本文主要是介绍铝型材表面瑕疵识别-Are you OK?队-1-解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关联比赛: [飞粤云端2018]广东工业智造大数据创新大赛—智能算法赛
本次大赛分为初赛、复赛和决赛三个阶段(9月17日-11月22日),初赛是分类任务,复赛是检测任务,决赛是现场答辩。
经过2个多月的算法角逐和决赛答辩,我们团队(Are you OK?)获得了最终的冠军,感谢天池提供的平台。
这里着重介绍下复赛的答辩方案,对初赛感兴趣的同学可以参照我们的开源代码。
[初赛开源代码1](https://github.com/herbert-chen/tianchi_lvcai)
[初赛开源代码2](https://github.com/OdingdongO/pytorch_classification)
决赛答辩是比较系统的总结了比赛的方案和试验,所以这里和现场答辩内容重复度较高。

在开始介绍我们的方案之前呢,我们先从参赛队伍的角度来回顾一下这次的赛题。这次的赛题要求在给定的图片中 定位出铝材缺陷的位置,并准确识别缺陷的类型,这在计算机视觉中是一个很具有挑战性的质检问题。这里是一些 缺陷图片的例子。从数据中可以看到,脏点的占比面积特别小,喷流与背景很相似,擦花很不规则。
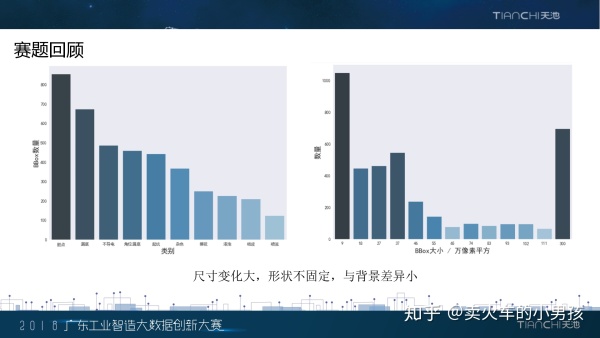
我们对主办方提供的数据做了一个大体的分析。左边的柱状图显示了每个类别样本的数目,右边的图显示的是缺陷 框大小的粗略统计。我们可以看到,大部分的类别是十分均衡的,脏点这个类的数量较多。缺陷框的大小两级分化 比较严重。在这其中,小样本的缺陷框基本上都是脏点的类别,这也是这个赛题的难点之一。
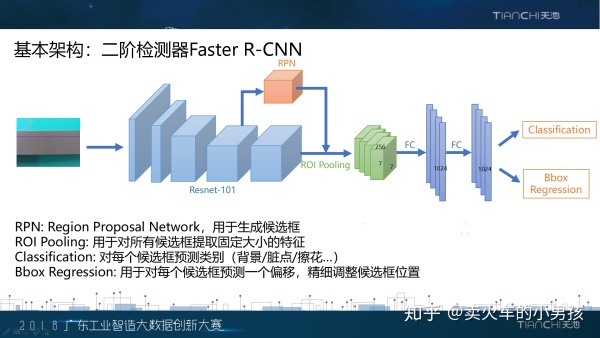
下面我将介绍我们在比赛中采用的具体方案。我们采用二阶检测器Faster R-CNN作为我们的基本架构。所谓的二阶 检测器,就是先由一个region proposal network来生成一些候选框。这些候选框会通过ROI Pooling层及两个全连 接层提取特征,最终预测缺陷的类别以及再次调整候选框的位置。Faster R-CNN是在工业界和学术界应用都非常广 泛的通用物体检测方案,主要的优势是精度高,速度快。
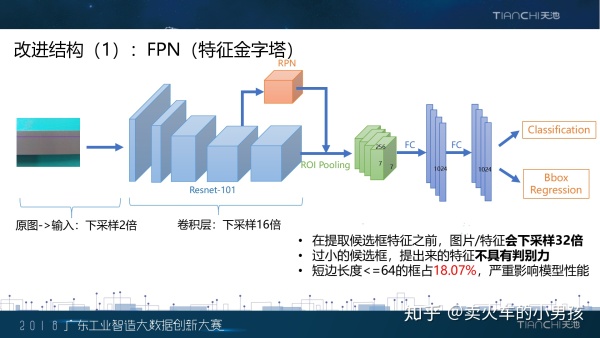
在这个架构中,我们注意到了一些细节。原始图片的分辨率非常的大,是19202560。为了减少计算开销,我们首 先会将图片缩小两倍之后才作为网络的输入。主干网络我们选取的是Resnet-101,在整个卷积的过程中,提取到特 征的大小相对于输入图片是缩小了16倍。也就是说,从原图,到最后一层的卷积特征,空间大小一共下降了32倍。 由于之后每一个候选框特征会被缩放到77的大小,如果说本身缩放前的特征就非常的小,那么缩放之后的特征是 不具有判别力的。我们统计了一下数据集中边长<=64的样本,发现这类小样本占了整个数据集的10%,这会严重 地影响性能。
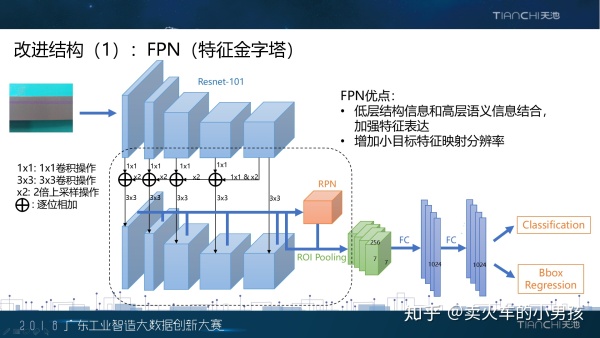
为了解决这个问题,我们采用了学术界非常常用的特征金字塔结构来对网络进行改进。我们总结了一下,特征金字 塔在这个任务中具有两个优点:第一,从这个示意图我们可以看到,低层的特征进过卷积,上采样操作之后和高层 的信息进行融合在卷积神经网络中,高层,也就是后面的特征具有强的语义信息,低层的特征具有结构信息,因此 将高低层的信息进行结合,是可以增强特征的表达能力的。第二,我们将候选框产生和提特征的位置分散到了特征 金字塔的每一层,这样可以增加小目标的特征映射分辨率,对最后的预测也是有好处的。
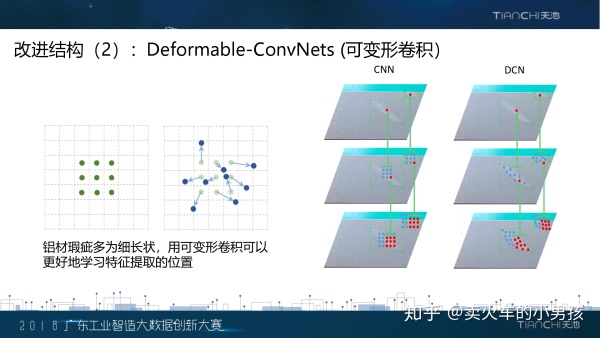
我们采用的第二个改进方案是Deformable Convolutoin可变形卷积。我们发现在数据集中,铝材的瑕疵有很多是 这种条状的,传统正规的正方形结构的卷积对这种形状的缺陷处理能力还不够强。因此我们采用了可变形的卷积, 在卷积计算的过程中能够自动地计算每个点的偏移,从而从最合适的地方取特征进行卷积。右边的示意图大致描述 了可变形卷积的过程,它能够让卷积的区域尽可能地集中在缺陷上。
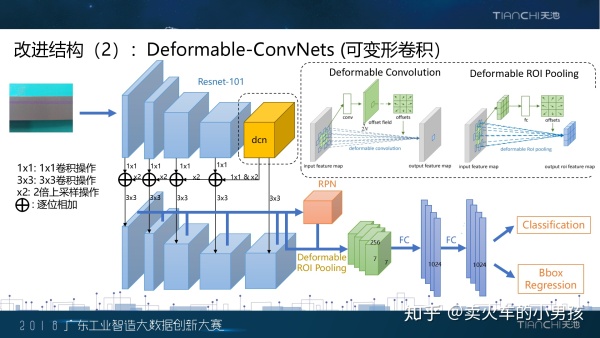
具体实现上,我们将原本resent结构的最后一个block改成了可变卷积,原因是在可变卷积的实现中,需要基于前面 的特征来学习一个偏移,前面的特征得足够强才能保证这个偏移不会乱学,因此我们只改动了最后一个block。总体 的框架还是跟前面FPN的一样。

我们的第三个改进方案,是在提取ROI特征的时候,引入了context上下文信息,我们把这个操作叫做contextual roi pooling。我们用上面两个例子来说明上下文信息的好处。Faster R-CNN是一个先生成候选框,然后精调候选框的 过程,那么第一步生成的候选框势必会有偏大或者偏小的情况。之前的方法可以理解成用框内部的信息来推断框的 位置,左边这个例子是框偏大的情况,根据内部信息是可以知道框应该往里调的,但是右边这个例子框偏笑了, 我们能知道该往外调整,但是该调多少呢这个是无从知晓的。因此一个显而易见的想法,就是把整张图片的信息也 送给这个候选框当特征,这样相当于让每个候选框以整张图片作为参考,这样呢每个框就知道该往哪调了。
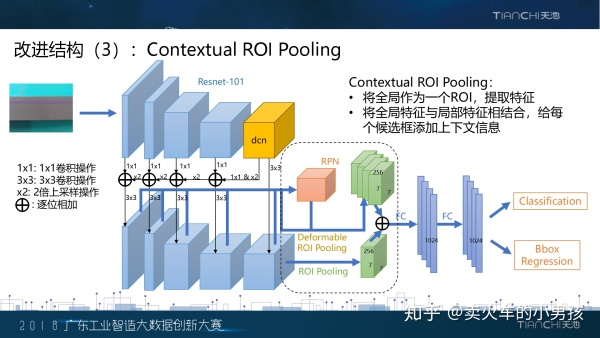
具体的实现是这样,我们把整张图片也作为一个roi,用同样的ROI Pooling提取全局的特征,然后跟每一个候选框 的特征相加,再进行后面的分类和回归操作。这样的实现只多进行了一个roi的特征提取和一个特征相加的操作, 却能大大地提升准确率。
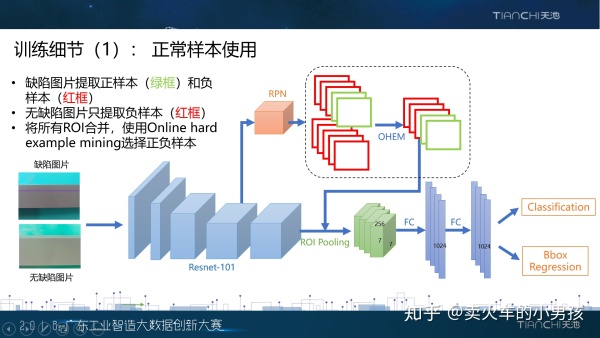
下面我们介绍一下网络训练过程中的一些细节。数据集里面是有提供无缺陷样本的,我们也对这些图片进行了使用。 在检测器的训练过程中,有一步是正负样本的选择。我们在训练的时候使用了一个策略,每次会随机选择一张缺陷 样本和一张无缺陷样本,然后训练的正样本会在缺陷图片中选择,负样本会在两张图片中都选择,两张图片的所有 正负样本合起来做一个OHEM,再进行后面的训练操作。这样的好处是,充分利用了无缺陷样本,增大了模型判别 背景信息的能力。

我们还注意到了数据的一个特性。铝材的缺陷是具有翻转不变性的,将一张图片水平和竖直翻转之后,他的瑕疵信 息是不会变的,也就是说,我们将图片进行翻转之后,再将框做一个变换到对应的位置,这样可以构建出一批新的 数据来。通过这样的数据扩增方式,我们把训练数据扩增了四倍,也因此提升了模型的鲁棒性。
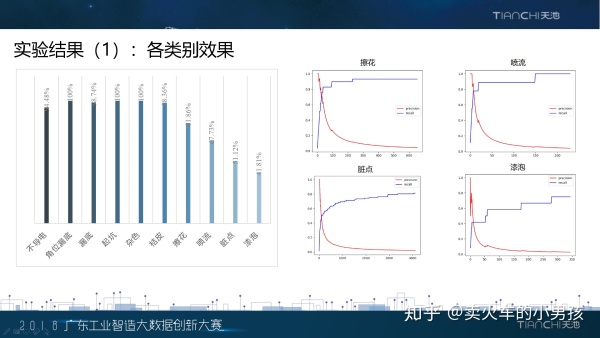
下面我们在整个过程中生成的一些实验结果。左边是在验证集上实验出来的分数,其中擦花,喷流,脏点,漆泡这 四个类的分数。右边这四个曲线图展示了这四个类的准确率和召回率,其中红色是准确率,蓝色是召回率。通过分 析实验和结果,我们发现擦花和喷流差的原因是基本都是召回率较低。
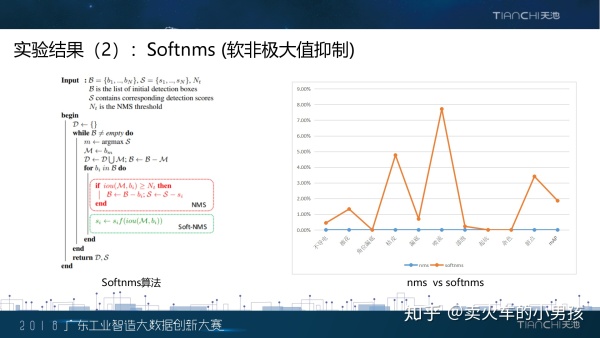
针对前面提到的问题,我们在生成检测结果的时候,用了softnms来提高模型分数。softnms的作用是在框之间互 相抑制的时候使用了较温和的策略,让被抑制过的框还有机会重新被选上,从而提高召回率。从右边曲线图可以看 到,softnms在每个类上都有提升。

我们在比赛A榜的时候验证了每一个方案的效果。从中我们可以看到我们提出的每一个方案都有1%以上的提升,最 终我们的融合模型在A榜上也得到了86.78mAP的成绩,在B榜和C榜中也均在81%以上,在排行榜上排名第一,说明我们方案有较强的鲁棒性
[其他链接](https://zhuanlan.zhihu.com/p/50548998#comments)
查看更多内容,欢迎访问天池技术圈官方地址:铝型材表面瑕疵识别-Are you OK?队-1-解决方案_天池技术圈-阿里云天池
这篇关于铝型材表面瑕疵识别-Are you OK?队-1-解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







