本文主要是介绍推荐 :盘点9个适用所有学科的R数据可视化包(附链接),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Asha Hill;翻译:王雨桐;校对:蒋雨畅
本文约1900字,建议阅读8分钟。
本文将简要盘点R中常用的9个可视化包,并通过简要介绍包的特点和相关案例来帮助读者深入理解可视化包。
如果最近浏览了R包的目录,你会发现可用包的数量已经达到了12550个,足以让人眼花缭乱。这意味着现有的包几乎足以解决所有你能想象到的数据可视化任务,从癌症基因组可视化到图书的可视化分析。
对于R菜鸟或想提升R数据可视化能力的人来说,CRAN目录看起来是一种尴尬的富有——数据可视化的包过多,不知从何入手。
为了解决这种问题,今天我们要盘点9个实用的跨学科R数据可视化包。为了减少在本地运行R的麻烦,您可以使用 Mode的R Notebooks。
R Notebooks链接:
https://about.modeanalytics.com/notebooks/
译者注:本文提及的包大多提供交互性操作,文中插图仅供参考,建议访问文中链接查看案例,且链接中附有代码。
1. ggplot2
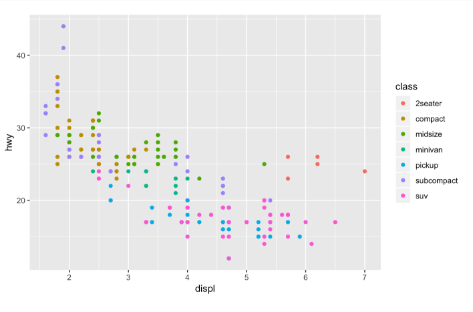
散点图(Hadley Wickham/Tidyverse)
尽管在R中很容易完成基本绘图,但如果需要自定义绘图,事情就会变得复杂得多。这就是ggplot2诞生的原因:为了让定制绘图更容易。
正如其作者所言,“ggplot2解决了许多繁琐的细节问题(比如绘制图例),并提供了一个强大的图形模型,这有助于轻松地生成复杂的多层图形。”
ggplot2以《The Grammar of Graphics》这本书中的思想为基础,将图理解成组成完整绘图的不同图层。例如,在ggplot2中你可以从绘制坐标轴开始,然后加入点,线和置信区间等。
ggplot2的缺点是比R中的基础画图要慢,并且初学者会发现上手很困难。但支持者为此辩解称,学习ggplot2和(更普遍地说)用tidyverse处理数据,对任何使用R的数据科学家来说都有巨大的好处。(译者注:tidyverse是为数据科学家所设计的,集合了数据处理和R的可视化包)
作者:Hadley Wickham
详细链接:https://ggplot2.tidyverse.org/
2. Lattice
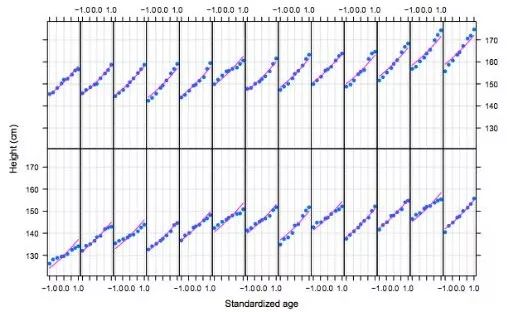
拟合模型(Deepayan Sarkar)
当你需要对多变量数据进行可视化分析时,Lattice是最佳选择。Lattice是由Trellis graphics衍生的一个绘图系统。他能帮你生成绘图的平铺面板,以用来比较给定变量的不同值或子集。(如上图所示,这些平面图常常看起来像花园的栅栏。)
Lattice是基于grid包搭建的,并继承了grid包的大量特征。由于grid随后被列为基本的R包,所以R的老用户对Lattice的逻辑不会感到陌生。
作者:Deepayan Sarkar
详细链接:http://lattice.r-forge.r-project.org/
3. Highcharter
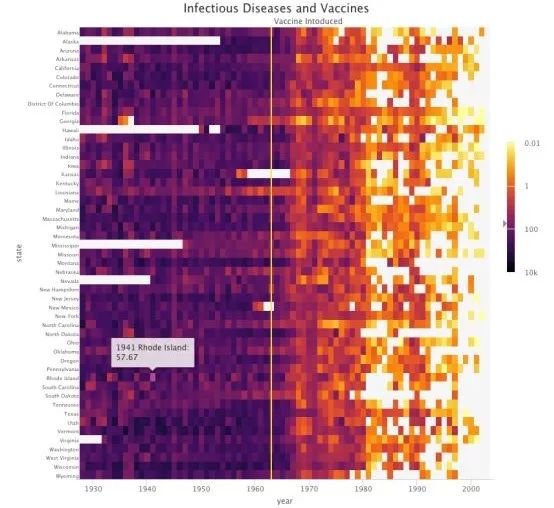
交互热图((Joshua Kunst)
Highcharter是R中Highcharts的改进,是一个JavaScript中的交互式可视化库。和它的前身一样,Highcharter配备了非常强大的API。
Highcharter使动态图表变得简单。通过使用hchart()这样一个函数,它可以绘制R中各种对象类的图,从数据框到树形图再到谱系图。它也为代码的编写者提供了可行的方法以完成其他流行的Highcharts图,如Highstock(绘制金融图)和Highmaps(基于网络项目的原理图)。
该包配有自定义的主题,以及内置的主题,如“经济学家”、“金融时报”和“538”,便于用户向专业人士借鉴图表。
作者:Joshua Kunst
详细链接:http://jkunst.com/highcharter/
4. Leaflet
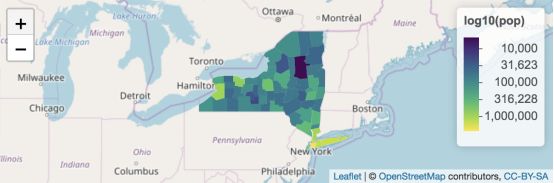
GeoJSON map (RStudio)
类似于highcharter,R中的Leaflet包也是基于非常流行的同名JavaScript程序库。
Leaflet提供了一种简便且有效的方法来构建交互地图。您可能已经从《纽约时报》、《华盛顿邮报》、GitHub以及类似Mapbox和CartoDB等GIS专业网站上看到过相关地图(以JS形式)。
Leaflet的R接口是由htmlwidgets框架发展而来,这使得在R Markdown documents (v2), Rstudio和Shiny apps中很容易控制并集成Leaflet地图。
作者:Joe Cheng, Bhaskar Karambelkar, Yihui Xie
详细链接:https://rstudio.github.io/leaflet/
5. RColorBrewer
ROYGB Scatter (ModernData)
RColorBrewer很好地展示了R的一个优点:在各种图表和地图中调整颜色。
本包基于Cynthia Brewer关于在制图中运用颜色的研究,它帮助你生成美观的序列色、分色或定色调色板。和Plotly搭配使用,可以得到更好的效果。
附案例链接:https://moderndata.plot.ly/create-colorful-graphs-in-r-with-rcolorbrewer-and-plotly/
作者:Erich Neuwirth
详细链接:http://colorbrewer2.org /#type=sequential&scheme=BuGn&n=3
6. Plotly
线型图(Plotly)
也许你知道Plotly是一个数据可视化的在线平台,但你是否知道可以在R或Python中应用它?
与highcharter类似,Plotly擅长绘制交互图表,但它提供了一些其他包中没有的图表如:
等值线
https://plot.ly/r/contour-plots/
蜡烛图
https://plot.ly/r/candlestick-charts/
3D图
https://plot.ly/r/3d-charts/
作者:Erich Neuwirth
详细链接:https://plot.ly/
7. sunburstR
旭日图展示棒球数据(Kent Russell)
旭日图适用于描述事件的序列,如体育数据和产品的用户流。
运用旭日图,你可以像Kerry Rodden一样构造如图所示的旭日图。此类图表是交互式的,可以帮助用户通过强大的方式探索序列数据。
附案例链接:https://bl.ocks.org/kerryrodden /7090426
作者:Kent Russell, Kerry Rodden, Mike Bostock, Kevin Warne
详细链接:https://www.rdocumentation.org /packages/sunburstR/versions/2.0.0
8. RGL
Iris数据的3D图 (Duncan Murdoch)
想要在R中得到交互的3D图时,可以使用RGL。它的逻辑是根据R中的基础graphics建模的,但它是以三维形式呈现而不是二维。例如Lattice,它也受到grid包的启发(尽管两者在技术上并不兼容)。所以对经验丰富的R用户来说,这非常容易上手。
RGL有很多炫酷的技能,包括可以选择3D形状、灯光效果、物体的各种质感,甚至可以运用动漫制作调整3D情景。
作者:Daniel Adler ,Duncan Murdoch
详细链接:https://cran.r-project.org/web/packages /rgl/vignettes/rgl.html
9. Dygraphs
选定范围的时间序列图(RStudio)
此包为dygraphs提供了一个R接口。dygraphs是一个快速且灵活的JavaScript绘图程序库,用于探索时间序列数据集。dygraphs的强大之处在于,它具备很强的交互性,具有默认的鼠标悬停标签、缩放和平移等功能。他还有其他实用的交互特征,例如同时段比较和时段选定。
但是dygraphs的交互性并不是以速度为代价:它可以处理有百万数据点的大型数据集而不减慢它的效果。你也可以结合RColorBrewer和dygraphs来为时间序列选择不同颜色的调色板。
附案例:
https://rstudio.github.io/dygraphs/gallery-series-options.html
作者:Dan Vanderkam, RStudio
详细链接:https://rstudio.github.io/dygraphs/
原文标题:
9 Useful R Data Visualization Packages for Any Discipline
原文链接:
https://blog.modeanalytics.com/r-data-visualization-packages/
译者简介:王雨桐,统计学在读,数据科学硕士预备,跑步不停,弹琴不止。梦想把数据可视化当作艺术,目前日常是摸着下巴看机器学习。
转自:数据派THU 公众号;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
关联阅读:
原创系列文章:
1:从0开始搭建自己的数据运营指标体系(概括篇)
2 :从0开始搭建自己的数据运营指标体系(定位篇)
3 :从0开始搭建自己的数据运营体系(业务理解篇)
4 :数据指标的构建流程与逻辑
5 :系列 :从数据指标到数据运营指标体系
6: 实战 :为自己的公号搭建一个数据运营指标体系
7: 从0开始搭建自己的数据运营指标体系(运营活动分析)
数据运营 关联文章阅读:
运营入门,从0到1搭建数据分析知识体系
推荐 :数据分析师与运营协作的9个好习惯
干货 :手把手教你搭建数据化用户运营体系
推荐 :最用心的运营数据指标解读
干货 : 如何构建数据运营指标体系
从零开始,构建数据化运营体系
干货 :解读产品、运营和数据三个基友关系
干货 :从0到1搭建数据运营体系
数据分析、数据产品 关联文章阅读:
干货 :数据分析团队的搭建和思考
关于用户画像那些事,看这一文章就够了
数据分析师必需具备的10种分析思维。
如何构建大数据层级体系,看这一文章就够了
干货 : 聚焦于用户行为分析的数据产品
如何构建大数据层级体系,看这一文章就够了
80%的运营注定了打杂?因为你没有搭建出一套有效的用户运营体系
从底层到应用,那些数据人的必备技能
读懂用户运营体系:用户分层和分群
做运营必须掌握的数据分析思维,你还敢说不会做数据
合作请加qq:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

这篇关于推荐 :盘点9个适用所有学科的R数据可视化包(附链接)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








