本文主要是介绍pytho爬取南京房源成交价信息并导入到excel,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# encoding: utf-8
# File_name:
import requests
from bs4 import BeautifulSoup
import xlrd #导入xlrd库
import pandas as pd
import openpyxl# 定义函数来获取南京最新的二手房房子成交价
def get_nanjing_latest_second_hand_prices():cookies = {'select_city': '320100','lianjia_ssid': '','02eaefcc-d3ac-468d-a2d5-b1b816bc830f': '','Qs_lvt_200116': '','sajssdk_2015_cross_new_user': '','sensorsdata2015jssdkcross': '','Qs_pv_200116': '',# ... 其他cookie}# 设置请求头,模拟浏览器访问headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Cookie': '; '.join(f'{name}={value}' for name, value in cookies.items()),}price_0_list = list()price_100_list = list()price_200_list = list()price_300_list = list()price_400_list = list()# 假设这是提供南京最新二手房成交价的网页URLfor i in range(1,4):print(f'运行次数:{i}')url = f'https://nj.ke.com/chengjiao/pukouqita11/pg{i}ie2y4ba80ea130l2l3p3p4p5p6/'print('url:'+url)# 发送HTTP请求response = requests.get(url, headers=headers)# 检查请求是否成功if response.status_code == 200:# 使用BeautifulSoup解析HTML内容soup = BeautifulSoup(response.text, 'html.parser')# 根据实际的网页结构,找到包含二手房成交价的容器# 假设成交价的容器是一个带有特定class的元素price_container = soup.find('ul', class_='listContent')li_tags = price_container.find_all('li')print(''+str(i)+'该页多少房源:'+str(len(li_tags)))# 遍历li标签并输出内容for li in li_tags:# 二手房交易初始化house_dict = dict()houseInfo = li.findAll('div', class_='info')for infoDetail in houseInfo:# 小区名称+户型+面积title = infoDetail.find('div', class_='title')a_tag = title.find('a', class_='CLICKDATA maidian-detail')# 提取并输出<a>标签内的文本if a_tag:text_value = a_tag.stringtlist=text_value.split(" ")house_dict['小区名称名称'] = tlist[0]house_dict['户型'] = tlist[1]house_dict['面积'] = tlist[2]print('小区名称:'+tlist[0])print('户型:'+tlist[1])print('面积:'+tlist[2])# address# address = infoDetail.findAll('div', class_='address')# for addressDetail in address:# pass# 朝向,装修风格fangxiang = infoDetail.find('div', class_='houseInfo')house_dict['朝向,装修风格'] = fangxiang.text.strip()print(fangxiang.text.strip())deal_date = infoDetail.find('div', class_='dealDate')house_dict['成交时间'] = deal_date.text.strip()print(deal_date.text.strip())total_price = infoDetail.find('div', class_='totalPrice')if '暂无价格' not in total_price.text:total_number = infoDetail.find('span', class_='number').textprint(f'{total_number}万')house_dict['成交价格'] = total_numberelse:total_number = '0'house_dict['成交价格'] = total_numberprint(total_number)# 楼层louceng = infoDetail.find('div', class_='positionInfo').text.strip()house_dict['楼层'] = loucengprint(louceng)# 单价unit_price = infoDetail.find('div', class_='unitPrice').text.strip()if '暂无单价' not in unit_price:unit_price = infoDetail.findAll('span', class_='number')[1].text.strip()else:unit_price = '0'house_dict['单价'] = unit_priceprint(unit_price)# 房屋满几年deal_house_year = infoDetail.find('span', class_='dealHouseTxt')if deal_house_year is None:deal_house_year = ''else:deal_house_year = deal_house_year.text.strip()house_dict['房屋满几年'] = deal_house_yearprint(deal_house_year)# 挂牌时长deal_cycle_txts = infoDetail.find('span', class_='dealCycleTxt')cycle_txts_find_all = deal_cycle_txts.findAll('span')if(len(cycle_txts_find_all)==2):house_dict['挂牌价'] = cycle_txts_find_all[0].text.strip()print(cycle_txts_find_all[0].text.strip())house_dict['成交周期'] = cycle_txts_find_all[1].text.strip()print(cycle_txts_find_all[1].text.strip())else:house_dict['挂牌价'] = ''for cycle_txts_find_all_span in cycle_txts_find_all:house_dict['成交周期'] = cycle_txts_find_all_span.text.strip()print(cycle_txts_find_all_span.text.strip())try:unit_price_int = float(house_dict['成交价格'])if (unit_price_int == 0):price_0_list.append(house_dict)if (0<unit_price_int <=100 ):price_100_list.append(house_dict)if (100<unit_price_int <=200 ):price_200_list.append(house_dict)if (200<unit_price_int <=300 ):price_300_list.append(house_dict)if (300<unit_price_int <=400 ):price_400_list.append(house_dict)except ValueError:print("转换错误:字符串无法转换为整数")file = 'D:/house/pukou_pukouqita11.xlsx' # 文件路径# 将列表字典转换为DataFramedf = pd.DataFrame(price_0_list)# 将数据写入不同的工作表中# 将每个DataFrame写入到对应名字的工作表with pd.ExcelWriter(file, mode='a', engine='openpyxl') as writer:# 将DataFrame写入新的工作表df.to_excel(writer, sheet_name='无报价')# 将列表字典转换为DataFramedf = pd.DataFrame(price_100_list)# 将数据写入不同的工作表中# 将每个DataFrame写入到对应名字的工作表with pd.ExcelWriter(file, mode='a', engine='openpyxl') as writer:# 将DataFrame写入新的工作表df.to_excel(writer, sheet_name='100w以内')# 将列表字典转换为DataFramedf = pd.DataFrame(price_200_list)# 将数据写入不同的工作表中# 将每个DataFrame写入到对应名字的工作表with pd.ExcelWriter(file, mode='a', engine='openpyxl') as writer:# 将DataFrame写入新的工作表df.to_excel(writer, sheet_name='200w以内')# 将列表字典转换为DataFramedf = pd.DataFrame(price_300_list)# 将数据写入不同的工作表中# 将每个DataFrame写入到对应名字的工作表with pd.ExcelWriter(file, mode='a', engine='openpyxl') as writer:# 将DataFrame写入新的工作表df.to_excel(writer, sheet_name='300w以内')# 将列表字典转换为DataFramedf = pd.DataFrame(price_400_list)# 将数据写入不同的工作表中# 将每个DataFrame写入到对应名字的工作表# 使用ExcelWriter追加模式打开文件with pd.ExcelWriter(file, mode='a', engine='openpyxl') as writer:# 将DataFrame写入新的工作表df.to_excel(writer, sheet_name='400w以内')# 调用函数并打印结果
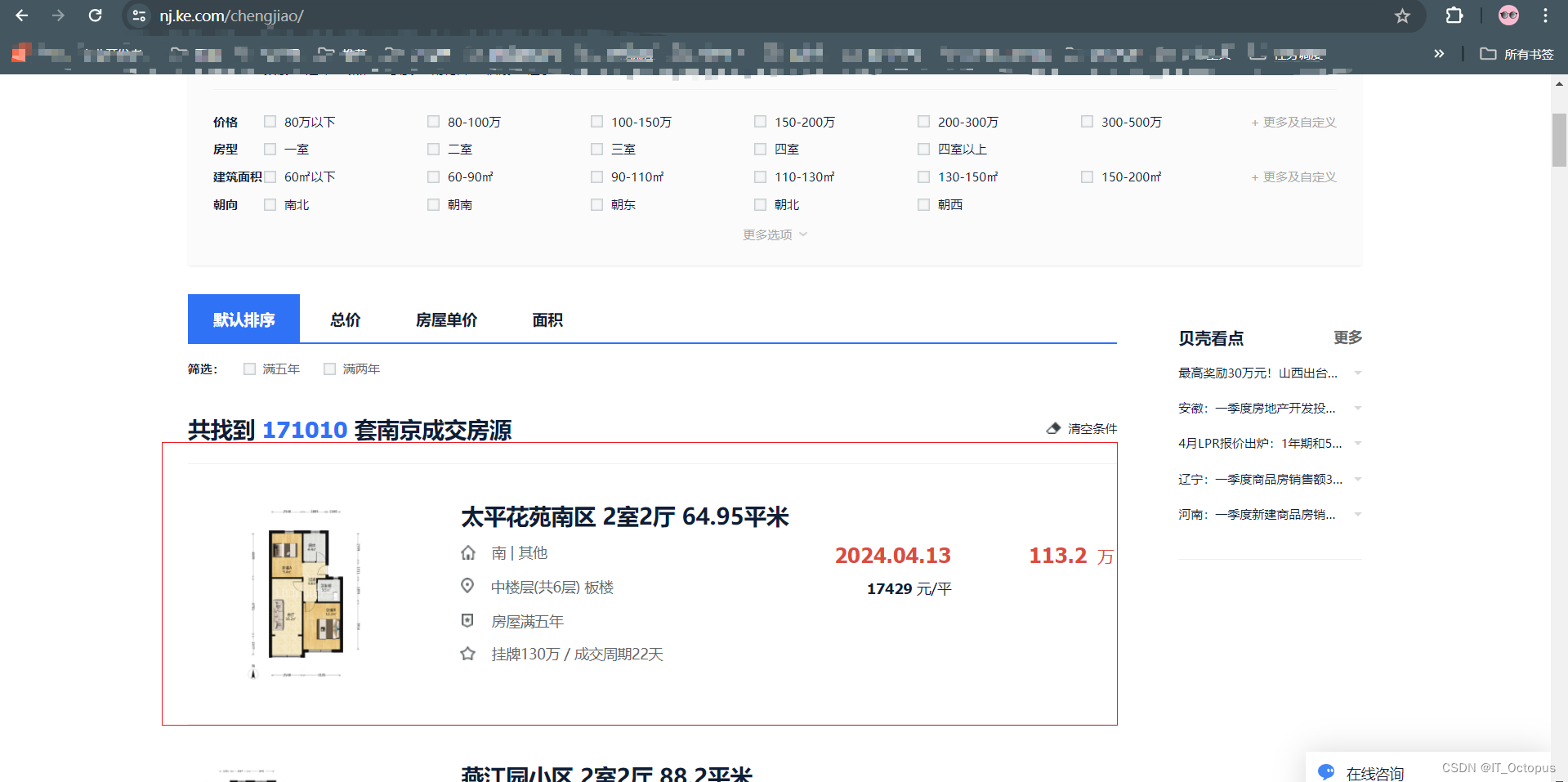
latest_price = get_nanjing_latest_second_hand_prices()初版:仍有很多需要优化的点,但是可以使用了,要注意,贝壳成交价的房源只展示100页,每页只有20个数据,所以大家在爬数据的数据要进行分区筛选,它里面的url 有很多规律(简直是无脑),如果没有发现可以通过私信或者直接评论。
效果图如下
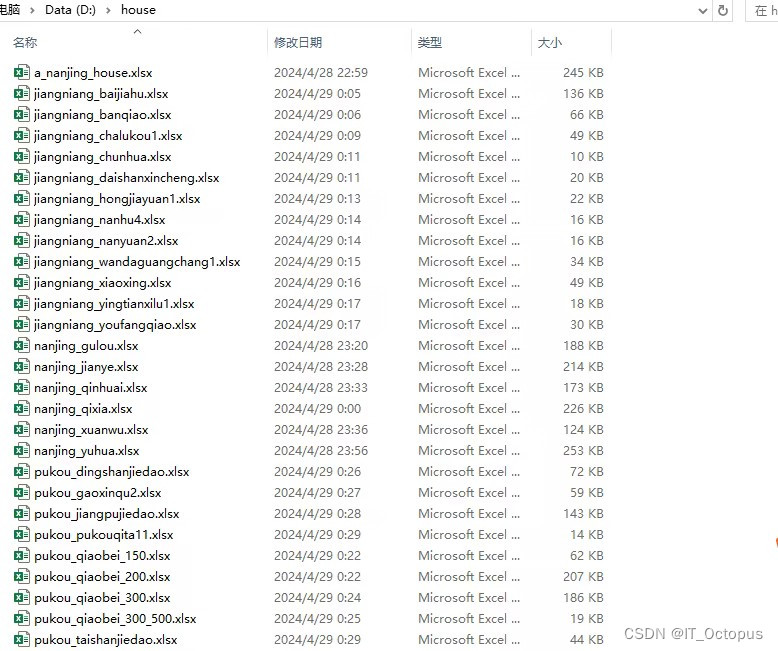
这篇关于pytho爬取南京房源成交价信息并导入到excel的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





