig.xmlmanaged-schemadata/core_name2/core.propertiesconf/solrconfig.xmlmanaged-schemadata/SolrCloud Mode
<solr-home-directory>/solr.xmlcore_name1/core.propertiesdata/core_name2/core.propertiesdata/文件作用
solr.xml
规定了你Solr服务实例的配置选项, 更多solr.xml的信息,请看 Solr Cores and solr.xml.
每个Solr的核心
core.properties
为每一个核心定义了特定的属性, 例如name, 这个集合这个核心属于谁, schema的位置 和其他参数. 更多core.properties详情,请参考 Defining core.properties.
solrconfig.xml
它控制了高级别的行为. 你能够为数据(data)目录指定一个可替换的位置. 更多solrconfig.xml信息, 请参考Configuring solrconfig.xml.
managed-schema.xml(或schema.xml)
描述了你让Solr去索引的那些文档. 这个模式定义个了一个作为集合字段的文档. 你开始定义字段类型和字段本身. 字段类型的定义是功能强大的, 它包含了Solr如何处理输入的字段值和查询的值得信息. 更多关于Solr Schemasde 信息,请看Documents, Fields, and Schema Design和 Schema API
data/
这个目录包含了低级别的索引文件.
注意
为每一个Solr核心, SolrCloud的实例不包含conf目录, 所有它就没有solrconfig.xml或Schema文件. 这是因为经常在conf目录下看到的配置文件被存储到在ZooKeeper下, 所以他们能够在集群中传播(so they can be propagated across the cluster).
如果你正在用嵌入的ZooKeeper实例的SolrCloud, 你可以看zoo.cfg and zoo.data文件. 他们是ZooKeeper的配置和数据文件. 然而,如果你运行你自己的ZooKeeper合奏, 当你启动它的时候, 你要提供你自己的ZooKeeper配置文件, 并且Solr里面的拷贝也会无用. 更多关于ZooKeeper和SolrCloud的信息, 请参考SolrCloud
Solr启动脚本参考
a complete reference of all of the commands and options available with the bin/solr script.
这篇关于Solr Getting Started的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!