本文主要是介绍Elasticsearch中对文章进行索引和查重,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
解决思路
要在Elasticsearch中对文章进行索引和查重,可以按照以下步骤操作:
-
安装Elasticsearch并启动服务。
-
安装Python的Elasticsearch客户端库,可以使用
pip install elasticsearch命令进行安装。 -
编写Python代码,使用Elasticsearch客户端库对文章进行索引和查重。
示例代码
from elasticsearch import Elasticsearch# 连接到Elasticsearch服务
es = Elasticsearch(["http://localhost:9200"])# 定义要索引的文章
articles = [{"title": "文章1", "content": "这是文章1的内容"},{"title": "文章2", "content": "这是文章2的内容"},{"title": "文章3", "content": "这是文章3的内容"},
]# 对文章进行索引
for article in articles:es.index(index="articles", doc_type="_doc", body=article)# 查询相似度较高的文章
query = {"query": {"more_like_this": {"fields": ["content"],"like": "这是文章1的内容","min_term_freq": 1,"max_query_terms": 12,}}
}# 执行查询
response = es.search(index="articles", body=query)# 输出查询结果
print("相似度较高的文章:")
for hit in response["hits"]["hits"]:print(hit["_source"]["title"])
这个示例代码首先连接到Elasticsearch服务,然后定义了三篇文章并对它们进行索引。接下来,我们使用more_like_this查询来查找与给定文章内容相似的文章。最后,输出查询结果。
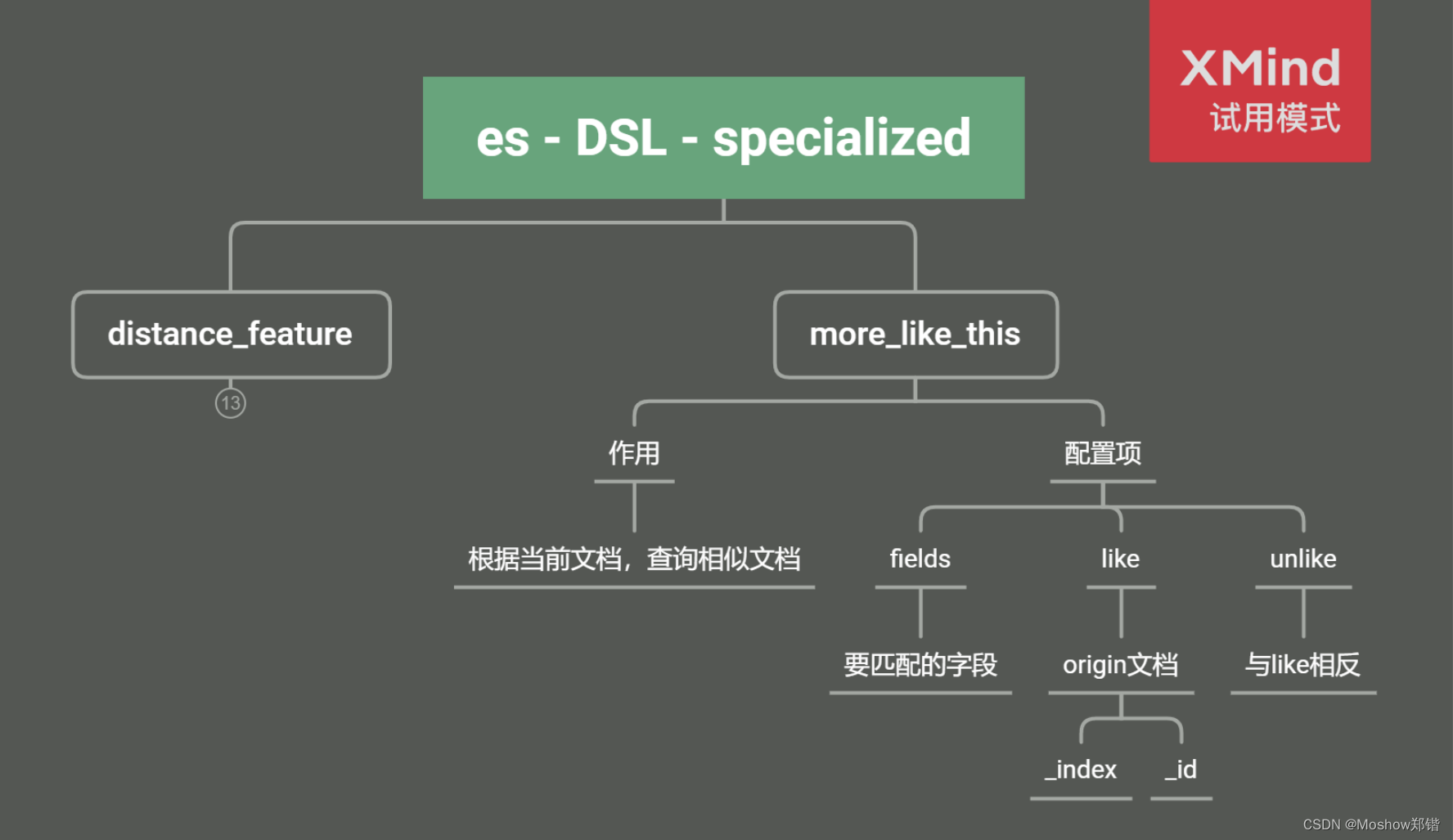
more_like_this查询
在Elasticsearch中,more_like_this查询用于查找与给定文档相似的文档。它基于文档的文本内容,通过计算文档之间的相似度来返回最相似的文档。
以下是more_like_this查询的基本用法:
- 指定要查询的索引和文档类型。
- 使用
query字段定义查询条件,其中包含more_like_this查询。 - 在
more_like_this查询中,需要指定要比较的字段(通常是文本类型的字段),以及要与之比较的文档。 - 可以设置其他参数,如最小词频(
min_term_freq)、最大查询词数(max_query_terms)等,以控制相似度计算的方式。
{"query": {"more_like_this": {"fields": ["title", "content"],"like": "这是一个示例文档","min_term_freq": 1,"max_query_terms": 12}}
}
在这个示例中,我们指定了要查询的索引和文档类型(省略了这些部分,因为它们是通用的)。然后,我们在more_like_this查询中指定了要比较的字段(title和content),以及要与之比较的文档(这是一个示例文档)。我们还设置了最小词频为1,最大查询词数为12。
执行这个查询后,Elasticsearch会返回与给定文档相似的文档列表。
这篇关于Elasticsearch中对文章进行索引和查重的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





