本文主要是介绍Druid Task被Overload分配到zk上的流程分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
继前一篇文章关于task被supervisor创建的过程分析,那么task被创建后是怎样分配给zk的呢?task选择middlemanager的策略又是什么?
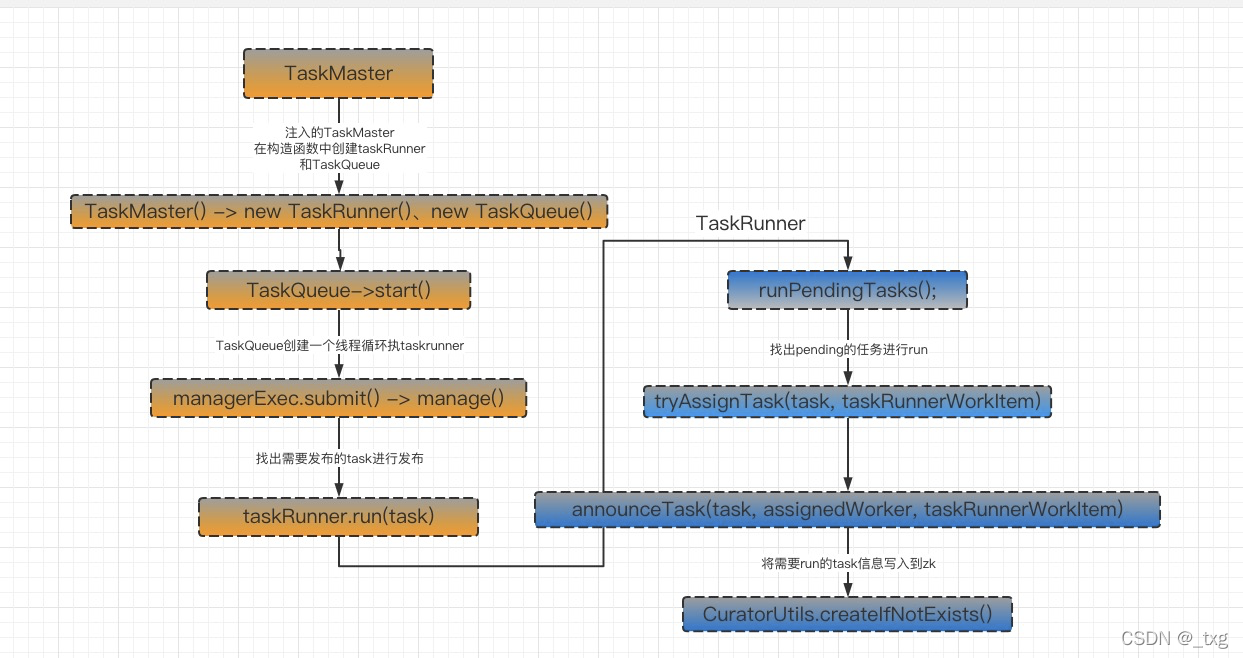
上图
supervisor创建完task后,会将task扔到一个由TaskMaster创建的TaskQueue中。此后的事情就是如果将TaskQueue中的task进行分配运行了。
TaskQueue会启动一个线程一直运行,用来读取taskqueue队列中的tasks,对于已经准备好的task通过TaskRunner进行run()。而TaskRunner是 在TaskMaster中创建的。
TaskRunner中会判断task的状态是否为pending状态,如果是就会对该task进行分配work, 而分配策略默认是根据middlemanager的slot最大空闲数分配的。让后会将work信息、task信息通过jsonMapper进行序列化为byte写到zk的一个能被work识别的路径下面。
上代码
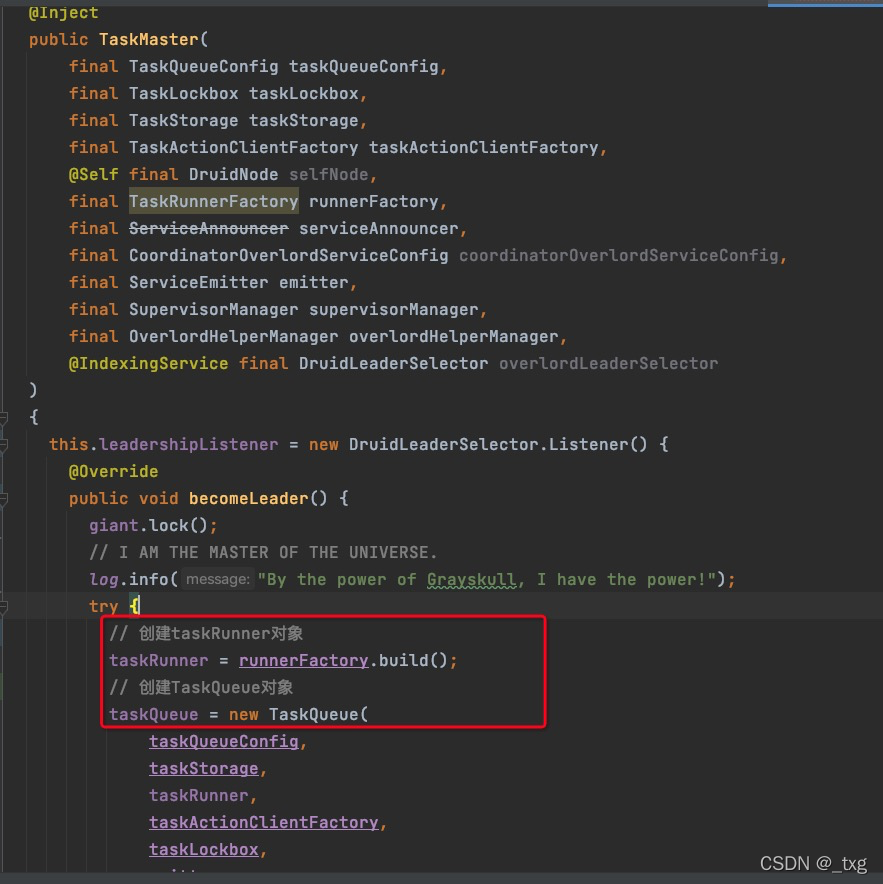
首先从TaskMaster入手,因为TaskMaster是被注入的对象,它管理着TaskQueue和TaskRunner两大对象。
其中TaskRunner是被taskRunnerFactory创建的,而TaskRunner包括:ForkingTaskRunner,RemoteTaskRunner, HttpRemoteTaskRunner 。至于使用哪一个是通过在overload的配置文件中配置的,配置项为:druid.indexer.runner.type=remote/loacl/httpRemote
- local表示从本地运行任务
- remote表示分配到分布式系统中
- httpRemote是在试用期的功能(目前是根据0.16版本分析的),和remote功能一样,只是httpRemote不通过zk而是直接和middlemanager交互
然后此时创建完TaskQueue之后,taskQueue会进行启动并创建一个持续运行的线程。该线程的作用就是不断的轮询判断taskqueue中的task进行处理,调用taskRunner的run()方法做分配task的处理。
/*** Main task runner management loop. Meant to run forever, or, at least until we're stopped.*/private void manage() throws InterruptedException{log.info("Beginning management in %s.", config.getStartDelay());Thread.sleep(config.getStartDelay().getMillis());// Ignore return value- we'll get the IDs and futures from getKnownTasks later.taskRunner.restore();while (active) {giant.lock();try {// Task futures available from the taskRunnerfinal Map<String, ListenableFuture<TaskStatus>> runnerTaskFutures = new HashMap<>();for (final TaskRunnerWorkItem workItem : taskRunner.getKnownTasks()) {runnerTaskFutures.put(workItem.getTaskId(), workItem.getResult());}// Attain futures for all active tasks (assuming they are ready to run).// Copy tasks list, as notifyStatus may modify it.for (final Task task : ImmutableList.copyOf(tasks)) {if (!taskFutures.containsKey(task.getId())) {final ListenableFuture<TaskStatus> runnerTaskFuture;if (runnerTaskFutures.containsKey(task.getId())) {runnerTaskFuture = runnerTaskFutures.get(task.getId());} else {// Task should be running, so run it.final boolean taskIsReady;try {taskIsReady = task.isReady(taskActionClientFactory.create(task));}catch (Exception e) {log.warn(e, "Exception thrown during isReady for task: %s", task.getId());notifyStatus(task, TaskStatus.failure(task.getId()), "failed because of exception[%s]", e.getClass());continue;}if (taskIsReady) {log.info("Asking taskRunner to run: %s", task.getId());// 该部分是已分配给taskrunner管理且没有被运行的runnerTaskFuture = taskRunner.run(task);} else {continue;}}taskFutures.put(task.getId(), attachCallbacks(task, runnerTaskFuture));} else if (isTaskPending(task)) {// if the taskFutures contain this task and this task is pending, also let the taskRunner// to run it to guarantee it will be assigned to run// see https://github.com/apache/incubator-druid/pull/6991// 判断task是否处于pending状态,如果是就进行分配运行taskRunner.run(task);}}// Kill tasks that shouldn't be runningfinal Set<String> tasksToKill = Sets.difference(runnerTaskFutures.keySet(),ImmutableSet.copyOf(Lists.transform(tasks,new Function<Task, Object>(){@Overridepublic String apply(Task task){return task.getId();}})));if (!tasksToKill.isEmpty()) {log.info("Asking taskRunner to clean up %,d tasks.", tasksToKill.size());for (final String taskId : tasksToKill) {try {taskRunner.shutdown(taskId,"task is not in runnerTaskFutures[%s]",runnerTaskFutures.keySet());}catch (Exception e) {log.warn(e, "TaskRunner failed to clean up task: %s", taskId);}}}// awaitNanos because management may become necessary without this condition signalling,// due to e.g. tasks becoming ready when other folks mess with the TaskLockbox.managementMayBeNecessary.awaitNanos(MANAGEMENT_WAIT_TIMEOUT_NANOS);}finally {giant.unlock();}}}此时决定运行的task时候,让taskRunnner根据策略去寻找work进行分配。判断出处于pending状态的task进行分配。
/*** This method uses a multi-threaded executor to extract all pending tasks and attempt to run them. Any tasks that* are successfully assigned to a worker will be moved from pendingTasks to runningTasks. This method is thread-safe.* This method should be run each time there is new worker capacity or if new tasks are assigned.*/private void runPendingTasks(){runPendingTasksExec.submit(new Callable<Void>(){@Overridepublic Void call(){try {// make a copy of the pending tasks because tryAssignTask may delete tasks from pending and move them// into running statusList<RemoteTaskRunnerWorkItem> copy = Lists.newArrayList(pendingTasks.values());sortByInsertionTime(copy);for (RemoteTaskRunnerWorkItem taskRunnerWorkItem : copy) {String taskId = taskRunnerWorkItem.getTaskId();if (tryAssignTasks.putIfAbsent(taskId, taskId) == null) {try {//this can still be null due to race from explicit task shutdown request//or if another thread steals and completes this task right after this thread makes copy//of pending tasks. See https://github.com/apache/incubator-druid/issues/2842 .Task task = pendingTaskPayloads.get(taskId);// 试图去分配taskif (task != null && tryAssignTask(task, taskRunnerWorkItem)) {pendingTaskPayloads.remove(taskId);}}catch (Exception e) {log.makeAlert(e, "Exception while trying to assign task").addData("taskId", taskRunnerWorkItem.getTaskId()).emit();RemoteTaskRunnerWorkItem workItem = pendingTasks.remove(taskId);if (workItem != null) {taskComplete(workItem, null, TaskStatus.failure(taskId));}}finally {tryAssignTasks.remove(taskId);}}}}catch (Exception e) {log.makeAlert(e, "Exception in running pending tasks").emit();}return null;}});}根据策略以及过滤条件得到task要分配的work的信息:
/*** Ensures no workers are already running a task before assigning the task to a worker.* It is possible that a worker is running a task that the RTR has no knowledge of. This occurs when the RTR* needs to bootstrap after a restart.** @param taskRunnerWorkItem - the task to assign** @return true iff the task is now assigned*/private boolean tryAssignTask(final Task task, final RemoteTaskRunnerWorkItem taskRunnerWorkItem) throws Exception{Preconditions.checkNotNull(task, "task");Preconditions.checkNotNull(taskRunnerWorkItem, "taskRunnerWorkItem");Preconditions.checkArgument(task.getId().equals(taskRunnerWorkItem.getTaskId()), "task id != workItem id");if (runningTasks.containsKey(task.getId()) || findWorkerRunningTask(task.getId()) != null) {log.info("Task[%s] already running.", task.getId());return true;} else {// Nothing running this task, announce it in ZK for a worker to run itWorkerBehaviorConfig workerConfig = workerConfigRef.get();// 确定分配的策略WorkerSelectStrategy strategy;if (workerConfig == null || workerConfig.getSelectStrategy() == null) {strategy = WorkerBehaviorConfig.DEFAULT_STRATEGY;log.debug("No worker selection strategy set. Using default of [%s]", strategy.getClass().getSimpleName());} else {strategy = workerConfig.getSelectStrategy();}ZkWorker assignedWorker = null;final ImmutableWorkerInfo immutableZkWorker;try {synchronized (workersWithUnacknowledgedTask) {immutableZkWorker = strategy.findWorkerForTask(config,ImmutableMap.copyOf(Maps.transformEntries(Maps.filterEntries(zkWorkers,new Predicate<Map.Entry<String, ZkWorker>>(){@Overridepublic boolean apply(Map.Entry<String, ZkWorker> input){return !lazyWorkers.containsKey(input.getKey()) &&!workersWithUnacknowledgedTask.containsKey(input.getKey()) &&!blackListedWorkers.contains(input.getValue());}}),(String key, ZkWorker value) -> value.toImmutable())),task);if (immutableZkWorker != null &&workersWithUnacknowledgedTask.putIfAbsent(immutableZkWorker.getWorker().getHost(), task.getId())== null) {assignedWorker = zkWorkers.get(immutableZkWorker.getWorker().getHost());}}if (assignedWorker != null) {// 得到work信息后进行发布到zk上return announceTask(task, assignedWorker, taskRunnerWorkItem);} else {log.debug("Unsuccessful task-assign attempt for task [%s] on workers [%s]. Workers to ack tasks are [%s].",task.getId(),zkWorkers.values(),workersWithUnacknowledgedTask);}return false;}finally {if (assignedWorker != null) {workersWithUnacknowledgedTask.remove(assignedWorker.getWorker().getHost());//if this attempt won the race to run the task then other task might be able to use this worker now after task ack.runPendingTasks();}}}}根据task信息和work信息写入zk的相应路径下面:
/*** Creates a ZK entry under a specific path associated with a worker. The worker is responsible for* removing the task ZK entry and creating a task status ZK entry.** @param theZkWorker The worker the task is assigned to* @param taskRunnerWorkItem The task to be assigned** @return boolean indicating whether the task was successfully assigned or not*/private boolean announceTask(final Task task,final ZkWorker theZkWorker,final RemoteTaskRunnerWorkItem taskRunnerWorkItem) throws Exception{Preconditions.checkArgument(task.getId().equals(taskRunnerWorkItem.getTaskId()), "task id != workItem id");final String worker = theZkWorker.getWorker().getHost();synchronized (statusLock) {if (!zkWorkers.containsKey(worker) || lazyWorkers.containsKey(worker)) {// the worker might have been killed or marked as lazylog.info("Not assigning task to already removed worker[%s]", worker);return false;}log.info("Coordinator asking Worker[%s] to add task[%s]", worker, task.getId());// 将task的信息写到相应的的zk路径下面CuratorUtils.createIfNotExists(cf,JOINER.join(indexerZkConfig.getTasksPath(), worker, task.getId()),CreateMode.EPHEMERAL,jsonMapper.writeValueAsBytes(task),config.getMaxZnodeBytes());// ....}END
至此,要运行的task得到分配的work写到zk路径的核心代码以及过程就如上文所述。为了保证task能够准确无误的运行起来会很多细节性的逻辑判断,状态存储。
这篇关于Druid Task被Overload分配到zk上的流程分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




