本文主要是介绍上市公司-企业勒纳指数、行业勒纳指数、相对勒纳指数代码及数据集(2000-2022年),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、数据简介
勒纳指数也称为勒纳垄断势力指数,它通过对价格与边际成本偏离程度的度量,反映市场中垄断力量的强弱。
企业勒纳指数是衡量企业在市场中的垄断力量强弱的重要指标。
行业勒纳指数是衡量整个行业垄断程度的重要指标。
相对勒纳指数是针对不同企业或不同行业之间的勒纳指数进行比较分析的一种指标。
企业、行业勒纳指数的计算公式为L= (P- MC) / P。(其中,L表示勒纳指数,P表示价格,MC表示边际成本。这个公式反映了产品价格与边际成本的偏离程度,从而度量市场中垄断力量的强弱。勒纳指数在0到1之间变动,数值越大,表明垄断势力越大。)
相对勒纳指数 = 目标企业或行业的勒纳指数 / 基准企业或行业的勒纳指数
本数据包含原始数据、代码、参考文献,最终结果。
数据名称:上市公司-企业勒纳指数、行业勒纳指数、相对勒纳指数
数据年份:2000-2022年
02、相关数据
证券代码、年份、股票代码、股票简称、企业勒纳指数、行业勒纳指数、相对勒纳指数、沪深A股为1,否则为0、北京A股为1,否则为0、行业名称C、行业代码C、制造业取两位代码,其他行业用大类、营业收入、营业成本、销售费用、管理费用。
03、数据截图
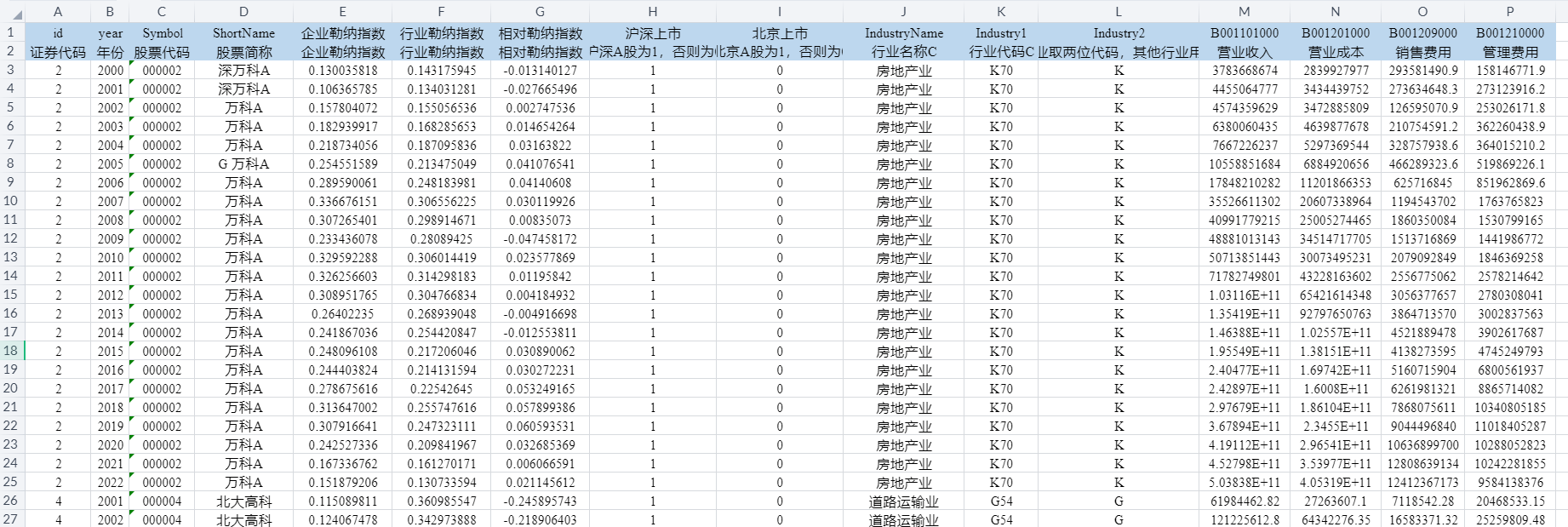
| id | year | Symbol | ShortName | 企业勒纳指数 | 行业勒纳指数 | 相对勒纳指数 | 沪深上市 | 北京上市 | IndustryName | Industry1 | Industry2 | B001101000 | B001201000 | B001209000 | B001210000 |
| 证券代码 | 年份 | 股票代码 | 股票简称 | 企业勒纳指数 | 行业勒纳指数 | 相对勒纳指数 | 沪深A股为1,否则为0 | 北京A股为1,否则为0 | 行业名称C | 行业代码C | 制造业取两位代码,其他行业用大类 | 营业收入 | 营业成本 | 销售费用 | 管理费用 |
| 2 | 2000 | 000002 | 深万科A | 0.130035818 | 0.143175945 | -0.013140127 | 1 | 0 | 房地产业 | K70 | K | 3783668674 | 2839927977 | 293581490.9 | 158146771.9 |
| 2 | 2001 | 000002 | 深万科A | 0.106365785 | 0.134031281 | -0.027665496 | 1 | 0 | 房地产业 | K70 | K | 4455064777 | 3434439752 | 273634648.3 | 273123916.2 |
| 2 | 2002 | 000002 | 万科A | 0.157804072 | 0.155056536 | 0.002747536 | 1 | 0 | 房地产业 | K70 | K | 4574359629 | 3472885809 | 126595070.9 | 253026171.8 |
| 2 | 2003 | 000002 | 万科A | 0.182939917 | 0.168285653 | 0.014654264 | 1 | 0 | 房地产业 | K70 | K | 6380060435 | 4639877678 | 210754591.2 | 362260438.9 |
| 2 | 2004 | 000002 | 万科A | 0.218734056 | 0.187095836 | 0.03163822 | 1 | 0 | 房地产业 | K70 | K | 7667226237 | 5297369544 | 328757938.6 | 364015210.2 |
| 2 | 2005 | 000002 | G 万科A | 0.254551589 | 0.213475049 | 0.041076541 | 1 | 0 | 房地产业 | K70 | K | 10558851684 | 6884920656 | 466289323.6 | 519869226.1 |
| 2 | 2006 | 000002 | 万科A | 0.289590061 | 0.248183981 | 0.04140608 | 1 | 0 | 房地产业 | K70 | K | 17848210282 | 11201866353 | 625716845 | 851962869.6 |
| 2 | 2007 | 000002 | 万科A | 0.336676151 | 0.306556225 | 0.030119926 | 1 | 0 | 房地产业 | K70 | K | 35526611302 | 20607338964 | 1194543702 | 1763765823 |
| 2 | 2008 | 000002 | 万科A | 0.307265401 | 0.298914671 | 0.00835073 | 1 | 0 | 房地产业 | K70 | K | 40991779215 | 25005274465 | 1860350084 | 1530799165 |
| 2 | 2009 | 000002 | 万科A | 0.233436078 | 0.28089425 | -0.047458172 | 1 | 0 | 房地产业 | K70 | K | 48881013143 | 34514717705 | 1513716869 | 1441986772 |
| 2 | 2010 | 000002 | 万科A | 0.329592288 | 0.306014419 | 0.023577869 | 1 | 0 | 房地产业 | K70 | K | 50713851443 | 30073495231 | 2079092849 | 1846369258 |
| 2 | 2011 | 000002 | 万科A | 0.326256603 | 0.314298183 | 0.01195842 | 1 | 0 | 房地产业 | K70 | K | 71782749801 | 43228163602 | 2556775062 | 2578214642 |
| 2 | 2012 | 000002 | 万科A | 0.308951765 | 0.304766834 | 0.004184932 | 1 | 0 | 房地产业 | K70 | K | 1.03116E+11 | 65421614348 | 3056377657 | 2780308041 |
| 2 | 2013 | 000002 | 万科A | 0.26402235 | 0.268939048 | -0.004916698 | 1 | 0 | 房地产业 | K70 | K | 1.35419E+11 | 92797650763 | 3864713570 | 3002837563 |
| 2 | 2014 | 000002 | 万科A | 0.241867036 | 0.254420847 | -0.012553811 | 1 | 0 | 房地产业 | K70 | K | 1.46388E+11 | 1.02557E+11 | 4521889478 | 3902617687 |
| 2 | 2015 | 000002 | 万科A | 0.248096108 | 0.217206046 | 0.030890062 | 1 | 0 | 房地产业 | K70 | K | 1.95549E+11 | 1.38151E+11 | 4138273595 | 4745249793 |
| 2 | 2016 | 000002 | 万科A | 0.244403824 | 0.214131594 | 0.030272231 | 1 | 0 | 房地产业 | K70 | K | 2.40477E+11 | 1.69742E+11 | 5160715904 | 6800561937 |
| 2 | 2017 | 000002 | 万科A | 0.278675616 | 0.22542645 | 0.053249165 | 1 | 0 | 房地产业 | K70 | K | 2.42897E+11 | 1.6008E+11 | 6261981321 | 8865714082 |
| 2 | 2018 | 000002 | 万科A | 0.313647002 | 0.255747616 | 0.057899386 | 1 | 0 | 房地产业 | K70 | K | 2.97679E+11 | 1.86104E+11 | 7868075611 | 10340805185 |
| 2 | 2019 | 000002 | 万科A | 0.307916641 | 0.247323111 | 0.060593531 | 1 | 0 | 房地产业 | K70 | K | 3.67894E+11 | 2.3455E+11 | 9044496840 | 11018405287 |
| 2 | 2020 | 000002 | 万科A | 0.242527336 | 0.209841967 | 0.032685369 | 1 | 0 | 房地产业 | K70 | K | 4.19112E+11 | 2.96541E+11 | 10636899700 | 10288052823 |
| 2 | 2021 | 000002 | 万科A | 0.167336762 | 0.161270171 | 0.006066591 | 1 | 0 | 房地产业 | K70 | K | 4.52798E+11 | 3.53977E+11 | 12808639134 | 10242281855 |
| 2 | 2022 | 000002 | 万科A | 0.151879206 | 0.130733594 | 0.021145612 | 1 | 0 | 房地产业 | K70 | K | 5.03838E+11 | 4.05319E+11 | 12412367173 | 9584138376 |
04、包含内容

05、全部数据下载链接:https://download.csdn.net/download/li514006030/89238840
这篇关于上市公司-企业勒纳指数、行业勒纳指数、相对勒纳指数代码及数据集(2000-2022年)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





