本文主要是介绍echarts特殊处理(滚动条、legend分页、tooltip滚动),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当图表数据量过大时,为了使用者能够有更好的体验,对于大数据量的图表处理:
1、当x轴数据过多不能完全展示时,需要添加滚动条:option设置dataZoom字段

dataZoom: [{ // 这部分是关键,设置滚动条type: 'slider', // 使用 'slider' 类型的 dataZoom 组件start: 0, // 左侧在数据窗口范围的起始百分比, 0 表示从头开始end: 50, // 右侧在数据窗口范围的结束百分比, 100 表示到尾部结束// 滚轮是否触发缩放zoomOnMouseWheel: false,// 鼠标滚轮触发滚动moveOnMouseMove: true,moveOnMouseWheel: true,// 是否显示detail,即拖拽时候显示详细数值信息showDetail: false,
}]
2、数据量过大时会造成legend很多,可能会折叠数据,页面样式也不好看,从而进行legend分页:option设置legend字段

legend: {type: 'scroll', // 设置图例为滚动类型orient: 'horizontal', // 横向显示图例height: 50, // 设置图例高度pageIconColor: '#ff781f', // 设置翻页箭头颜色pageTextStyle: {color: '#999' // 设置翻页数字颜色},pageIconSize: 11, // 设置翻页箭头大小textStyle: { // 设置图例文字的样式color: '#999',fontSize: 12},itemHeight: 10, // 设置图例项的高度itemWidth: 15, // 设置图例项的宽度left: '1%', // 设置图例左边距top: '1%' ,// 设置图例上边距
}
3、数据量过大时,tooltip会很长,可能会占据整个页面,考虑给tooltip添加滚动条:option设置tooltip字段
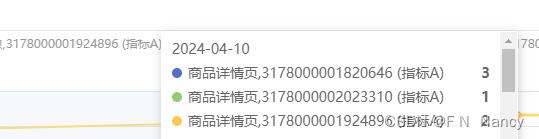
tooltip: {trigger: 'axis',axisPointer:{type:'shadow',},confine:true,enterable:true,extraCssText:"max-width:90%;max-height:83%;overflow:auto;"}
这篇关于echarts特殊处理(滚动条、legend分页、tooltip滚动)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



