本文主要是介绍如何保证Redis双写一致性?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
数据不一致问题
数据库和缓存不一致解决方案
1. 先更新缓存,再更新数据
该方案数据不一致的原因
2. 先更新数据库,再更新缓存
3. 先删除缓存,再更新数据库
延时双删
4. 先更新数据库,再删除缓存
该方案数据不一致的场景和解决办法
缓存删除失败,该如何处理?
MQ异步重试删除
监控binlog删除
面试中关于Redis双写一致性,如何应答?
如何实现强一致性?
在数据库层和客户端层添加一层缓存,可以提高用户的访问性能。
比如一些商品秒杀业务,这时并发量高,要是所有请求都是打到数据库层(用MySQL举例),那用户的体验可能就不太好,因为操作数据库是要操作磁盘,性能比较低。而中间加一层缓存(用Redis举例),把数据存储在Redis中。Redis是基于内存的,操作速度极快,那并发量就可以提高了。
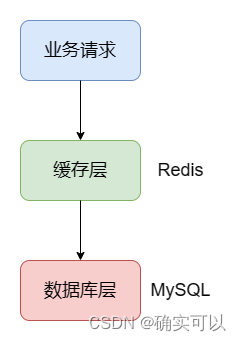
数据不一致问题
那就会引出问题,出现Redis和MySQL的数据不一致问题。由于缓存和数据库是分开的,无法做到原子性的同时进行数据修改,可能出现缓存更新失败,或者数据库更新失败的情况,这时候会出现数据不一致,影响业务。
数据库和缓存不一致解决方案
大方向有三种:
- Cache Aside Pattern 旁路缓存模式,也叫人工编码方式:需要程序员写代码 同时维系 DB 和 cache。也称作双写方案。
- Read/Write Through Pattern:缓存与数据库整合为一个服务,由服务来维护一致性。调用者调用该服务,无需关系缓存一致性问题。但是维护这样一个服务很复杂,市面上也不容易找到一个这样现成的服务,开发成本高。
- Write Behind Caching Pattern:调用者只操作缓存,其他线程异步去处理数据库,最终实现一致性。但是维护这样的一个异步任务比较复杂,需要实时监控缓存中的数据更新,而其他线程异步去更新数据库也可能不太及时,而且缓存服务器如果宕机,那么缓存的数据也就丢失了。
综上所述,在企业的实际应用中,还是Cache Aside Pattern方案最可靠。现在确定了该方案,但是需要程序员去调用缓存和数据库?那因为是两个应用,那操作就有先后顺序,那是应该先操作哪个呢?还有是更新缓存还是删除缓存呢?
可以分成4种情况:
- 先更新缓存,再更新数据
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
现在来逐个分析下其优缺点和是否可用。
1. 先更新缓存,再更新数据
首先给结论——该方案不可行。
场景1:事务问题导致数据不一致
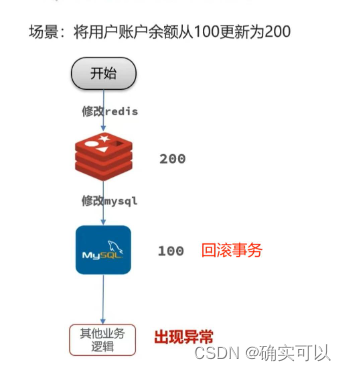
在MySQL写入或者其他业务逻辑出现异常错误时候,MySQL会进行回滚,那MySQL中数据会变回100,而Redis就会更新为100,这就出现了数据不一致问题。
这个就是因为Redis和MySQL两个数据库写操作不具备事务的ACID特性,无法保证这两个写操作的原子性。
发生该问题的场景有如下两个:
- 修改Redis成功,修改MySQL失败,而Redis不会回滚
- 整个过程其他业务逻辑出现异常,MySQL会回滚,而Redis却不会回滚。
场景2:多并发更新
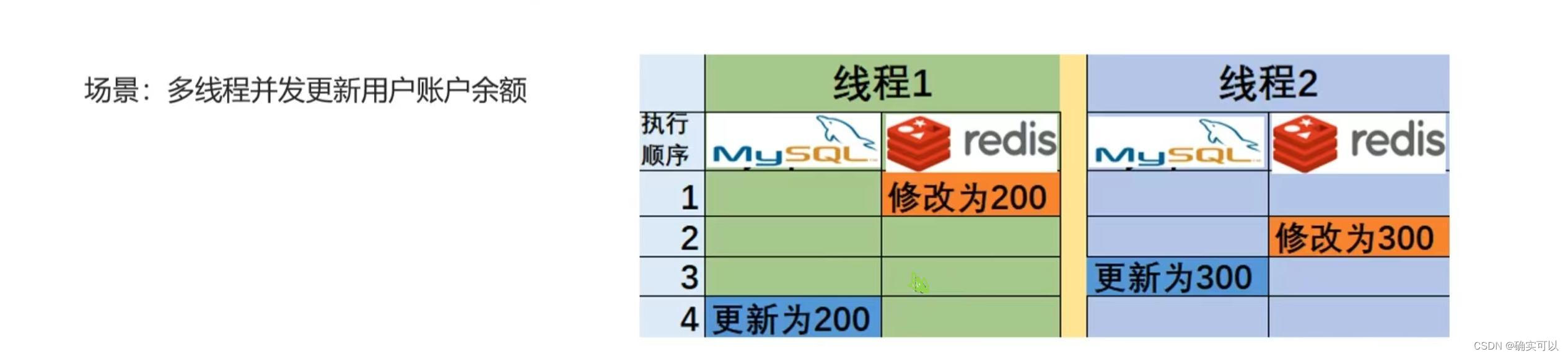
上图所示,线程1修改Redis数据,之后线程2抢占了cpu时间,那MySQL最终结果是200,就和Redis的数据不一致。这就是线程并发导致数据覆盖,造成数据不一致。
所以,先更新缓存,再更新数据库这种方法不可行。
该方案数据不一致的原因
- 不同数据库之间双写不具备事务原子性,造成数据不一致
- 线程并发导致数据覆盖,造成数据不一致
2. 先更新数据库,再更新缓存
首先给结论——该方案不可行。
原因和先更新缓存,再更新数据库是一样的。
场景1:修改账户余额,整个过程其他业务逻辑出现异常,MySQL进行回滚,而Redis却不会回滚。
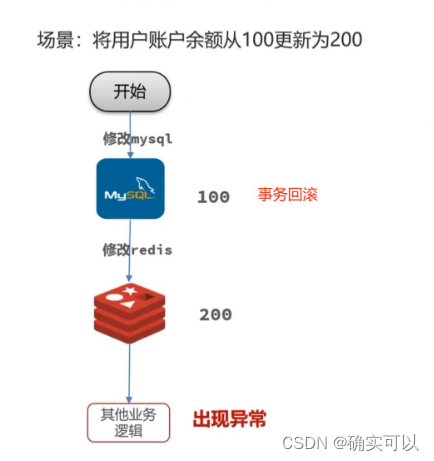
场景二:多线程并发更新用户账户余额
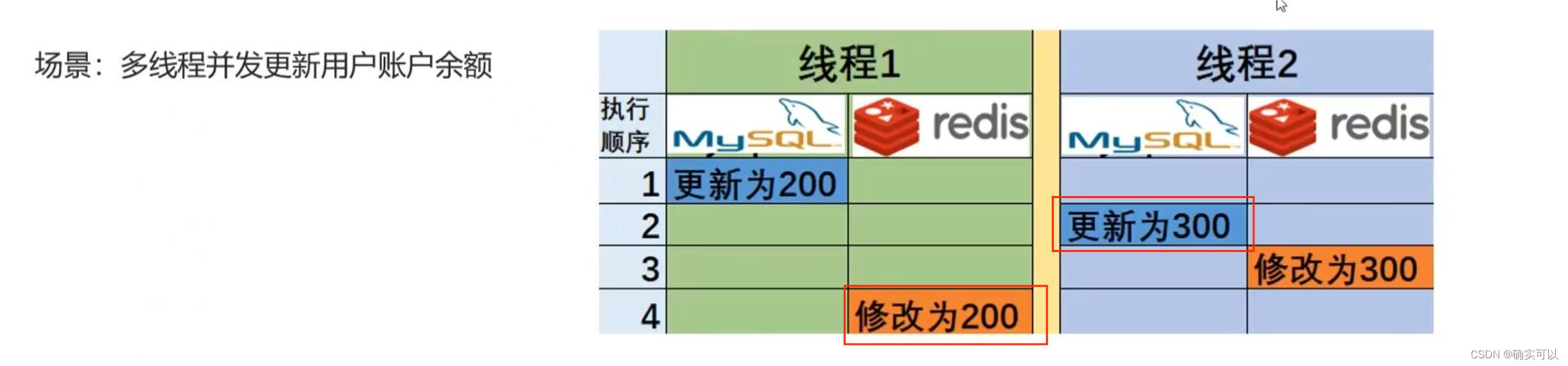
也是因为并发,线程1修改数据库后,线程2抢占了cpu时间,最终导致结果不一致。
所以先更新数据库,再更新缓存 也不行。
两点原因:
- 不同数据库之间双写不具备事务原子性,造成数据不一致
- 线程并发导致数据覆盖,造成数据不一致
3. 先删除缓存,再更新数据库
场景:多线程并发更新用户余额
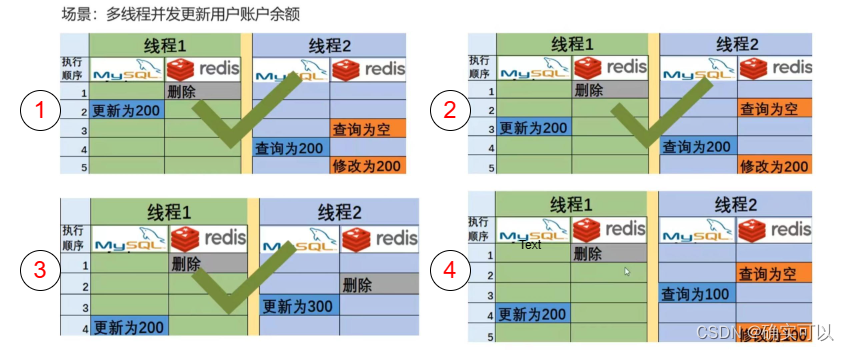
上图的情况①、②、③都不会导致数据不一致,而情况④会导致数据不一致。线程1在Redis中删除,之后线程2抢占cpu时间,去查询Redis,而Redis数据是空,那就需要去查询MySQL 。导致了最终Mysql数据是200,而Redis为100。
那使用这个方法,还有什么其他策略可以修复情况④吗?也是可以的,这个就是延时双删。
延时双删
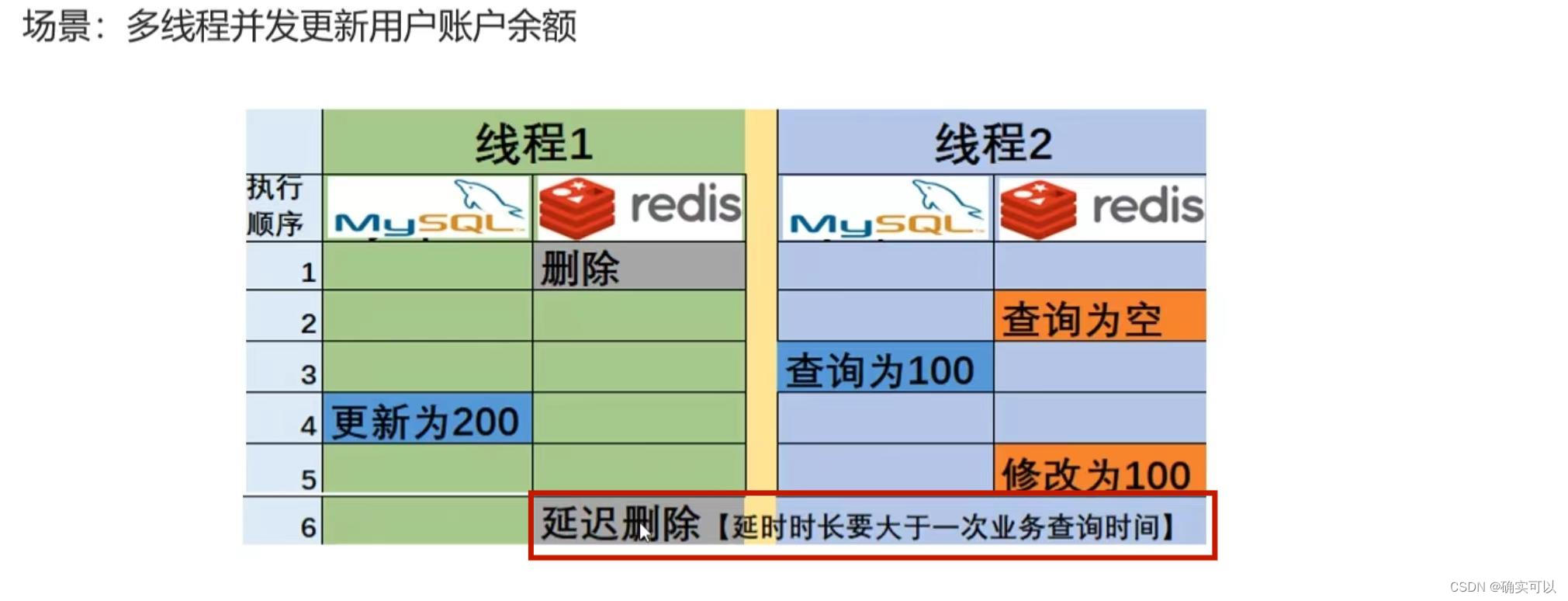
在线程1更新完数据库后,再次删除Redis中的数据,目的是为了清楚缓存中的脏数据。那么,对这个删除执行的时刻是有要求的,不能在线程2修改前执行,一般其时长是要大于一次业务查询时间,所以这个就是延时双删。
其实这个时长不好掌控,有时有些业务的查询时间可长可短。
4. 先更新数据库,再删除缓存
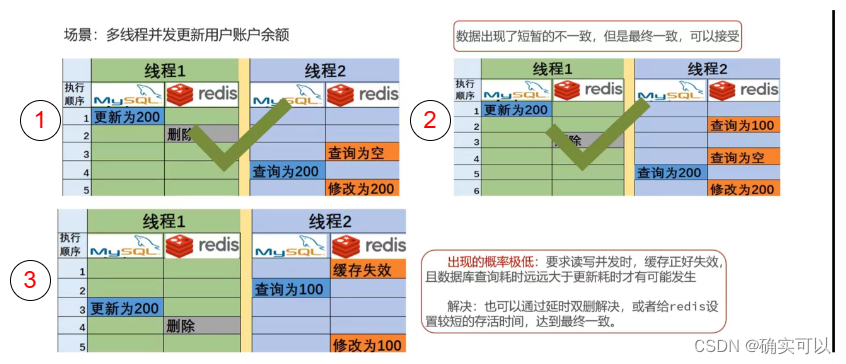
情况①是正常的。情况②出现了短暂的数据不一致问题,那这个就需要业务可以接受。
情况③就出现了较长时间的数据不一致情况。
那其是在什么情况出现的呢?要满足下面两个条件,其效率是很低的
- 在读写并发时候,缓存刚好失效,
- 且数据库查询耗时远大于更新耗时
所以,先更新数据库,再删除缓存 方案可用。但是要允许读写并发场景下出现短暂不一致情况,和极端情况下产生的数据不一致情况,但是数据是最终一致的。
该方案数据不一致的场景和解决办法
- 并发读写情况下产生的短暂不一致场景,业务场景要能接受。
- 并发读写情况下,缓存正好失效且读操作耗时大于写操作而产生的数据不一致。可以通过延时删除,或者给redis设置较短的存活时间。
缓存删除失败,该如何处理?
MySQL更新失败可以回滚,而Redis删除失败,却不会回滚。那该如何处理缓存删除失败的情况呢?
MQ异步重试删除
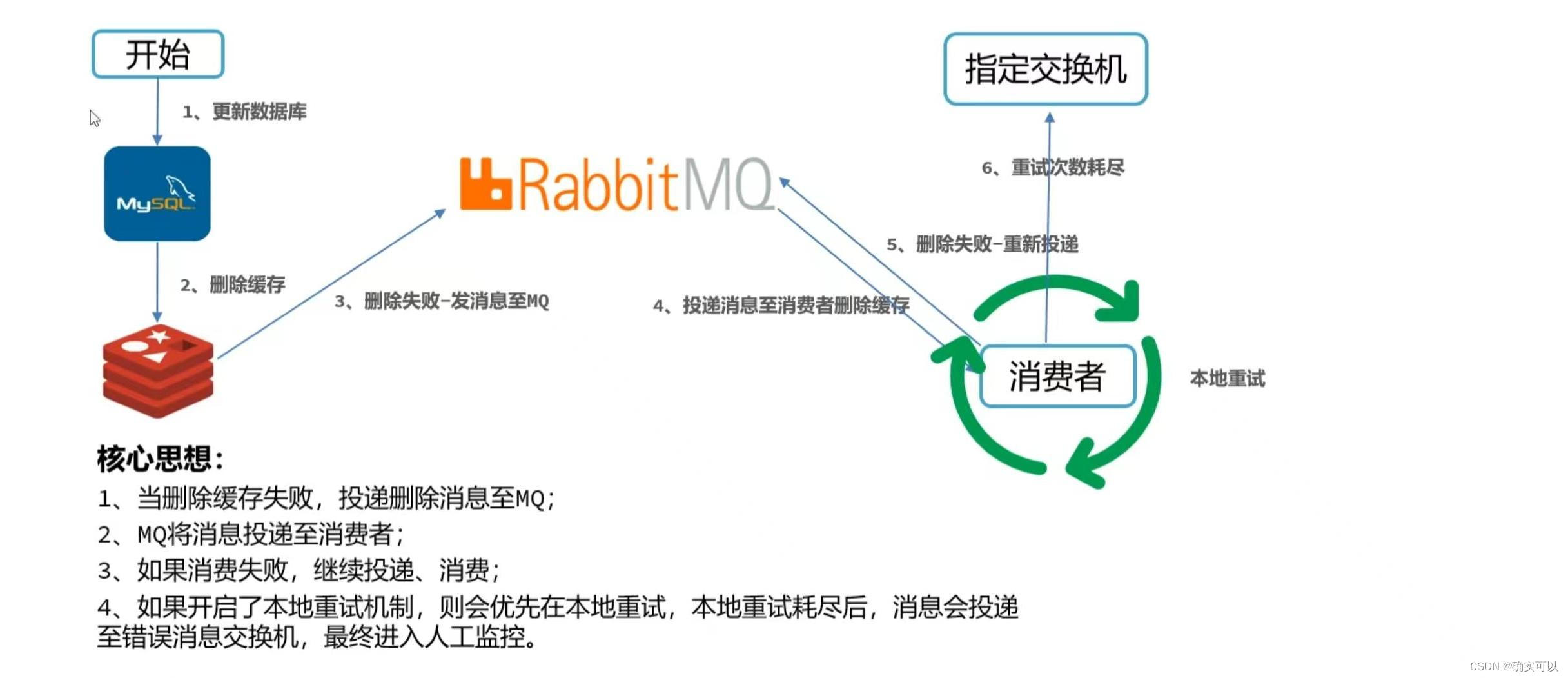
其优点就是实现简单,容易理解。
缺点就是添加了个组件,那整个系统的可用性又要维护多一个组件;并且耦合度比较高,那每次使用Redis时候,都需要写判断是否成功,不成功就抛给mq的代码。
监控binlog删除
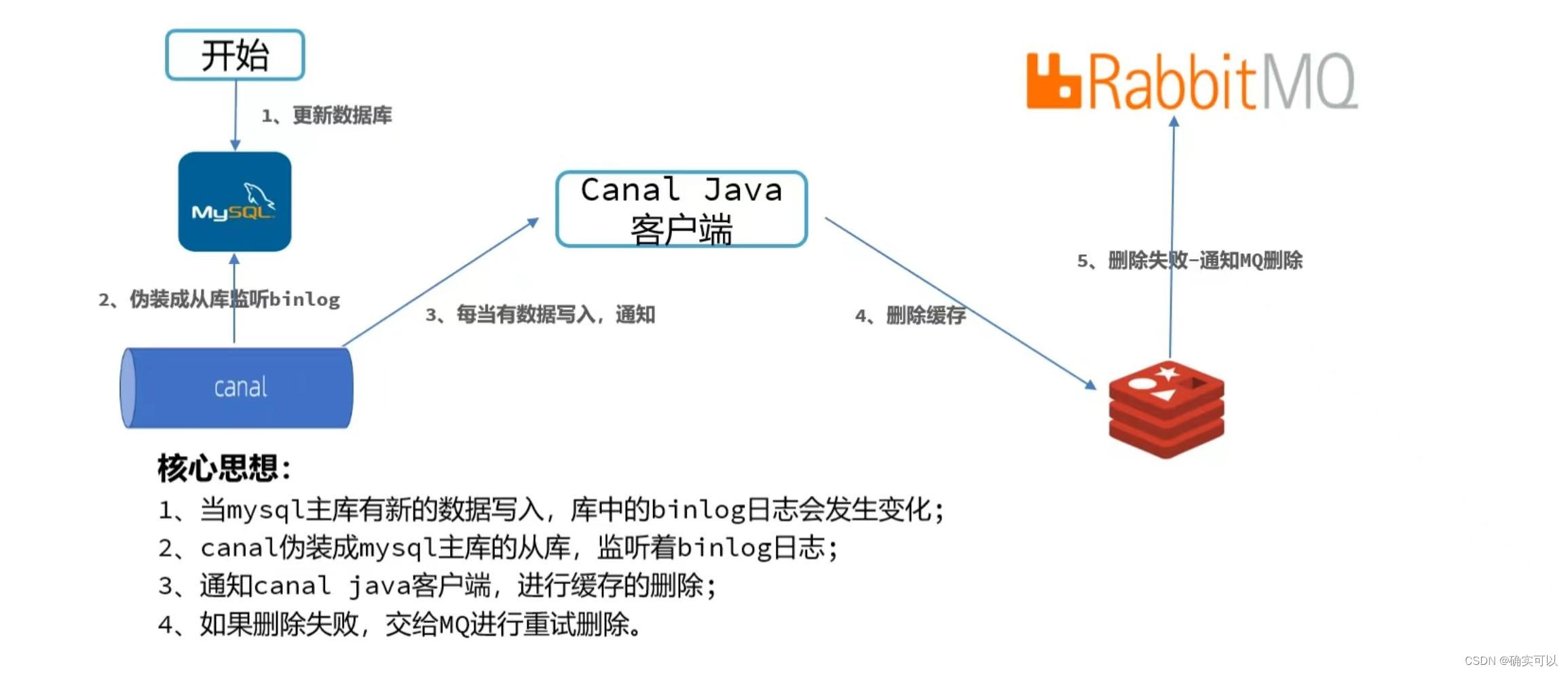
其优点:实现了缓存删除的业务解耦
缺点:实现是比较复杂的。
面试中关于Redis双写一致性,如何应答?
分成4步:
- 摆方案:保证Redis与MySQL数据库的双写一致性,大方向有三种方案:Cache Aside Pattern 旁路缓存模式、Read/Write Through Pattern缓存与数据库整合为一个服务、Write Behind Caching Pattern。而企业中大多数是使用Cache Aside Pattern:查询的时候,优先从缓存中查,缓存中没有数据再从数据库中查,然后把数据库中的最新值写入到缓存中,保证了数据一致性。
- ● 该模式有四种方案:①先更新缓存,再更新数据库、②先更新数据,再更新缓存、③先删除缓存,再更新数据库、④先更新数据,再删除缓存。
- 排除不合理的方案:两种双更新的方案不可用,原因有两个:
- 第一是因为我们不能保证两个数据库之间写操作的事务原子性,所以可能有一个成功一个失败,造成数据不一致。
- 第二是因为并发写操作会造成数据的覆盖,导致数据不一致。
- 列可用方案,阐述注意事项:目前常用的,但是这两个问题对于很多业务场景都可以容忍的方案有两个。
- 先删除缓存,再更新数据库:该方案理想情况下是没有问题的。但还是有一个特殊场景是有可能出现数据不一致,具体来讲是在发生并发读写时,线程A先删除了缓存,还没来得及更新数据库,线程B此时来查询缓存为空,于是查询到了数据库的旧值,而后将缓存修改成了旧值,解决方案就是采用延时双删,在线程A更新完数据库后延时一段时间再删除缓存,合理的延长时长需要更具业务而定,通常为一次查询业务的耗时。
- 先更新数据库,再删除缓存:该方案在理想情况下,也是没有问题的。但是该方案有两个特殊场景是有可能出现数据不一致问题的,第一种是由于并发读写导致的短暂不一致,但是最终数据一致。第二种场景出现几率很低,要求并发读写时缓存正好失效,且数据库查询耗时远远大于更新耗时才有可能发生数据不一致,这个当然也是可以通过延时双删或者给Redis数据设置较短的存活时间来达到最终一致。
- 对比这两个方案,最终还是使用先更新数据库,再删除缓存。
- 补充如何保证缓存成功删除:之前两种方案都是通过删除缓存来保证双写一致性的,要是缓存删除失败会导致缓存中都是脏数据,所以必须保证缓存删除成功,方案有两种:
- 第一种:使用MQ异步重试删除,比较简单,缺点是会对业务代码产生入侵,耦合度比较高。
- 第二种:使用阿里的canal模拟MySQL的从库,监听主库的binlog,当数据库发生变更,canal可以监听到并通知客户端去删除缓存,其优点是对业务代码没有入侵性,进行了解耦。
如何实现强一致性?
最终我们还有一个问题没有解决:不论是以上介绍的哪种方案,都会出现数据不一致性,只是出现这个问题的时间长短不同或者是出现的概率高低不同。
仔细想想,我们加入缓存的初衷是什么,不就是提高吞吐量,获得更高的性能嘛。作为开发者,应该都知道一个非常著名的三角悖论(CAP定理),即对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) 所有节点在同一时间具有相同的数据
- 可用性(Availability)保证每个请求不管成功或者失败都有响应
- 分区容错性(Partition tolerance)系统中任意信息的丢失或失败不会影响系统的继续运作
在分布式系统内,P 是必然需要的。不选 P,一旦发生分区错误,整个分布式系统就完全无法使用了,这是不符合实际需要的。所以,对于分布式系统,我们只能考虑当发生分区错误时,如何选择一致性和可用性。即只能从CP、AP中选择。既然选择了高性能和高吞吐量,所以我们只能满足AP。由此也可明白,以上介绍的所有方案都是为了保证将不一致性尽可能的降低,都是保证最终一致性。
如果一定要强一致性,就是不加入缓存;或者使用分布式锁或者读写锁来锁住一次更新数据库和缓存的操作,那这样吞吐量,性能有会下载,可能是得不偿失。
这篇关于如何保证Redis双写一致性?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





