本文主要是介绍解析Redis Key Prefix配置之谜:双冒号“::”的由来与作用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在使用Spring Boot集成Redis进行应用开发时,为了增强缓存键的可读性和管理性,我们常常会在配置文件中设定一个全局的key-prefix。如果你发现存储至Redis的键自动附加了“::”,本文将深入探讨这一现象背后的原因,解析Spring Data Redis是如何基于你的配置自动生成这一格式的。
背景介绍
在Spring Boot应用中,通过application.properties或application.yml配置Redis缓存时,可以设置如下属性来指定所有缓存键的前缀:
spring:cache:type: redisredis:cache:key-prefix: myapp


设置上述配置后,每当应用执行缓存操作时(如@Cacheable注解的方法被调用),实际存储到Redis中的键名会以前缀myapp::开头,紧随其后的才是具体的业务键值。这里的“::”正是引发好奇的地方。
源码透视:双冒号的起源
让我们追溯到Spring Data Redis的内部实现,揭秘双冒号的生成逻辑。核心在于CacheKeyPrefix接口及其默认实现SimpleCacheKeyPrefix。简化的源码逻辑如下:
public class SimpleCacheKeyPrefix implements CacheKeyPrefix {private final String prefix;public SimpleCacheKeyPrefix(String prefix) {this.prefix = prefix;}@Overridepublic String compute(String cacheName) {return this.prefix + "::";}
}
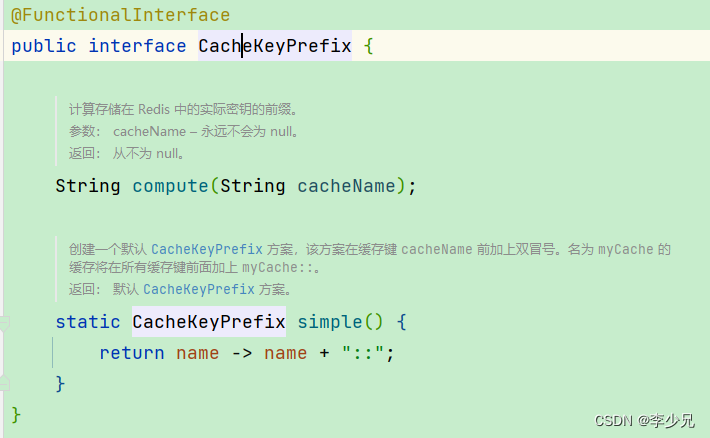
当你在配置文件中设定了key-prefix,如myapp,实际上就是初始化了SimpleCacheKeyPrefix实例,其中compute方法负责生成最终的缓存键前缀。这里,Spring框架巧妙地在用户定义的前缀后添加了双冒号“::”,形成了最终的格式化字符串,比如myapp::。
双冒号的智慧
-
逻辑分隔:“::”作为一个明确的分隔符,清晰地区分了自定义前缀与原始键值,使得键名更具可读性,便于在Redis客户端直接辨认和操作特定前缀下的所有键。
-
冲突规避:即便原始键值中包含了冒号,通过固定格式的双冒号,依然能保证键名的唯一性和解析的准确性,避免了键名解析上的歧义。
-
统一管理:在多模块或大规模应用中,统一的前缀格式便于实施缓存策略,如一键清除某个模块下的所有缓存,提高了缓存维护的便捷性。
应用实践
了解了“::”生成的原理,你就可以更加自信地在自己的应用中运用这一机制。例如,通过调整不同的key-prefix配置,实现不同环境或模块间缓存的隔离,或者利用这一特性进行更精细化的缓存管理和监控。
结语
通过本次解析,我们不仅揭示了Redis缓存键中“::”的由来,也深刻理解了Spring Data Redis在此设计上的考量。这一小小的设计细节,体现了框架设计者对开发者体验和系统可维护性的高度关注。在未来的开发实践中,合理利用这一特性,将助力你的应用构建更加高效、有序的缓存体系。
这篇关于解析Redis Key Prefix配置之谜:双冒号“::”的由来与作用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





