本文主要是介绍Pandas数据可视化 - Matplotlib、Seaborn、Pandas Plot、Plotly,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
可视化工具介绍
让我们一起探讨Matplotlib、Seaborn、Pandas Plot和Plotly这四个数据可视化库的优缺点以及各自的适用场景。这有助于你根据不同的需求选择合适的工具。
1. Matplotlib
优点:
- 功能强大:几乎可以用于绘制任何静态、动画和交互式图表。
- 高度可定制:提供了细粒度的控制,可以精确调整图表的每个元素。
- 广泛的社区支持:由于长时间存在和广泛使用,有大量的教程和资源。
缺点:
- 学习曲线:初学者可能会觉得配置和语法复杂。
- 样式:默认样式不如一些现代库吸引人,需要手动调整以达到现代美观的视觉效果。
适用场景:
- 需要对图形进行精细控制的学术论文和专业报告。
- 对图表外观有特定需求的项目。
2. Seaborn
优点:
- 美观的默认设置:默认配置比Matplotlib更现代,更吸引人。
- 简化创建复杂图表的接口:如分布图和矩阵图,适合进行统计数据可视化。
- 良好的集成:与Pandas数据结构紧密集成,便于处理DataFrame。
缺点:
- 定制能力有限:虽然比Matplotlib简单,但在高级定制性方面不如Matplotlib灵活。
- 图表类型有限:主要专注于统计图表,其他类型的图表可能不支持。
适用场景:
- 快速探索性数据分析。
- 统计数据可视化,特别是需要展示数据分布和多变量关系的场景。
3. Pandas Plot
优点:
- 易用性:直接在DataFrame和Series上调用.plot()进行绘图,极大简化了数据可视化的步骤。
- 足够的图表类型:支持多种基础图表,满足基本分析需求。
缺点:
- 功能有限:缺少高级图表和定制选项。
- 依赖Matplotlib:继承了Matplotlib的一些限制,比如样式和交互性。
适用场景:
- 快速数据探索和初步分析。
- 需要从Pandas直接生成基本图表的场景。
4. Plotly
优点:
- 交互性强:支持动态图表和交互操作,如缩放、平移和悬停提示。
- 美观且现代:默认图表样式现代且具吸引力。
- 支持Web集成:易于嵌入网页和应用程序。
缺点:
- 性能:复杂图表在某些设备上可能响应较慢。
- 学习曲线:功能丰富但需要时间学习如何有效使用。
适用场景:
- 需要在网页或应用程序中嵌入交互式图表的场景。
- 数据可视化产品或服务,用户交互是关键考量因素。
总结来说,选择哪个库取决于你的具体需求:Matplotlib适合需要高度定制的场景,Seaborn适用于快速且美观的统计图表展示,Pandas Plot最适合直接从数据框架快速绘图,而Plotly则是在需要强交互性和吸
Matplotlib
Matplotlib 是一个非常强大的Python绘图库,用于创建高质量的图表。它提供了丰富的模块和函数来制作图形和绘图。
常用方法和参数
-
plt.plot(): 绘制线形图。x,y: 输入数据。color: 线条颜色。label: 图例标签。linewidth: 线条宽度。linestyle: 线条样式。
-
plt.scatter(): 绘制散点图。x,y: 输入数据。s: 点的大小。color: 点的颜色。marker: 点的形状。
-
plt.bar(): 绘制条形图。x,height: x 轴数据和高度。width: 条的宽度。color: 条的颜色。label: 图例标签。
-
plt.hist(): 绘制直方图。x: 输入数据。bins: 分组数量。color: 颜色。alpha: 透明度。
-
plt.xlabel(),plt.ylabel(): 设置x轴和y轴的标签。
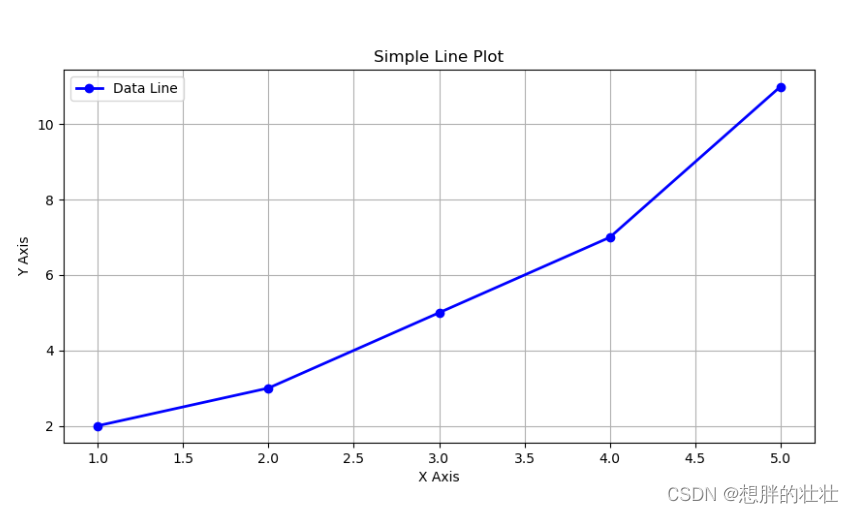
示例:线形图绘制
import matplotlib.pyplot as plt# 数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]# 创建图形
plt.figure(figsize=(10, 5))
plt.plot(x, y, color='blue', linewidth=2, linestyle='-', marker='o', label='Data Line')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.title('Simple Line Plot')
plt.legend()
plt.grid(True)
plt.show()
运行结果解释
这段代码会生成一个简单的线形图,其中x和y数据点用蓝色线条连接。每个数据点用圆形标记。图中还包含了x轴和y轴标签、标题、图例以及网格线。
常见问题及解决方案
-
问题: 图表中的文字重叠。
- 解决方案: 使用
plt.tight_layout()或调整plt.subplots_adjust()参数。
- 解决方案: 使用
-
问题: 图例遮挡了图形的一部分。
- 解决方案: 使用
plt.legend(loc='best')自动找到最佳位置。
- 解决方案: 使用
-
问题: 需要保存图表为图片文件。
- 解决方案: 使用
plt.savefig('filename.png')保存图表。
- 解决方案: 使用
-
问题: 中文显示乱码。
- 解决方案: 设置Matplotlib的字体参数,使用支持中文的字体。
-
问题: 图表的大小不合适。
- 解决方案: 调整
plt.figure(figsize=(width, height))中的尺寸参数。
- 解决方案: 调整
Seaborn
Seaborn 是专门为统计图表设计的,提供了更多的图表类型和美化功能。它与Pandas数据结构紧密集成,使得数据探索更加方便。
常用方法和参数
-
sns.lineplot(): 绘制线形图。x,y: 输入数据。hue: 用不同颜色表示不同类别。style: 线条样式,根据分类变化。markers: 每个点的标记。
-
sns.scatterplot(): 绘制散点图。x,y: 输入数据。hue: 根据分类变化颜色。style: 根据分类变化点的形状。size: 点的大小。
-
sns.barplot(): 绘制条形图。x,y: 输入数据。hue: 根据分类变化颜色。palette: 颜色方案。
-
sns.histplot(): 绘制直方图。data: 输入数据。bins: 分组数量。kde: 是否显示核密度估计。
-
sns.boxplot(): 绘制箱型图。x,y: 输入数据。hue: 根据分类变化颜色。
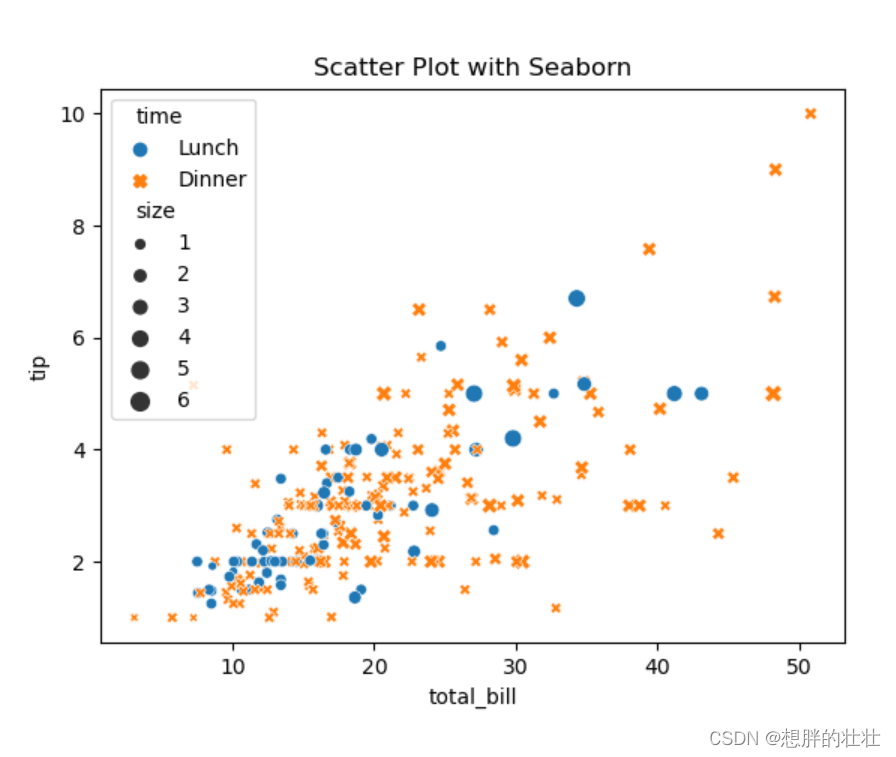
示例:多变量散点图
import seaborn as sns
import matplotlib.pyplot as plt# 数据
tips = sns.load_dataset('tips')# 创建图形
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time", style="time", size="size")
plt.title('Scatter Plot with Seaborn')
plt.show()
运行结果解释
这个示例中,我们使用Seaborn加载了内置的“tips”数据集,并创建了一个散点图,其中包含了不同时间段(午餐和晚餐)的总账单和小费信息。颜色和点的样式根据时间变化,点的大小表示桌子上的人数。
常见问题及解决方案
-
问题: Seaborn图形的样式与Matplotlib不一致。
- 解决方案: 使用
sns.set()来设置默认的图形样式,使其与Matplotlib协调。
- 解决方案: 使用
-
问题: 图例太大或位置不合适。
- 解决方案: 使用
plt.legend(loc='upper right', bbox_to_anchor=(1, 1))调整图例位置和大小。
- 解决方案: 使用
-
问题: 密度图显示不平滑。
- 解决方案: 在
sns.kdeplot()中增加bw_adjust参数来调整带宽。
- 解决方案: 在
-
问题: 柱状图中的柱子重叠。
- 解决方案: 调整
width参数来减少柱子的宽度。
- 解决方案: 调整
-
问题: 要分别对比多个分类变量。
- 解决方案: 使用
sns.pairplot()绘制多变量分布。
- 解决方案: 使用
现在我们来探讨 Pandas Plot,这是Pandas内置的绘图方法,建立在Matplotlib上。这个功能使得直接从DataFrame和Series数据结构进行图形绘制变得非常简便。
Pandas Plot
Pandas 的 .plot() 方法提供了一种快速绘图的方式,支持多种图表类型,非常适合于初步的数据分析。
常用方法和参数
.plot() 方法提供了多种绘图类型,通过 kind 参数来指定:
kind='line': 绘制线形图。kind='scatter': 绘制散点图,需要指定x和y。kind='bar'和kind='barh': 分别绘制垂直和水平的条形图。kind='hist': 绘制直方图。kind='box': 绘制箱型图。kind='pie': 绘制饼图。
其他常用参数包括:
color: 设置颜色。figsize: 图形的大小。title: 图表的标题。legend: 是否显示图例。grid: 是否显示网格。
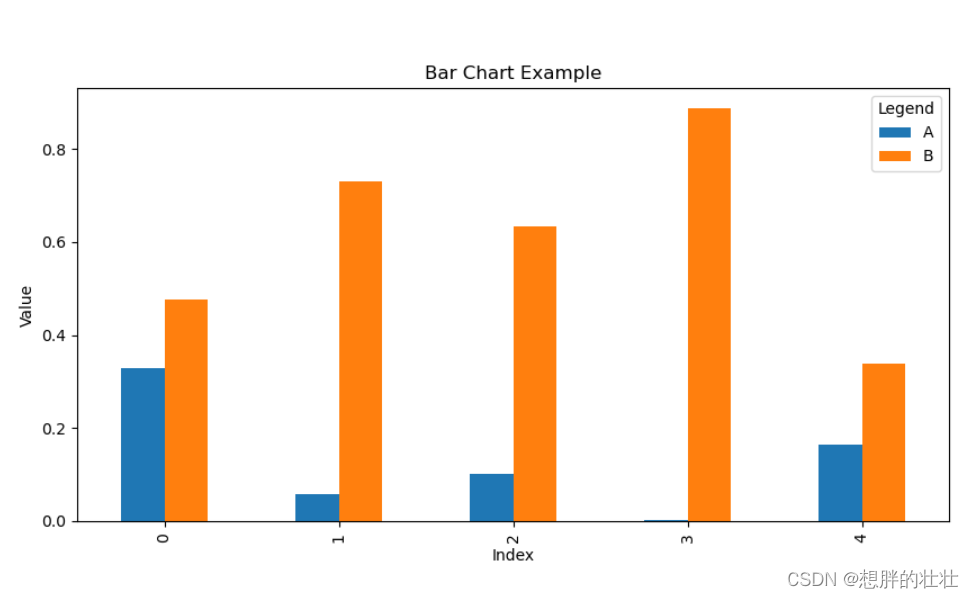
示例:条形图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 数据
data = pd.DataFrame({'A': np.random.rand(5),'B': np.random.rand(5)
})
# 创建条形图
ax = data.plot(kind='bar', figsize=(10, 5), title="Bar Chart Example")
ax.set_xlabel("Index")
ax.set_ylabel("Value")
ax.legend(title="Legend")
plt.show()
运行结果解释
这段代码生成了一个包含两组数据(A和B)的条形图。每个索引的位置显示了A和B的值,颜色不同以区分两者。
常见问题及解决方案
-
问题: 想要在条形图上显示数值。
- 解决方案: 在绘图之后,使用
ax.text()方法在条形图的每个条上添加文本。
- 解决方案: 在绘图之后,使用
-
问题: 想要更改图例的位置。
- 解决方案: 使用
ax.legend(loc='upper right')来指定图例的位置。
- 解决方案: 使用
-
问题: 需要调整轴的刻度标签的角度。
- 解决方案: 使用
plt.xticks(rotation=45)来旋转x轴标签。
- 解决方案: 使用
-
问题: 想要改变图表的风格。
- 解决方案: 使用
plt.style.use('ggplot')来应用不同的样式。
- 解决方案: 使用
-
问题: 图表保存为图片文件。
- 解决方案: 使用
plt.savefig('filename.png')保存图表。
- 解决方案: 使用
Plotly
Plotly 支持多种图表类型,包括线形图、散点图、条形图、饼图、箱型图等,都可以交互式地操作,如缩放、平移和悬停提示等。
常用方法和参数
-
px.line(): 创建线形图。data_frame: 数据框架。x,y: x和y轴的数据列。color: 根据分类变化颜色。title: 图表标题。
-
px.scatter(): 创建散点图。data_frame: 数据框架。x,y: x和y轴的数据列。color: 根据分类变化颜色。size: 点的大小。hover_data: 悬停时显示的额外数据。
-
px.bar(): 创建条形图。data_frame: 数据框架。x,y: x和y轴的数据列。color: 根据分类变化颜色。title: 图表标题。
-
px.histogram(): 创建直方图。data_frame: 数据框架。x: x轴的数据列。nbins: 条的数量。color: 颜色。
-
px.box(): 创建箱型图。data_frame: 数据框架。y: y轴的数据列。color: 根据分类变化颜色。
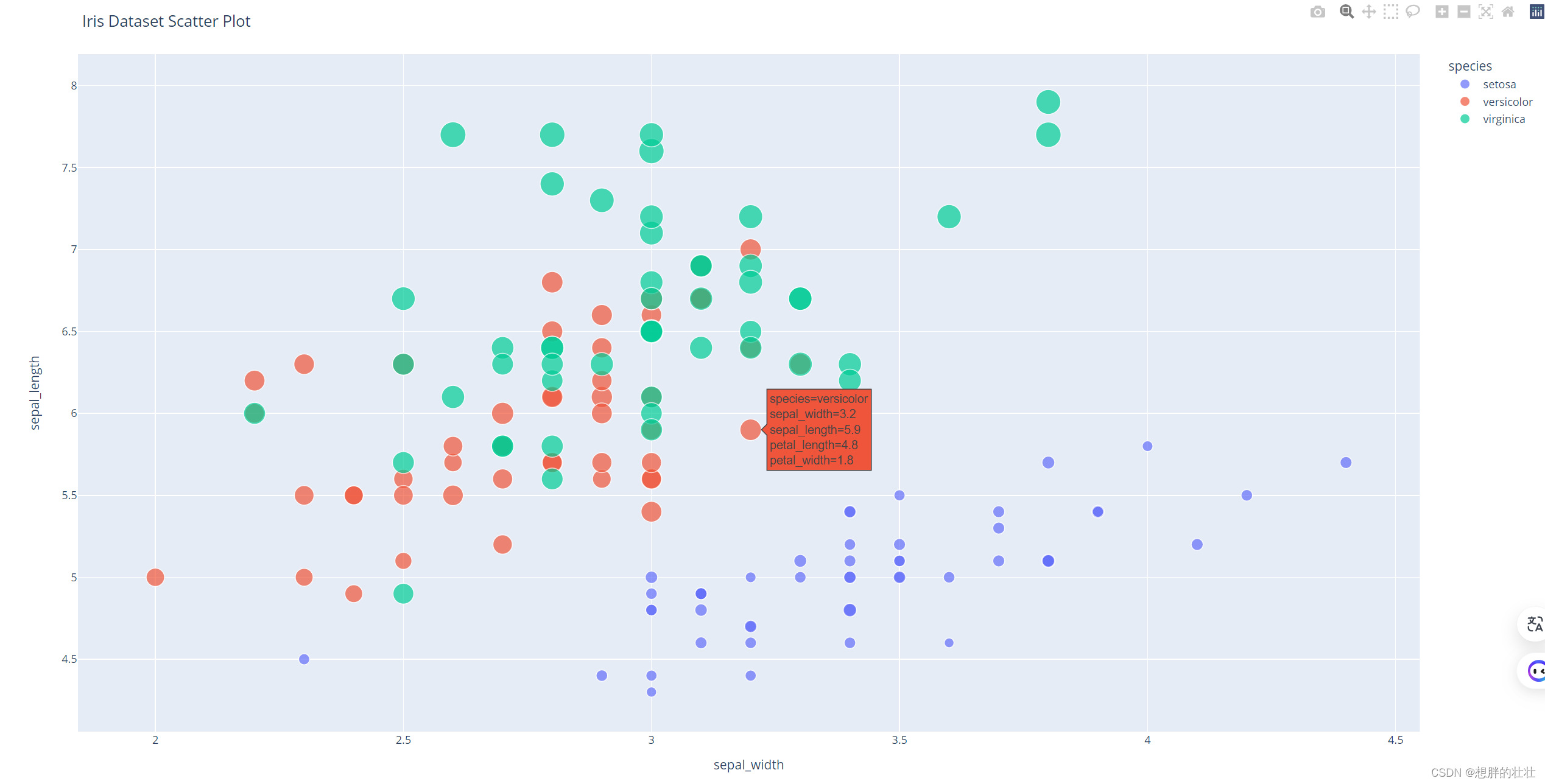
示例:散点图
import plotly.express as px# 数据
df = px.data.iris()# 创建散点图
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species", size="petal_length", hover_data=['petal_width'])
fig.update_layout(title='Iris Dataset Scatter Plot')
fig.show()
运行结果解释
这个示例使用了内置的Iris花卉数据集来创建一个散点图,其中x轴是花萼宽度,y轴是花萼长度。不同的花种用不同的颜色表示,花瓣长度决定了点的大小,悬停时可以看到花瓣宽度的信息。这个图表是交互式的,可以缩放和移动视图。
常见问题及解决方案
-
问题: 图表加载很慢。
- 解决方案: 减少数据点的数量或优化数据处理步骤。
-
问题: 在网页中嵌入Plotly图表。
- 解决方案: 使用Plotly的
plotly.io.to_html()方法生成HTML代码,然后嵌入网页。
- 解决方案: 使用Plotly的
-
问题: 要调整图表的布局和样式。
- 解决方案: 使用
fig.update_layout()方法来自定义图表的各种布局属性。
- 解决方案: 使用
-
问题: 想要保存图表为静态图片。
- 解决方案: 使用
fig.write_image('filename.png')保存图表。
- 解决方案: 使用
-
问题: 如何创建动态更新的图表。
- 解决方案: 使用Plotly Dash框架来创建可交互且动态更新的图表应用。
拓展
- Bokeh: 专为网页设计的交互式图表库,Bokeh可以快速生成互动图表,非常适合用于构建复杂的可视化数据探索接口。
- Altair: 一个声明式的统计可视化库,由Vega和Vega-Lite图表的基础上构建,Altair的API设计旨在创建清晰且可重复的图表。
更多问题咨询
Cos机器人
这篇关于Pandas数据可视化 - Matplotlib、Seaborn、Pandas Plot、Plotly的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







