本文主要是介绍使用硬盘对拷方法将数据无损转移到另一个硬盘!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

硬盘对拷,其实就是磁盘克隆,很多人喜欢将其说成对拷,或者硬盘复制等,但不管怎么说,他们的目的都是一个,想要把原硬盘上的全部数据(包括系统、程序、个人文件、隐藏配置数据等)都无损迁移到新硬盘中。
硬盘对拷有什么用?
我们一般在什么时候会用到硬盘对拷这项小技巧呢?其实主要分为以下2点:
① 升级硬盘。比如旧硬盘性能或空间不行了,想要升级更好的硬盘,如果能够直接把旧硬盘数据全部转移到新硬盘上,那就可以不用重装系统,很方便。
② 备份硬盘。除了传统的镜像备份之外,其实克隆也算是一种备份方式,它可以创建一个源硬盘的精确副本,如果旧硬盘出了问题,就可以直接把克隆的硬盘顶上去,快速恢复系统业务。
怎么进行硬盘对拷?
那么我们该怎么进行硬盘对拷呢?难道直接用复制粘贴方法?那肯定是不行的,复制粘贴虽然对于一些文件层面的东西来说很好用,但是对于硬盘层面的数据来说旧不行了,因为很多隐藏的系统配置或者引导配置文件是没办法复制粘贴到的。
而且Windows也没提供相关的功能,所以建议大家选择专业的克隆工具,比如傲梅轻松备份。克隆功能很强大,支持MBR与GPT磁盘之间相互克隆,而且操作起来也很简单,点几下就可以轻松将硬盘数据无损克隆到另一个硬盘。
1. 到傲梅轻松备份官网下载按照傲梅轻松备份,然后把你的新硬盘正确安装或连接到电脑。
2. 打开傲梅轻松备份,点击“克隆”>“磁盘克隆”。
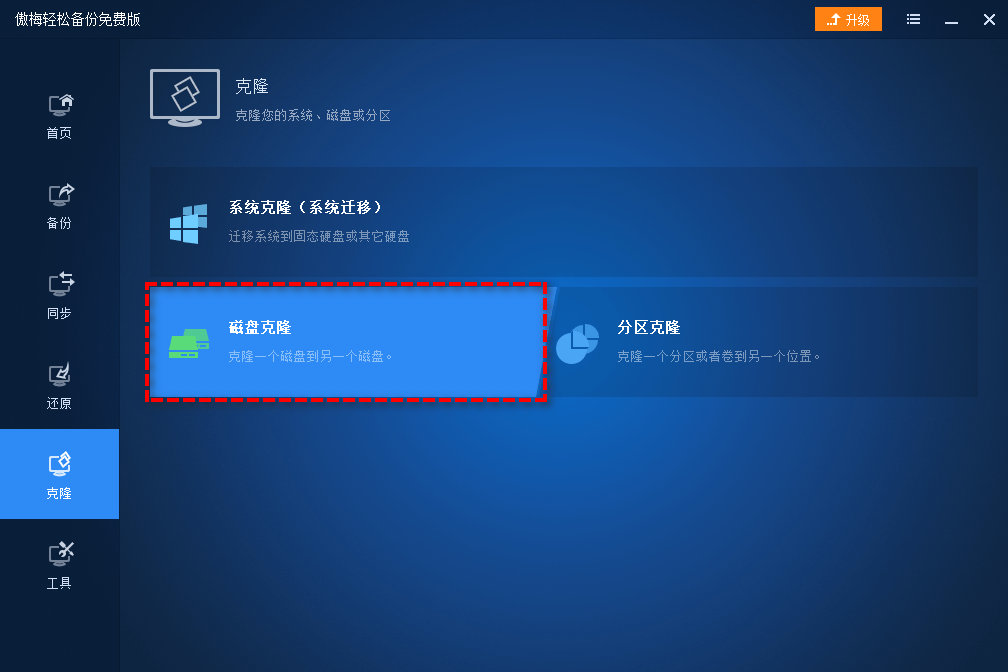
3. 选择旧硬盘作为源磁盘,选择新硬盘作为目标磁盘,点击“下一步”。

4. 接下来是操作摘要界面,检查检查即将进行的任务是否配置正确,没问题的话就点击“开始克隆”即可开始硬盘对拷任务,耐心等待其执行完毕即可。
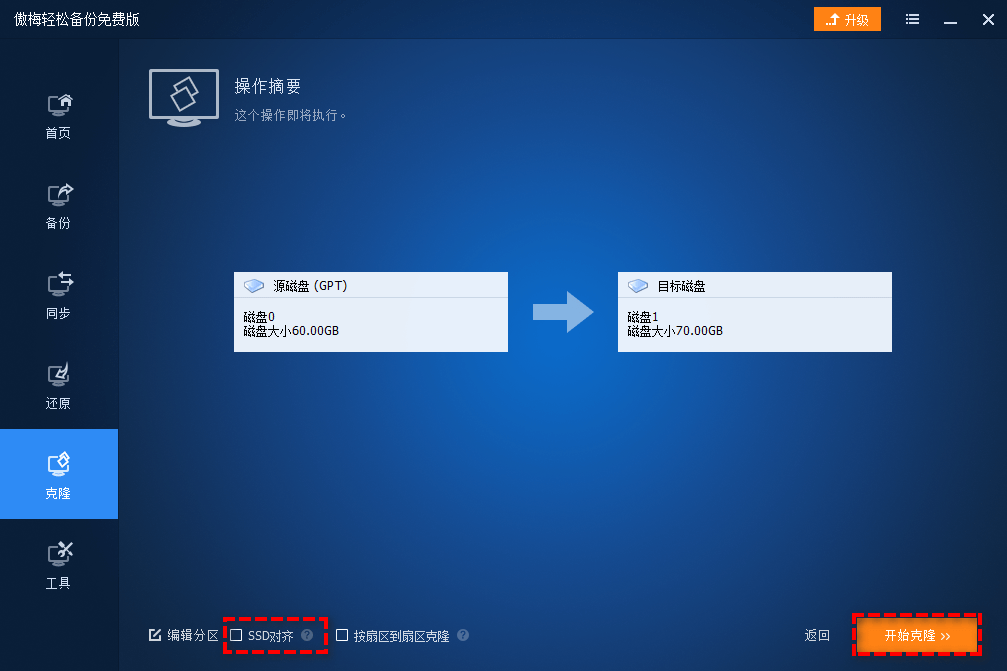
- 如果你想调整一下克隆后硬盘上的分区大小或位置,可以点击编辑分区选项自行设置。
- 如果你的目标硬盘是固态硬盘,可以勾一下SSD对齐选项,可以对齐4K分区,优化读写速度。
- 如果你想获取源硬盘的精确副本,可以勾选按扇区到扇区克隆选项,但是它花费的时间会更长,也要求目标硬盘空间大于等于源硬盘,正常情况下不是很建议勾选此项。
结论
硬盘对拷可以帮助我们把一个硬盘上的全部数据都无损转移到另一个硬盘上,无论是升级硬盘还是备份硬盘,都有很大的用处,但是Windows本身并没有提供此类功能,所以我们还是更加建议大家选择专业的傲梅轻松备份来完成这项任务。
这篇关于使用硬盘对拷方法将数据无损转移到另一个硬盘!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








