本文主要是介绍使用Canal实现MySQL主从同步,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:本文介绍如何使用Canal实现MySQL主从同步的效果,关于Canal入门使用参考:Canal入门使用
启动Canal
首先,设置Canal服务器里,目标节点(即监测的MySQL节点)的配置,启动Canal服务;
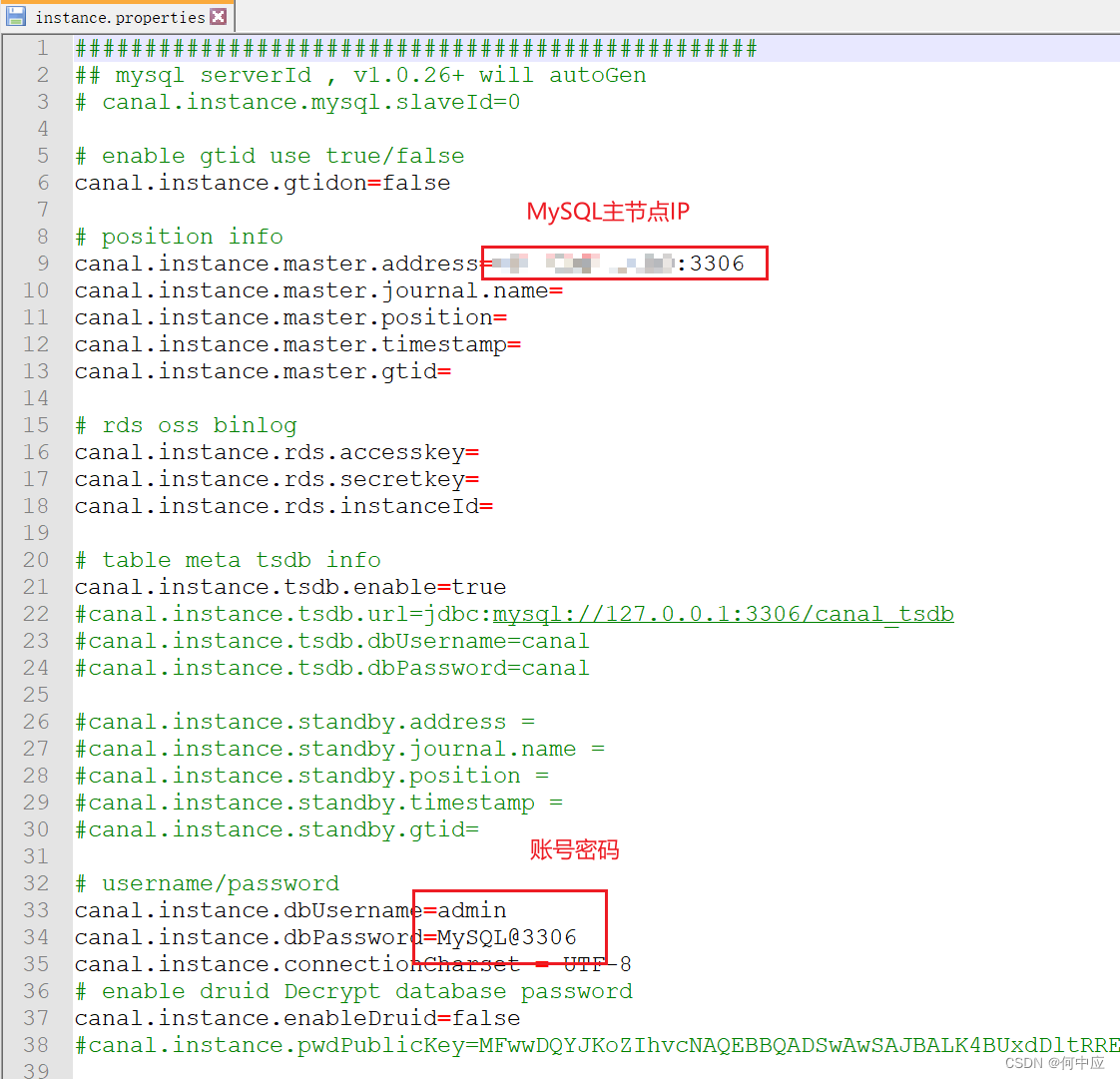
启动Canal服务器,Windows操作系统下,直接双击startup.bat文件即可;
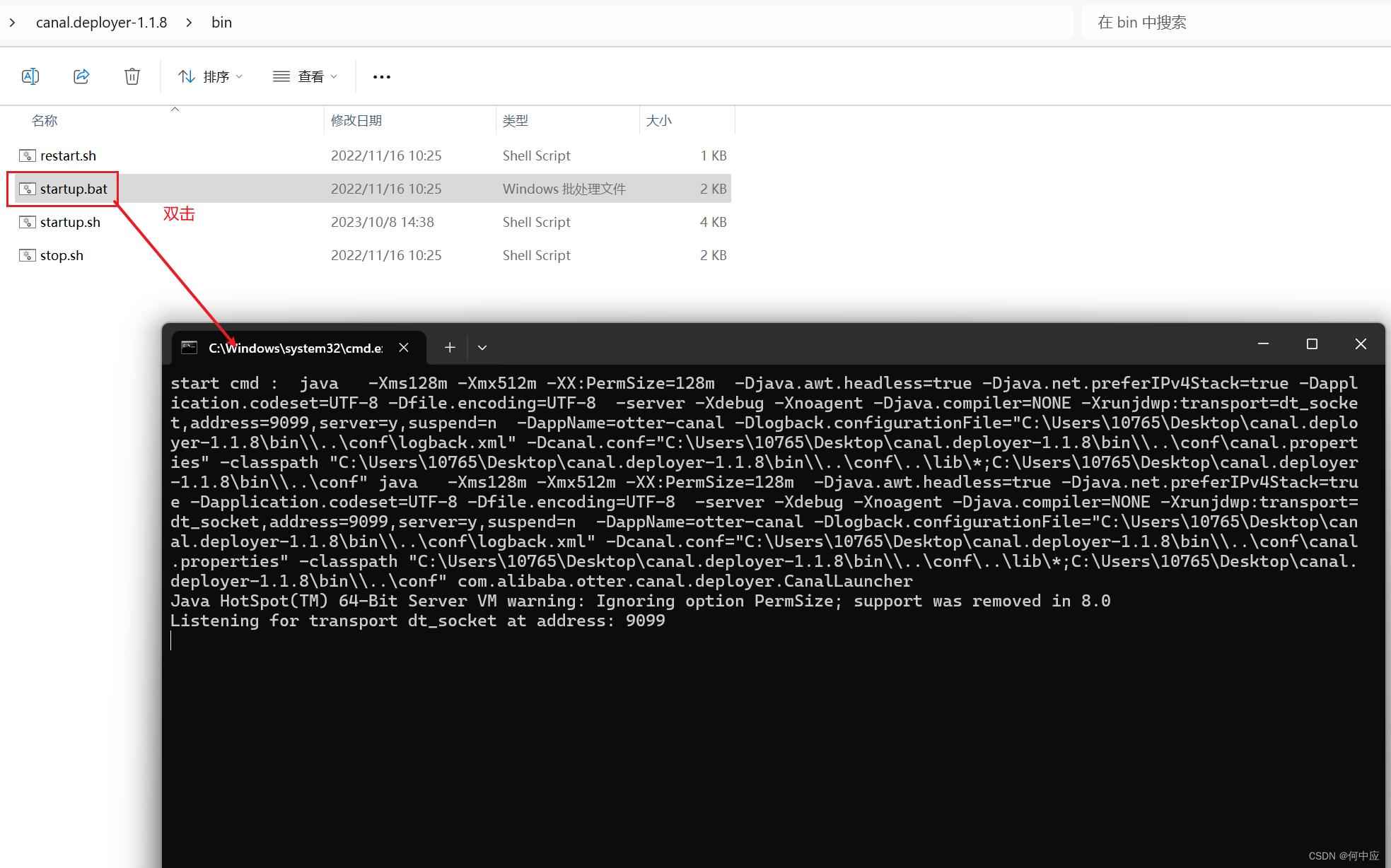
具体操作参考:Canal入门使用
创建项目
创建一个Spring Boot项目,pom.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.12</version><relativePath/></parent><groupId>com.hezy</groupId><artifactId>canal_demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!--druid--><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version></dependency><!--mybatis--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependency><!--mysql驱动--><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><!--canal客户端--><dependency><groupId>top.javatool</groupId><artifactId>canal-spring-boot-starter</artifactId><version>1.2.1-RELEASE</version></dependency></dependencies></project>
application.yml文件如下,这里的数据库配置写从节点的,且账户应该有数据读写权限;
server:port: 8080# 1.数据源的配置
spring:# 数据库配置datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://从节点MySQLIP:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=falseusername: rootpassword: 123456# 2.mybatis配置
mybatis:configuration:# 显示SQL日志配置log-impl: org.apache.ibatis.logging.stdout.StdOutImpl# 驼峰命名配置map-underscore-to-camel-case: true# 3.canal配置
canal:# canal服务端的ipserver: 127.0.0.1:11111destination: example
实体类对象
import lombok.Data;import java.io.Serializable;@Data
public class User implements Serializable {private String id;private String username;private String password;
}
canal处理类
import com.hezy.mapper.UserMapper;
import com.hezy.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;@Component
@CanalTable("i_user")
public class UserHandler implements EntryHandler<User> {@Autowiredprivate UserMapper userMapper;@Overridepublic void insert(User user) {System.out.println("新增用户:" + user);userMapper.insertUser(user);}@Overridepublic void update(User before, User after) {System.out.println("更新用户:" + before + " -> " + after);userMapper.updateUserById(after);}@Overridepublic void delete(User user) {System.out.println("删除用户:" + user);userMapper.deleteUserById(user.getId());}
}
对应写三个针对User表(User实体类对应的表,即i_user表)操作的Mapper方法;
import com.hezy.pojo.User;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Update;@Mapper
public interface UserMapper {@Insert("insert into i_user values (#{id}, #{username}, #{password})")void insertUser(User uesr);@Delete("delete from i_user where id = #{id}")void deleteUserById(String id);@Update("update i_user set username=#{username}, password=#{password} where id=#{id}")void updateUserById(User user);}
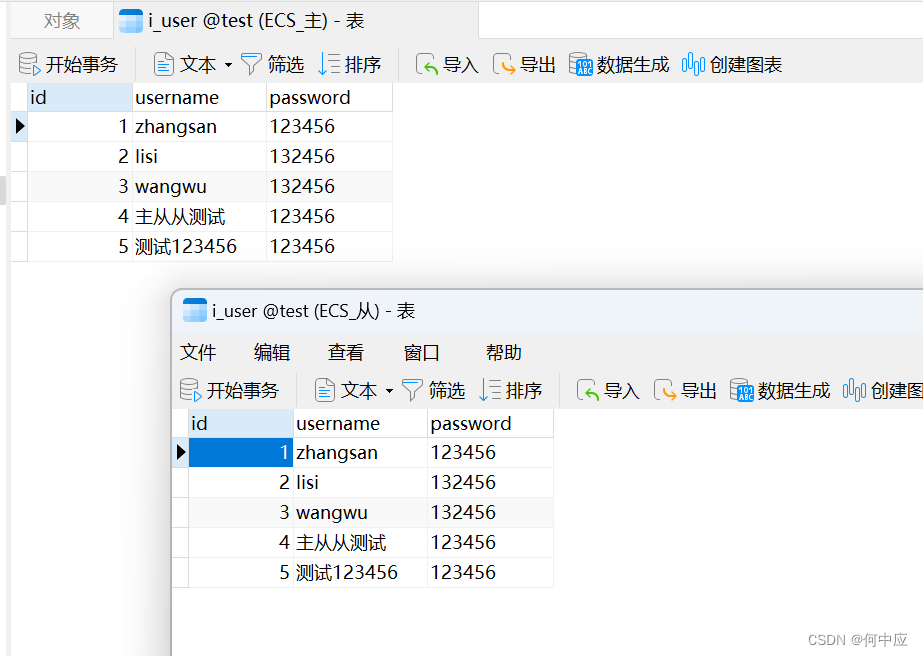
启动程序前,看下两个数据库的表内容,目前是一致的,即使不一致,在你想要进行同步前,也应该手动导出/导入数据,使其初始状态数据保持一致。
启动程序,数据库开始同步,查看控制台,在实时打印检测的信息;
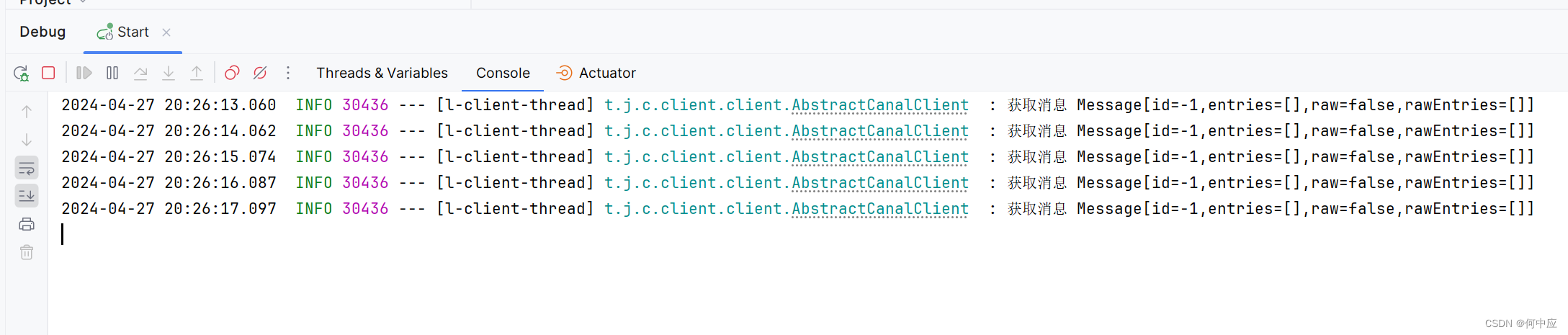
此时,在主节点i_user表内修改一条数据,查看控制台,从数据库内容;
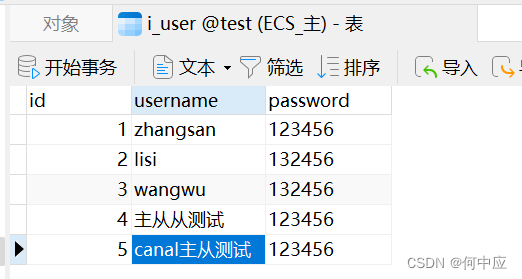
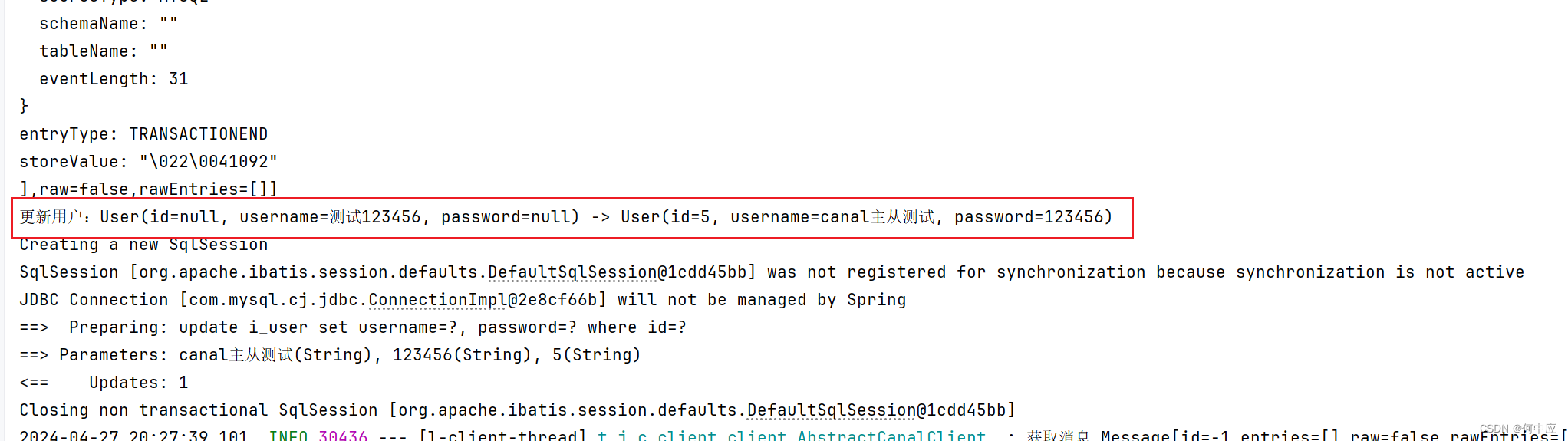
可以看到这次操作被canal监测到了,并通过代码更新到了从库,即代码中配置的数据库;
查看从库i_user表内容,从库数据成功同步;
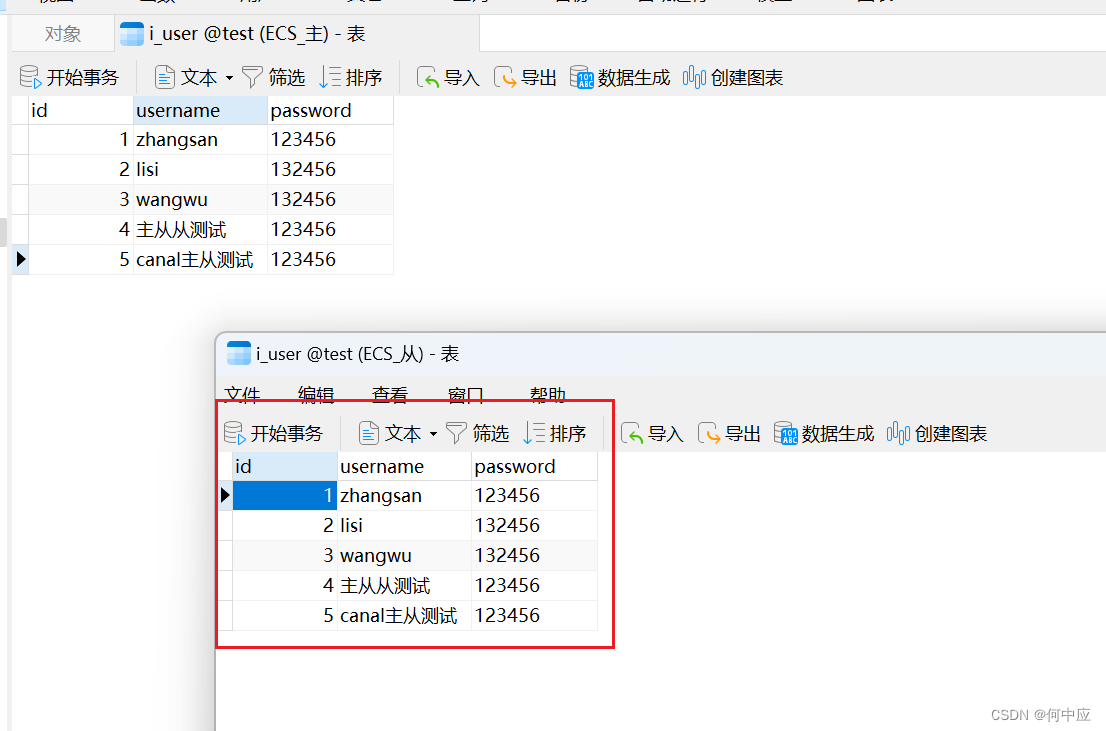
到这里,使用Canal实现MySQL主从同步已完成;
另外
另外,我有个想法,能不能把这个项目package,打成一个jar包,当遇到短期的数据库同步场景时,直接运行这个jar包就可以了。
比如日常开发时,我们想让自己的本地库与测试环境的库保持同步,直接去修改测试库配置,搭建主从可能比较麻烦,就可以用这种方式。甚至可以写个bat脚本,配个环境变量,直接敲CMD命令就能实现两个数据库之间的同步了,非常方便。
总结
本文介绍了如何使用Canal实现MySQL主从同步,参考B站视频:
- Canal极简入门:一小时让你快速上手Canal数据同步神技~
这篇关于使用Canal实现MySQL主从同步的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






