本文主要是介绍Dubbo分析之Serialize层,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Dubbo整体设计
关于Dubbo的整体设计可以查看官方文档,下图可以清晰的表达Dubbo的整体设计: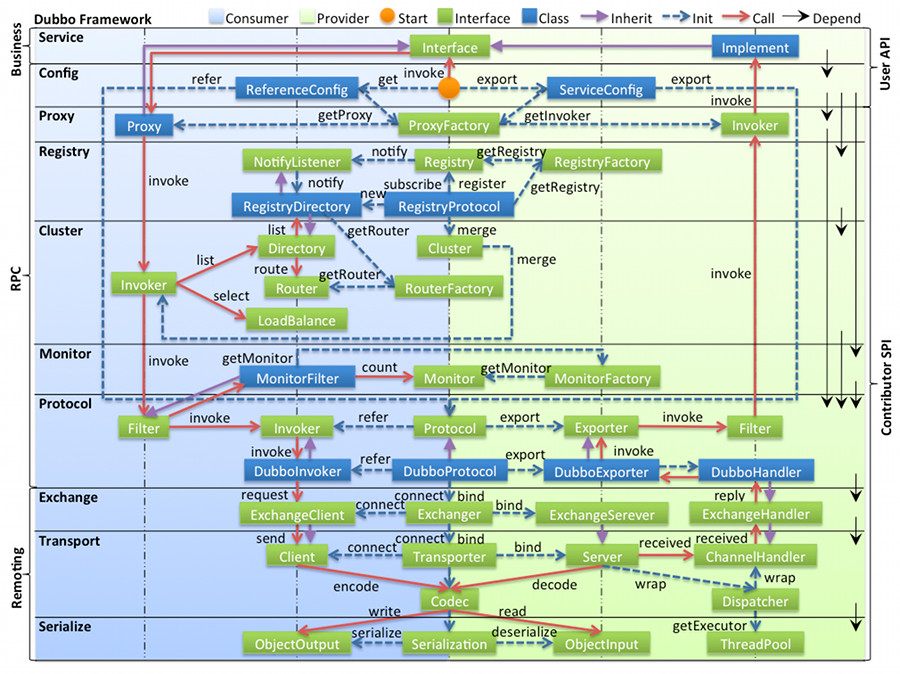
1.图例说明
图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口;
图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系;
图中绿色小块的为扩展接口,蓝色小块为实现类,图中只显示用于关联各层的实现类;
图中蓝色虚线为初始化过程,即启动时组装链,红色实线为方法调用过程,即运行时调时链,紫色三角箭头为继承,可以把子类看作父类的同一个节点,线上的文字为调用的方法;
2.各层说明
config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类;
proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory;
registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService;
cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance;
monitor 监控层:RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService;
protocol 远程调用层:封装 RPC 调用,以 Invocation, Result 为中心,扩展接口为 Protocol, Invoker, Exporter;
exchange 信息交换层:封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer;
transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec;
serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool;
本文将从最底层的serialize层开始来对dubbo进行源码分析;
通讯框架
dubbo的底层通讯使用的是第三方框架,包括:netty,netty4,mina和grizzly;默认使用的是netty,分别提供了server端(服务提供方)和client端(服务消费方);下面已使用的netty为例来看那一下NettyServer的部分代码:
protected void doOpen() throws Throwable {NettyHelper.setNettyLoggerFactory();ExecutorService boss = Executors.newCachedThreadPool(new NamedThreadFactory("NettyServerBoss", true));ExecutorService worker = Executors.newCachedThreadPool(new NamedThreadFactory("NettyServerWorker", true));ChannelFactory channelFactory = new NioServerSocketChannelFactory(boss, worker, getUrl().getPositiveParameter(Constants.IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS));bootstrap = new ServerBootstrap(channelFactory);final NettyHandler nettyHandler = new NettyHandler(getUrl(), this);channels = nettyHandler.getChannels();// https://issues.jboss.org/browse/NETTY-365// https://issues.jboss.org/browse/NETTY-379// final Timer timer = new HashedWheelTimer(new NamedThreadFactory("NettyIdleTimer", true));bootstrap.setOption("child.tcpNoDelay", true);bootstrap.setPipelineFactory(new ChannelPipelineFactory() {@Overridepublic ChannelPipeline getPipeline() {NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);ChannelPipeline pipeline = Channels.pipeline();/*int idleTimeout = getIdleTimeout();if (idleTimeout > 10000) {pipeline.addLast("timer", new IdleStateHandler(timer, idleTimeout / 1000, 0, 0));}*/pipeline.addLast("decoder", adapter.getDecoder());pipeline.addLast("encoder", adapter.getEncoder());pipeline.addLast("handler", nettyHandler);return pipeline;}});// bindchannel = bootstrap.bind(getBindAddress());}在启动服务提供方时就会调用此doOpen方法,用来启动服务端口,供消费方连接;以上代码就是常规的启动nettyServer端代码,因为本文重点介绍dubbo的序列化,所以这里主要看decoder和encoder,这两个类分别定义在NettyCodecAdapter中:
private final ChannelHandler encoder = new InternalEncoder();
private final ChannelHandler decoder = new InternalDecoder();1.编码器
在NettyCodecAdapter定义了内部类InternalEncoder:
private class InternalEncoder extends OneToOneEncoder {@Overrideprotected Object encode(ChannelHandlerContext ctx, Channel ch, Object msg) throws Exception {com.alibaba.dubbo.remoting.buffer.ChannelBuffer buffer =com.alibaba.dubbo.remoting.buffer.ChannelBuffers.dynamicBuffer(1024);NettyChannel channel = NettyChannel.getOrAddChannel(ch, url, handler);try {codec.encode(channel, buffer, msg);} finally {NettyChannel.removeChannelIfDisconnected(ch);}return ChannelBuffers.wrappedBuffer(buffer.toByteBuffer());}}此类其实是对codec的包装,本身并没有做编码处理,下面重点看一下codec类,此类是一个接口类,有多种实现类,Codec2源码如下:
@SPI
public interface Codec2 {@Adaptive({Constants.CODEC_KEY})void encode(Channel channel, ChannelBuffer buffer, Object message) throws IOException;@Adaptive({Constants.CODEC_KEY})Object decode(Channel channel, ChannelBuffer buffer) throws IOException;enum DecodeResult {NEED_MORE_INPUT, SKIP_SOME_INPUT}}实现包括:TransportCodec,TelnetCodec,ExchangeCodec,DubboCountCodec以及ThriftCodec,当然也可以自行扩展;不可能启动时把每种类型都加载,dubbo是通过在配置文件中配置好所有的类型,然后在运行中需要什么类加载什么类,
配置文件的具体路径:META-INF/dubbo/internal/com.alibaba.dubbo.remoting.Codec2,内容如下:
transport=com.alibaba.dubbo.remoting.transport.codec.TransportCodec
telnet=com.alibaba.dubbo.remoting.telnet.codec.TelnetCodec
exchange=com.alibaba.dubbo.remoting.exchange.codec.ExchangeCodec
dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboCountCodec
thrift=com.alibaba.dubbo.rpc.protocol.thrift.ThriftCodec获取具体Codec2的代码如下:
protected static Codec2 getChannelCodec(URL url) {String codecName = url.getParameter(Constants.CODEC_KEY, "telnet");if (ExtensionLoader.getExtensionLoader(Codec2.class).hasExtension(codecName)) {return ExtensionLoader.getExtensionLoader(Codec2.class).getExtension(codecName);} else {return new CodecAdapter(ExtensionLoader.getExtensionLoader(Codec.class).getExtension(codecName));}
}通过在url中获取是否有关键字codec,如果有的话就获取当前的值,dubbo默认的codec为dubbo;如果没有值默认为telnet;这里有默认值为dubbo,所以实现类DubboCountCodec会被ExtensionLoader进行加载并进行缓存,下面具体看一下DubboCountCodec的编解码;
private DubboCodec codec = new DubboCodec();@Override
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {codec.encode(channel, buffer, msg);
}DubboCountCodec内部调用的是DubboCodec的encode方法,看一下如何对Request对象进行编码的,具体代码块如下:
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {Serialization serialization = getSerialization(channel);// header.byte[] header = new byte[HEADER_LENGTH];// set magic number.Bytes.short2bytes(MAGIC, header);// set request and serialization flag.header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());if (req.isTwoWay()) header[2] |= FLAG_TWOWAY;if (req.isEvent()) header[2] |= FLAG_EVENT;// set request id.Bytes.long2bytes(req.getId(), header, 4);// encode request data.int savedWriteIndex = buffer.writerIndex();buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);ObjectOutput out = serialization.serialize(channel.getUrl(), bos);if (req.isEvent()) {encodeEventData(channel, out, req.getData());} else {encodeRequestData(channel, out, req.getData(), req.getVersion());}out.flushBuffer();if (out instanceof Cleanable) {((Cleanable) out).cleanup();}bos.flush();bos.close();int len = bos.writtenBytes();checkPayload(channel, len);Bytes.int2bytes(len, header, 12);// writebuffer.writerIndex(savedWriteIndex);buffer.writeBytes(header); // write header.buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);}前两个字节存放了魔数:0xdabb;第三个字节包含了四个信息分别是:是否是请求消息(还是响应消息),序列化类型,是否双向通信,是否是心跳消息;
在请求消息中直接跳过了第四个字节,直接在5-12位置存放了requestId,是一个long类型,第四个字节在如果是编码响应消息中会存放响应的状态;
代码往下看,buffer跳过了HEADER_LENGTH长度的字节,这里表示的是header部分的长度为16个字节,然后通过指定的序列化方式把data对象序列化到buffer中,序列化之后可以获取到data对象总共的字节数,用一个int类型来保存字节数,此int类型存放在header的最后四个字节中;
最后把buffer的writerIndex设置到写完header和data的地方,防止数据被覆盖;
2.解码器
在NettyCodecAdapter定义了内部类InternalEncoder,同样是调用DubboCodec的decode方法,部分代码如下:
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {int readable = buffer.readableBytes();byte[] header = new byte[Math.min(readable, HEADER_LENGTH)];buffer.readBytes(header);return decode(channel, buffer, readable, header);}@Overrideprotected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {// check magic number.if (readable > 0 && header[0] != MAGIC_HIGH|| readable > 1 && header[1] != MAGIC_LOW) {int length = header.length;if (header.length < readable) {header = Bytes.copyOf(header, readable);buffer.readBytes(header, length, readable - length);}for (int i = 1; i < header.length - 1; i++) {if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {buffer.readerIndex(buffer.readerIndex() - header.length + i);header = Bytes.copyOf(header, i);break;}}return super.decode(channel, buffer, readable, header);}// check length.if (readable < HEADER_LENGTH) {return DecodeResult.NEED_MORE_INPUT;}// get data length.int len = Bytes.bytes2int(header, 12);checkPayload(channel, len);int tt = len + HEADER_LENGTH;if (readable < tt) {return DecodeResult.NEED_MORE_INPUT;}// limit input stream.ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);try {return decodeBody(channel, is, header);} finally {if (is.available() > 0) {try {if (logger.isWarnEnabled()) {logger.warn("Skip input stream " + is.available());}StreamUtils.skipUnusedStream(is);} catch (IOException e) {logger.warn(e.getMessage(), e);}}}}首先读取Math.min(readable, HEADER_LENGTH),如果readable小于HEADER_LENGTH,表示接收方连头部的16个字节还没接受完,需要等待接收;正常header接收完之后需要进行检查,主要包括:魔数的检查,header消息长度检查,消息体长度检查(检查消息体是否已经接收完成);检查完之后需要对消息体进行反序列化,具体在decodeBody方法中:
@Overrideprotected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);Serialization s = CodecSupport.getSerialization(channel.getUrl(), proto);// get request id.long id = Bytes.bytes2long(header, 4);if ((flag & FLAG_REQUEST) == 0) {// decode response.Response res = new Response(id);if ((flag & FLAG_EVENT) != 0) {res.setEvent(Response.HEARTBEAT_EVENT);}// get status.byte status = header[3];res.setStatus(status);if (status == Response.OK) {try {Object data;if (res.isHeartbeat()) {data = decodeHeartbeatData(channel, deserialize(s, channel.getUrl(), is));} else if (res.isEvent()) {data = decodeEventData(channel, deserialize(s, channel.getUrl(), is));} else {DecodeableRpcResult result;if (channel.getUrl().getParameter(Constants.DECODE_IN_IO_THREAD_KEY,Constants.DEFAULT_DECODE_IN_IO_THREAD)) {result = new DecodeableRpcResult(channel, res, is,(Invocation) getRequestData(id), proto);result.decode();} else {result = new DecodeableRpcResult(channel, res,new UnsafeByteArrayInputStream(readMessageData(is)),(Invocation) getRequestData(id), proto);}data = result;}res.setResult(data);} catch (Throwable t) {if (log.isWarnEnabled()) {log.warn("Decode response failed: " + t.getMessage(), t);}res.setStatus(Response.CLIENT_ERROR);res.setErrorMessage(StringUtils.toString(t));}} else {res.setErrorMessage(deserialize(s, channel.getUrl(), is).readUTF());}return res;} else {// decode request.Request req = new Request(id);req.setVersion(Version.getProtocolVersion());req.setTwoWay((flag & FLAG_TWOWAY) != 0);if ((flag & FLAG_EVENT) != 0) {req.setEvent(Request.HEARTBEAT_EVENT);}try {Object data;if (req.isHeartbeat()) {data = decodeHeartbeatData(channel, deserialize(s, channel.getUrl(), is));} else if (req.isEvent()) {data = decodeEventData(channel, deserialize(s, channel.getUrl(), is));} else {DecodeableRpcInvocation inv;if (channel.getUrl().getParameter(Constants.DECODE_IN_IO_THREAD_KEY,Constants.DEFAULT_DECODE_IN_IO_THREAD)) {inv = new DecodeableRpcInvocation(channel, req, is, proto);inv.decode();} else {inv = new DecodeableRpcInvocation(channel, req,new UnsafeByteArrayInputStream(readMessageData(is)), proto);}data = inv;}req.setData(data);} catch (Throwable t) {if (log.isWarnEnabled()) {log.warn("Decode request failed: " + t.getMessage(), t);}// bad requestreq.setBroken(true);req.setData(t);}return req;}}首先通过解析header部分的第三个字节,识别出是请求消息还是响应消息,还有使用哪种类型的序列化方式,然后分别进行序列化;
序列化和反序列化
通过以上对编码器解码器的了解,在编码器中需要序列化Request/Response,在解码器中需要序列化Request/Response,下面具体看看序列化和反序列化;
1.序列化
在编码器中需要获取具体的Serialization,具体代码如下:
public static Serialization getSerialization(URL url) {return ExtensionLoader.getExtensionLoader(Serialization.class).getExtension(url.getParameter(Constants.SERIALIZATION_KEY, Constants.DEFAULT_REMOTING_SERIALIZATION));
}同获取codec的方式,dubbo也提供了多种序列化方式,同时可以自定义扩展;通过在url中获取serialization关键字,如果获取不到默认为hession2;同样多种序列化类也配置在一个文件中,
路径:META-INF/dubbo/internal/com.alibaba.dubbo.common.serialize.Serialization,具体内容如下:
fastjson=com.alibaba.dubbo.common.serialize.fastjson.FastJsonSerialization
fst=com.alibaba.dubbo.common.serialize.fst.FstSerialization
hessian2=com.alibaba.dubbo.common.serialize.hessian2.Hessian2Serialization
java=com.alibaba.dubbo.common.serialize.java.JavaSerialization
compactedjava=com.alibaba.dubbo.common.serialize.java.CompactedJavaSerialization
nativejava=com.alibaba.dubbo.common.serialize.nativejava.NativeJavaSerialization
kryo=com.alibaba.dubbo.common.serialize.kryo.KryoSerializationdubbo默认提供了fastjson,fst,hessian2,java,compactedjava,nativejava和kryo多种序列化方式;
每种序列化方式都需要实现如下三个接口类:Serialization,ObjectInput以及ObjectOutput;
Serialization接口类:
public interface Serialization {byte getContentTypeId();String getContentType();@AdaptiveObjectOutput serialize(URL url, OutputStream output) throws IOException;@AdaptiveObjectInput deserialize(URL url, InputStream input) throws IOException;}其中的ContentTypeId就是在header中存放的序列化类型,反序列化的时候需要通过此id获取具体的Serialization,所以此ContentTypeId不能出现重复的,否则会被覆盖;
ObjectInput接口类:
public interface ObjectOutput extends DataOutput {void writeObject(Object obj) throws IOException;
}ObjectOutput接口类:
public interface ObjectInput extends DataInput {Object readObject() throws IOException, ClassNotFoundException;<T> T readObject(Class<T> cls) throws IOException, ClassNotFoundException;<T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException;
}分别提供了读取对象和写对象的接口方法,DataOutput和DataInput分别提供了对基本数据类型的读和写;序列化只需要调用writeObject方法将Data写入数据流即可;具体可以看一下编码器中调用的encodeRequestData方法:
@Override
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {RpcInvocation inv = (RpcInvocation) data;out.writeUTF(version);out.writeUTF(inv.getAttachment(Constants.PATH_KEY));out.writeUTF(inv.getAttachment(Constants.VERSION_KEY));out.writeUTF(inv.getMethodName());out.writeUTF(ReflectUtils.getDesc(inv.getParameterTypes()));Object[] args = inv.getArguments();if (args != null)for (int i = 0; i < args.length; i++) {out.writeObject(encodeInvocationArgument(channel, inv, i));}out.writeObject(inv.getAttachments());
}默认使用的DubboCountCodec方式并没有直接将data写入流中,而是将RpcInvocation中的数据取出分别写入流;
2.反序列化
反序列化通过读取header中的序列化类型,然后通过如下方法获取具体的Serialization,具体在类CodecSupport中:
public static Serialization getSerialization(URL url, Byte id) throws IOException {Serialization serialization = getSerializationById(id);String serializationName = url.getParameter(Constants.SERIALIZATION_KEY, Constants.DEFAULT_REMOTING_SERIALIZATION);// Check if "serialization id" passed from network matches the id on this side(only take effect for JDK serialization), for security purpose.if (serialization == null|| ((id == 3 || id == 7 || id == 4) && !(serializationName.equals(ID_SERIALIZATIONNAME_MAP.get(id))))) {throw new IOException("Unexpected serialization id:" + id + " received from network, please check if the peer send the right id.");}return serialization;
}private static Map<Byte, Serialization> ID_SERIALIZATION_MAP = new HashMap<Byte, Serialization>();public static Serialization getSerializationById(Byte id) {return ID_SERIALIZATION_MAP.get(id);
}ID_SERIALIZATION_MAP存放着ContentTypeId和具体Serialization的对应关系,然后通过id获取具体的Serialization,然后根据写入的顺序读取数据;
扩展序列化类型
dubbo本身对很多模块提供了很好的扩展功能,包括序列化功能,以下来分析一下如何使用protobuf来实现序列化方式;
1.整体代码结构
首先看一下整体的代码结构,如下图所示: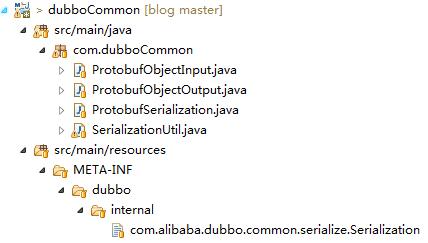
分别实现三个接口类:Serialization,ObjectInput以及ObjectOutput;然后在指定目录下提供一个文本文件;
2.引入扩展包
<dependency><groupId>com.dyuproject.protostuff</groupId><artifactId>protostuff-core</artifactId><version>1.1.3</version>
</dependency>
<dependency><groupId>com.dyuproject.protostuff</groupId><artifactId>protostuff-runtime</artifactId><version>1.1.3</version>
</dependency>3.实现接口ObjectInput和ObjectOutput
public class ProtobufObjectInput implements ObjectInput {private ObjectInputStream input;public ProtobufObjectInput(InputStream inputStream) throws IOException {this.input = new ObjectInputStream(inputStream);}....省略基础类型...@Overridepublic Object readObject() throws IOException, ClassNotFoundException {return input.readObject();}@Overridepublic <T> T readObject(Class<T> clazz) throws IOException {try {byte[] buffer = (byte[]) input.readObject();input.read(buffer);return SerializationUtil.deserialize(buffer, clazz);} catch (Exception e) {throw new IOException(e);}}@Overridepublic <T> T readObject(Class<T> clazz, Type type) throws IOException {try {byte[] buffer = (byte[]) input.readObject();input.read(buffer);return SerializationUtil.deserialize(buffer, clazz);} catch (Exception e) {throw new IOException(e);}}
}public class ProtobufObjectOutput implements ObjectOutput {private ObjectOutputStream outputStream;public ProtobufObjectOutput(OutputStream outputStream) throws IOException {this.outputStream = new ObjectOutputStream(outputStream);}....省略基础类型...@Overridepublic void writeObject(Object v) throws IOException {byte[] bytes = SerializationUtil.serialize(v);outputStream.writeObject(bytes);outputStream.flush();}@Overridepublic void flushBuffer() throws IOException {outputStream.flush();}
}4.实现Serialization接口
public class ProtobufSerialization implements Serialization {@Overridepublic byte getContentTypeId() {return 10;}@Overridepublic String getContentType() {return "x-application/protobuf";}@Overridepublic ObjectOutput serialize(URL url, OutputStream out) throws IOException {return new ProtobufObjectOutput(out);}@Overridepublic ObjectInput deserialize(URL url, InputStream is) throws IOException {return new ProtobufObjectInput(is);}
}这里引入了一个新的ContentTypeId,需要保证和dubbo里面已存在的不要冲突
5.指定目录提供注册
在META-INF/dubbo/internal/目录下提供文件com.alibaba.dubbo.common.serialize.Serialization,内容如下:
protobuf=com.dubboCommon.ProtobufSerialization6.在提供方配置新的序列化方式
<dubbo:protocol name="dubbo" port="20880" serialization="protobuf"/>这样就会使用新扩展的protobuf序列化方式来序列化对象;
总结
本文从dubbo整体设计的最底层serialization层来分析和了解dubbo,后面会逐层进行分析,对dubbo有一个更加透彻的了解;
这篇关于Dubbo分析之Serialize层的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




