本文主要是介绍大模型的代码编辑力:CodeEditor揭示GeminiUltra和GPT4的超凡实力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

引言:探索代码编辑中的大型语言模型
在当今快速发展的软件工程领域,代码编辑已成为开发者日常工作中不可或缺的一部分。随着人工智能技术的进步,大型语言模型(LLMs)在代码生成和辅助编程方面展现出了巨大潜力。然而,现有的评估方法主要集中在代码生成上,对于评估LLMs在代码编辑任务中的表现却鲜有研究。代码编辑不仅包括代码生成,还涉及调试、翻译、优化和需求转换等多种复杂任务,这些都是软件开发过程中至关重要的环节。
为了弥补这一评估空白,研究者们提出了CodeEditorBench,这是一个全新的评估框架,旨在严格评估LLMs在代码编辑任务中的性能。本文将深入探讨CodeEditorBench的设计理念、构建方法和评估指标,以及它如何为LLMs在代码编辑方面的进步提供了一个坚实的评估平台。通过对多个模型的评估,我们将揭示开源与闭源模型在不同编辑任务中的表现差异,并探讨模型性能与问题类型和提示敏感性之间的关系。
CodeEditorBench的介绍与目标
1. CodeEditorBench的设计与构建
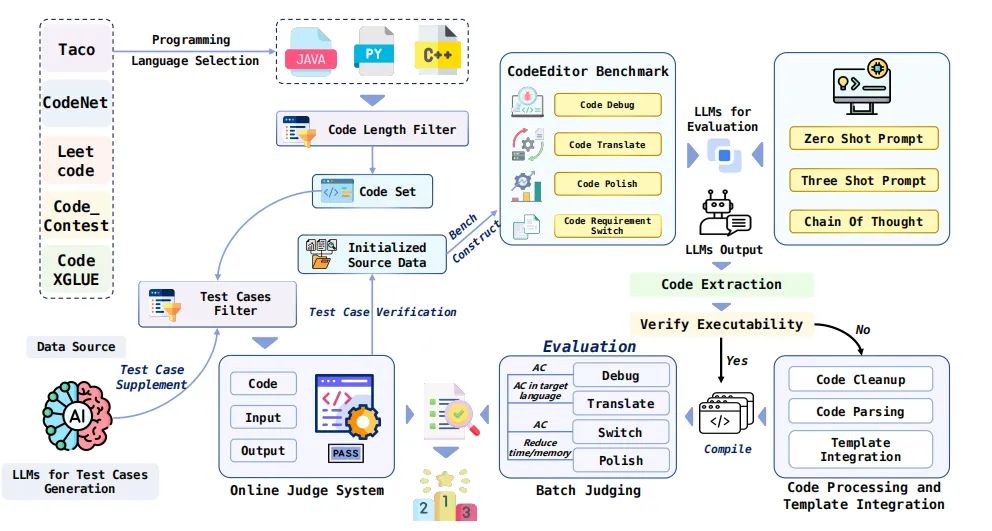
CodeEditorBench是一个创新的评估框架,专为评估LLMs在代码编辑任务中的性能而设计。与传统的仅关注代码生成的基准测试不同,CodeEditorBench强调真实世界场景和软件开发的实际方面。它从五个不同的来源策划了多样化的编码挑战和场景,涵盖了各种编程语言、复杂性水平和编辑任务。
2. 评估任务的分类
基于软件开发生命周期(SDLC)的定义,CodeEditorBench将代码编辑问题分为四个场景:代码调试(Code Debug)、代码翻译(Code Translate)、代码优化(Code Polish)和代码需求转换(Code Requirement Switch)。这些分类反映了代码编辑过程中最常见和最关键的任务类型。
3. 测试用例的手工构建
为了精确检查编辑的正确性,研究者们手工构建了各种编程场景中的测试用例。此外,他们还建立了一个在线评估系统,以便轻松评估广泛的代码LLMs。最终,他们编制了一个包含7,961个代码编辑任务的数据集,每个任务平均有44个测试用例。
4. 评估方法
为了补充这一全面的基准测试,研究者们旨在通过一个代码编辑排行榜来描绘当前可用模型的概况。他们评估了6个基础模型和13个经过指令调整的模型,使用相同的实验框架,并采用零次射击和三次射击的评估方法。
5. 目标与贡献
CodeEditorBench的目标是通过提供一个健壮的平台来评估代码编辑能力,从而催化LLMs的进步。研究者们将发布所有提示和数据集,以便社区扩展数据集并对新兴的LLMs进行基准测试。通过引入CodeEditorBench,他们为代码编辑中的LLMs的进步做出了贡献,并为研究人员和从业者提供了宝贵的资源。
论文标题、机构、论文链接和项目地址(如有)
论文标题:CODEEDITORBENCH: EVALUATING CODE EDITING CAPABILITY OF LARGE LANGUAGE MODELS
机构:
1. Multimodal Art Projection Research Community
2. University of Waterloo
3. HKUST
4. University of Manchester
5. Tongji University
6. Vector Institute
论文链接:https://arxiv.org/pdf/2404.03543.pdf
项目地址:https://codeeditorbench.github.io
代码编辑的重要性与现有评估方法的局限
1. 代码编辑的重要性
代码编辑是软件开发过程中的关键能力,涵盖了调试、翻译、优化和需求转换等多种子任务。这些任务不仅是编码工作的重要组成部分,而且对于提高开发效率、代码质量以及促进团队协作都至关重要。与代码补全不同,代码编辑需要对现有代码进行深入理解和精确修改,因此对代码编辑能力的评估尤为重要。
2. 现有评估方法的局限
尽管大型语言模型(LLMs)在编程辅助方面的应用日益增多,现有的评估方法主要集中在代码生成上,忽视了代码编辑在软件开发中的重要性。例如,HumanEval和MBPP等数据集常用于代码补全研究,但并不适合评估代码编辑能力。此外,现有的评估框架往往缺乏针对实际软件开发场景和实用性方面的考量。
为了弥补这一评估方法上的重大缺陷,CodeEditorBench应运而生。它是一个旨在严格评估LLMs在代码编辑任务中性能的评估框架。与仅关注代码生成的现有基准不同,CodeEditorBench强调真实世界场景和软件开发的实际方面,通过从五个来源策划多样化的编码挑战和场景,覆盖了各种编程语言、复杂性级别和编辑任务。
通过对19个LLMs的评估,CodeEditorBench揭示了闭源模型(特别是Gemini-Ultra和GPT-4)在代码编辑任务中的性能优于开源模型,突显了基于问题类型和提示敏感性的模型性能差异。CodeEditorBench的目标是通过提供一个健壮的平台来评估代码编辑能力,从而推动LLMs的进步。所有的提示和数据集将被公开,以便社区扩展数据集并对新兴的LLMs进行基准测试。通过引入CodeEditorBench,我们为LLMs在代码编辑方面的进步做出了贡献,并为研究人员和实践者提供了宝贵的资源。
CodeEditorBench的构建:评估框架与数据集
1. 评估框架的设计理念
CodeEditorBench是一个旨在严格评估大型语言模型(LLMs)在代码编辑任务中表现的评估框架。与仅关注代码生成的现有基准不同,CodeEditorBench强调真实世界场景和软件开发的实际方面。它通过从五个来源策划多样化的编码挑战和场景,涵盖各种编程语言、复杂性水平和编辑任务,来模拟现实世界中的软件开发场景。评估框架的设计理念是基于软件开发生命周期(SDLC)的定义,评估LLMs在四种场景中的表现:代码调试(Code Debug)、代码翻译(Code Translate)、代码润色(Code Polish)和代码需求转换(Code Requirement Switch),这些类别反映了代码编辑过程中最常见和关键的任务类型。
2. 数据集的来源与构建方法
CodeEditorBench的数据集是从五个来源精心挑选的:leetcode、code_contests、CodeXGLUE、codeNet和Taco。为了符合先进LLMs的最大令牌限制,采用了严格的选择标准,排除了超过800行或超过1000令牌的问题代码。数据集涵盖了广泛的数据结构和算法,旨在促进对编码原则的全面探索和理解,满足各种计算问题和场景的需求。

评估方法:测试用例与在线评估系统
为了精确检查编辑正确性,我们手动构建了各种编程场景中每个问题的测试用例,并建立了一个在线评估系统,以便轻松评估广泛的代码LLMs。我们编译了一个包含7,961个代码编辑任务的数据集,每个任务平均有44个测试用例(最少8个,最多446个)。为了考虑数据污染现象,我们实施了基于时间戳的过滤过程,从而得到了一个经过精炼的数据集CodeEditorBench_Plus,原始数据集被称为CodeEditorBench_Primary。
我们还为C++、Python和Java开发了可执行的模板,以便与LeetCode的提交要求保持一致。为了解析代码和提取函数名,所有代码使用tree-sitter——一个用于编程工具的增量解析系统,以确保正确获取高级函数名。我们的OJ建立在一个配备高性能Intel(R) Xeon(R) Platinum 8480C处理器的服务器上,支持高达4PB的物理内存,并具有高达128TB的虚拟内存空间。
模型性能分析
1. 开源与闭源模型的比较
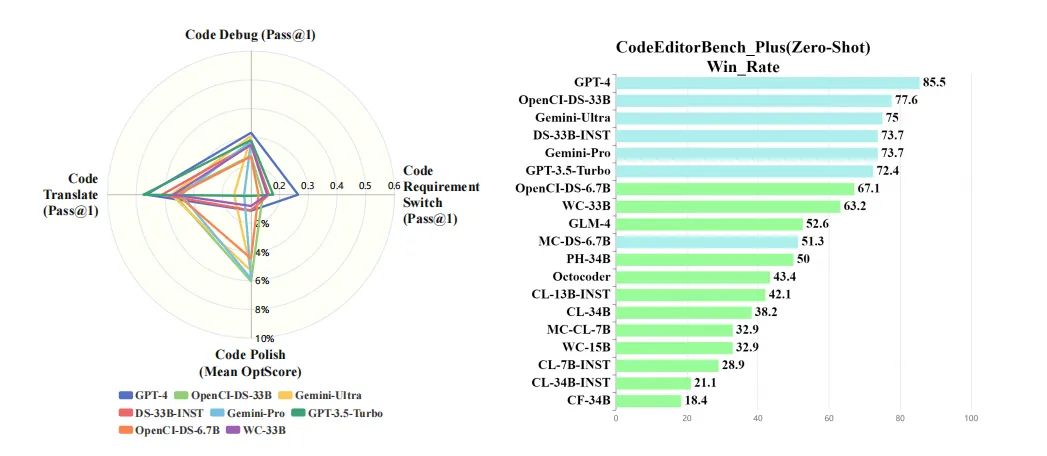
在评估了19种大型语言模型(LLMs)在代码编辑任务中的表现后,我们发现闭源模型(尤其是Gemini-Ultra和GPT-4)在CodeEditorBench中的表现普遍优于开源模型。这一发现表明,模型的性能不仅取决于其架构和训练数据的规模,还受到其可访问性的影响。闭源模型通常拥有更多的资源和更先进的技术,这可能是它们在此类任务中表现更好的原因之一。
在开源模型中,OpenCI-DS-33B表现最为出色,其次是OpenCI-DS-6.7B和DS-33B-INST。这些模型通过指令调优(instruction tuning)增强了其指令遵循能力,从而在解决各种代码相关任务中取得了显著的性能提升。然而,即使在经过指令调优的情况下,这些开源模型在某些编辑任务中仍然无法与闭源模型相匹敌。
2. 不同编辑任务的模型表现
在不同的代码编辑任务中,模型的表现也存在显著差异。GPT-4在代码调试(Debug)、代码翻译(Translate)和代码需求转换(Switch)任务中表现出色,而在代码优化(Polish)任务中表现不足。类似地,Gemini-Ultra在代码优化任务中表现良好,但在代码需求转换任务中表现较差。这些结果表明,不同的模型可能在特定类型的编辑任务中具有不同的优势和局限性。

挑战与发现:模型在代码编辑任务中的局限
在对LLMs进行代码编辑任务的评估中,我们发现了一些挑战和局限性。首先,尽管闭源模型在多数情况下表现优于开源模型,但在代码需求转换任务中,即使是性能最强的闭源模型也存在明显的局限性。例如,Gemini-Ultra和Gemini-Pro在这类任务中的表现不如其他闭源模型。
其次,我们的分析揭示了模型在不同问题类型中的通过率分布存在显著差异。在PLUS数据集中,代码需求转换问题被认为是最具挑战性的,通过率仅为11.18%。代码调试和代码翻译问题的通过率分别约为20%和30%,而代码优化问题的通过率为37.47%。此外,我们还发现,即使在提供了正确的原始代码的情况下,仍有大量的解决方案未能满足所有测试标准,或者在平均运行时间或内存效率方面未能显示出优于原始代码的性能。
最后,我们对CodeEditorBench_Plus中所有模型的聚合解决方案进行了分析,发现只有20.34%的解决方案成功解决了问题,而有55.26%的解决方案因答案错误而失败。其他常见的失败原因包括编译错误和运行时错误,而超时或内存限制超出的情况相对较少。这些发现强调了CodeEditorBench在现代软件开发中提出的挑战,并突显了进一步研究的领域。
结论与展望:CodeEditorBench对未来研究的贡献
CodeEditorBench作为一个评估大型语言模型(LLMs)在代码编辑任务中性能的评测框架,为未来的研究提供了重要的贡献。首先,它通过引入一个全面的评估体系,强调了软件开发实践中代码编辑的重要性,这一点在现有的以代码生成为主的评估方法中往往被忽视。其次,CodeEditorBench通过从五个不同的来源策划多样化的编程挑战和场景,覆盖了各种编程语言、复杂度水平和编辑任务,这为研究人员提供了一个丰富的数据集,以测试和改进LLMs的代码编辑能力。
此外,CodeEditorBench的评估结果揭示了闭源模型(尤其是Gemini-Ultra和GPT-4)在代码编辑任务上的优越性能,这为开源和闭源模型在不同问题类型和提示敏感性上的性能差异提供了有价值的见解。通过这些发现,CodeEditorBench不仅为研究人员提供了一个强大的平台来评估代码编辑能力,而且还为实践者提供了一个宝贵的资源,以便更好地理解和利用LLMs在软件开发中的潜力。
未来,CodeEditorBench计划公开所有的提示和数据集,以便社区扩展数据集并对新兴的LLMs进行基准测试。这将有助于推动LLMs在代码编辑方面的进步,并为研究人员提供一个统一的框架进行评估、可视化、训练和进一步分析。CodeEditorBench还计划在未来引入更多的评估指标,以更全面地衡量LLMs的性能。
总结
在本研究中,我们引入了CodeEditorBench,这是一个旨在评估大型语言模型(LLMs)在代码编辑任务中性能的先驱性基准测试。CodeEditorBench被设想为一个动态且可扩展的框架,将定期更新以纳入新的问题、场景和模型。我们的发现表明,封闭源模型,特别是Gemini-Ultra和GPT-4,在CodeEditorBench_Plus中优于开源对手,展现出在各种问题解决场景中的卓越性能。这些模型在特定领域,包括代码优化和代码需求转换方面表现出了异常的熟练程度。
此外,分析还强调了模型性能基于问题类别和场景的变化性,揭示了模型对提示构造的敏感性趋势,并突出了在效率方面较小模型超越其更大对手的实例。通过建立一个全面的评估平台,CodeEditorBench旨在促进LLMs在代码编辑方面的进步,并为研究人员和实践者提供宝贵资源。
这篇关于大模型的代码编辑力:CodeEditor揭示GeminiUltra和GPT4的超凡实力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






