本文主要是介绍达梦DM8 数据复制系统搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、达梦数据复制简介
达梦数据复制(DATA REPLICATION)是一个分担系统访问压力、加快异地访问响应速度、提高数据可靠性的解决方案。将一个服务器实例上的数据变更复制到另外的服务器实例。可以用于解决大、中型应用中出现的因来自不同地域、不同部门、不同类型的数据访问请求导致数据库服务器超负荷运行、网络阻塞、远程用户的数据响应迟缓的问题。
数据复制系统由以下部件构成:
1.复制服务器;
2.复制节点;
3.各实例站点间通讯的 MAL 系统。
除了系统管理员通过复制服务器定义复制和处理异常外,其他部分的处理及主从服务器之间复制操作对于用户是透明的。整个复制环境的配置境况如下图所示。

DM 复制系统架构图
在整个环境中有且仅有一台复制服务器(RPS),用户通过 RPS定义复制及复制环境,但RPS并不参与到复制过程中。
DM中,将复制逻辑日志按照配置归档到本站点指定目录称为本地归档,将日志的发送称为日志的远程归档。
二、DM数据复制系统搭建
1、实验环境:
虚拟机软件:VirtualBox 6.1
数据库:DM8 64位,安装包名称为dm8_setup_rh7_64_ent_8.1.1.88.iso
主机操作系统:CentOS Linux release 7.2.1511 (Core),64位
2、资源规划
配置一个复制服务器、一个主服务器、一个从服务器,相关的IP、端口等规划见下表。
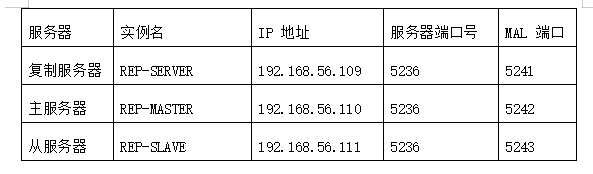
3、配置 dm.ini
复制服务器
INSTANCE_NAME = REP-SERVER
PORT_NUM = 5236
MAL_INI = 1
主服务器
INSTANCE_NAME = REP-MASTER
PORT_NUM = 5236
MAL_INI = 1
从服务器
INSTANCE_NAME = REP-SLAVE
PORT_NUM = 5236
MAL_INI = 1
4、配置dmmal.ini
MAL_CHECK_INTERVAL = 5
MAL_CONN_FAIL_INTERVAL = 5
[MAL_INST1]
MAL_INST_NAME = REP-SERVER
MAL_HOST = 10.0.3.109
MAL_PORT = 5241
MAL_INST_PORT = 5236
MAL_INST_HOST = 192.168.56.109[MAL_INST2]
MAL_INST_NAME = REP-MASTER
MAL_HOST = 10.0.3.110
MAL_PORT = 5242
MAL_INST_PORT = 5236
MAL_INST_HOST = 192.168.56.110[MAL_INST3]
MAL_INST_NAME = REP-SLAVE
MAL_HOST = 10.0.3.111
MAL_PORT = 5243
MAL_INST_PORT = 5236
MAL_INST_HOST = 192.168.56.111
5、复制服务器初始化
如果是第一次使用复制服务器,需要对复制服务器执行初始化操作。通过执行系统函数SP_INIT_REP_SYS(create_flag)来初始化复制服务器。其主要作用是创建复制用户(SYSREP/SYSREP)和创建复制服务器上需要的系统表。SP_INIT_REP_SYS 的参数 create_flag 为 1 时表示创建用户和系统表,为 0 时表示删除用户和系统表。
6、环境的配置
SP_INIT_REP_SYS(1);
SP_RPS_ADD_GROUP('MASTER_TO_SLAVE', '主从同步复制');
SP_RPS_SET_BEGIN('MASTER_TO_SLAVE');
SP_RPS_ADD_REPLICATION ('MASTER_TO_SLAVE', 'REPM2S', 'M 到 S 的同步复制', 'REP-MASTER', 'REP-SLAVE', NULL, '/dm8/data/DAMENG/arch');
SP_RPS_ADD_SCH_MAP('REPM2S', 'SYSDBA', 'SYSDBA', 0);
在这个步骤中出现了一个问题:由于防火墙没有关闭,执行SP_RPS_ADD_REPLICATION这个过程时,一直提示/dm8/data/DAMENG/arch目录无效,如下:
SQL> SP_RPS_ADD_REPLICATION ('MASTER_TO_SLAVE', 'REPM2S', 'M 到 S 的同步复制', 'REP-MASTER', 'REP-SLAVE', NULL, '/dm8/data/DAMENG/arch');
SP_RPS_ADD_REPLICATION ('MASTER_TO_SLAVE', 'REPM2S', 'M 到 S 的同步复制', 'REP-MASTER', 'REP-SLAVE', NULL, '/dm8/arch');
[-2401]:Database file path [/dm8/data/DAMENG/arch] is invalid.
used time: 1.123(ms). Execute id is 0.
多次更换目录和调整目录权限后依然存在这个问题,最后将防火墙关闭后这个错误才解决。
7、系统功能简单测试
在主服务器REP-MASTER实例中创建测试表并插入数据:
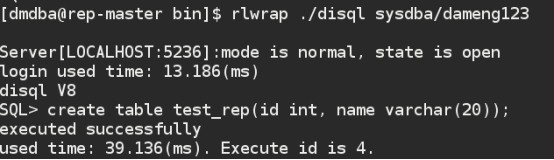
主服务器实例中测试表中数据如下:

登录从服务器查看数据是否已经复制过来:

这篇关于达梦DM8 数据复制系统搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









