本文主要是介绍一个数据人眼中的《上游思维》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

最近读了《上游思维》这本书,很受启发,我想从一个数据人的角度来聊一聊我对这本书的读后感。上游思维本质上是帮助我们解决问题,我发现在解决问题相关的每个阶段:发现问题、找到解决问题的方法、解决问题的过程中、评估问题以及预防问题等,数据都发挥了不可替代的至关重要的作用。
利用数据发现问题
预见问题的能力让我们拥有了更多解决问题的空间,上游思维的重要一环就是我们要在问题的上游发现问题。发现问题靠的不是想象,而是数据(证据)。
书中举了一个例子。美国犹太保健集团是提供紧急医疗服务的一家企业,他们希望在人们拨打911后,救护车能够尽快抵达现场。因此,他们利用历史数据创建了复杂的模型,以预测911报警电话会在何时来自何地。在不进行任何数据分析之前,你不太可能知道“问题”出现在哪里,你甚至不知道当前的状况是否存在问题。
经过数据分析之后,犹太保健集团发现了明显的规律。有一些符合人的直觉,但也有一些出乎意料。比如在疗养院的用餐时段911电话会出现一个峰值。
“如果你生活在这样的一个社区里,哪天意外出现心脏停搏,你的生死可能就取决于你住得离消防站有多近。” 所以美国犹太保健集团根据上面发现的规律,提前在特定的时间将救护车安排到特定的地点附近。一旦知道了问题是什么,解决方案可能是简单的。
病人显然也对他们获得的护理很满意:94%的患者表示愿意向其他人推荐犹太保健集团。
利用数据找到解决方案
如上文所说,一旦我们通过数据准确发现了问题,解决方案可能是很简单的。所以发现问题和解决问题常常是一回事。下面再看书里的另一个例子。
纽约市的审计长斯科特·斯金格开为帮助政府减少庭外和解而支付的赔偿金额,创建了全新的数据驱动工具,他的团队分析了全年大约3万起对政府提出的索赔案,据此绘制地图,编制索引,寻找其中的规律。
比如他们发现布鲁克林游乐场的一架秋千就导致了多起诉讼,因为秋千挂得太低,2013年就有5个孩子荡秋千时摔断了腿。所以,如果有人走过去把秋千升高六英寸,这个大问题就解决了。
类似这样的例子真的足够具有启发性,它让我真切感受到数据的强大力量。当然,这里并不局限于“大数据”,实际上,很多能产生洞见的数据并不大。
避免错误的报警
书里提到一个观点我深有同感:人是会对警报产生疲劳的,如果一切都能引发警报,那就没有什么能真正得到重视了。其实这就是“狼来了”的故事,但是在工作中真的每个人能记住这则寓言带来的警告吗?
我们要发现的是重要的问题,而不是对所有问题都进行响应。书里举了一个非常耐人寻味的例子。
在21世纪的头10年,韩国被确诊患有甲状腺癌的人数急剧上升。到2011年,甲状腺癌的发病率相比1993年翻了15倍。这是一个非常可怕的公共卫生问题。癌症并非传染性疾病,不应该传播得如此之快,这也太奇怪了。
研究发现,甲状腺癌数量飙升是因为韩国的卫生部门鼓励人们接受筛查,卫生部门发现大量民众的甲状腺里都生活着安静的“小乌龟”(慢性的危害性不大的癌症)。绝大多数病人接受了侵入性治疗,通常是接受手术,切除甲状腺。5年后,99.7%的人仍然活着。但是也有证据表明,这些人如果不进行甲状腺癌的筛查,大概率也一样能活五年,甚至更久。
这个例子可能有点争议,我认为提前发现癌症是没问题的,问题在于我们现在的医疗系统通常都会采取更激进的方式从而导致过度医疗(这是个系统问题,书中有讲到)。 事实就是韩国卫生部门对甲状腺癌这种大规模的筛查成了某种过度的报警,导致了很多本不该做手术的人都做了手术。
在解决问题的过程中
书中提到,要想让团队发挥出最佳水平,就要告知他们一个清晰明确、令人信服的目标,以及用于衡量进展的实时数据流,其余的就让他们自由发挥。作者管这个叫做计分牌。在解决问题的过程中我们要仔细选择数据/指标,你不可能用一个静态的数据去解决一个动态的问题,所以这个记分牌一定是实时更新的。
另外,作者还强调要对具体的案例进行分析以获得系统性解决方案的洞见。
宏观始于微观。在思考宏大的问题时,我们必须考虑庞大的数字。怎样才能帮助1000个人解决问题?你的第一反应可能会是:我们必须通盘考虑,因为我们没法逐个地帮助这1000人。但事实证明,这种观点大错特错。本书里的英雄人物经常会基于具体的名单来组织他们的工作。…… 我们从中得到的启示是:只有懂得如何帮助每个人,你才有可能帮助1000个人,乃至100万个人。
在衡量效果的过程中
2005年8月底,“卡特里娜”飓风袭击了新奥尔良。这是一场非常罕见的灾难,造成了重大损失。令人有些欣慰的是,就在这次飓风之前,新奥尔良曾经组织过一次飓风演习(模拟的飓风名字叫帕姆),帕姆飓风规模和卡特里娜飓风非常接近。那么这次演习有没有成功降低飓风带来的损失呢?
下面有一张对比图。
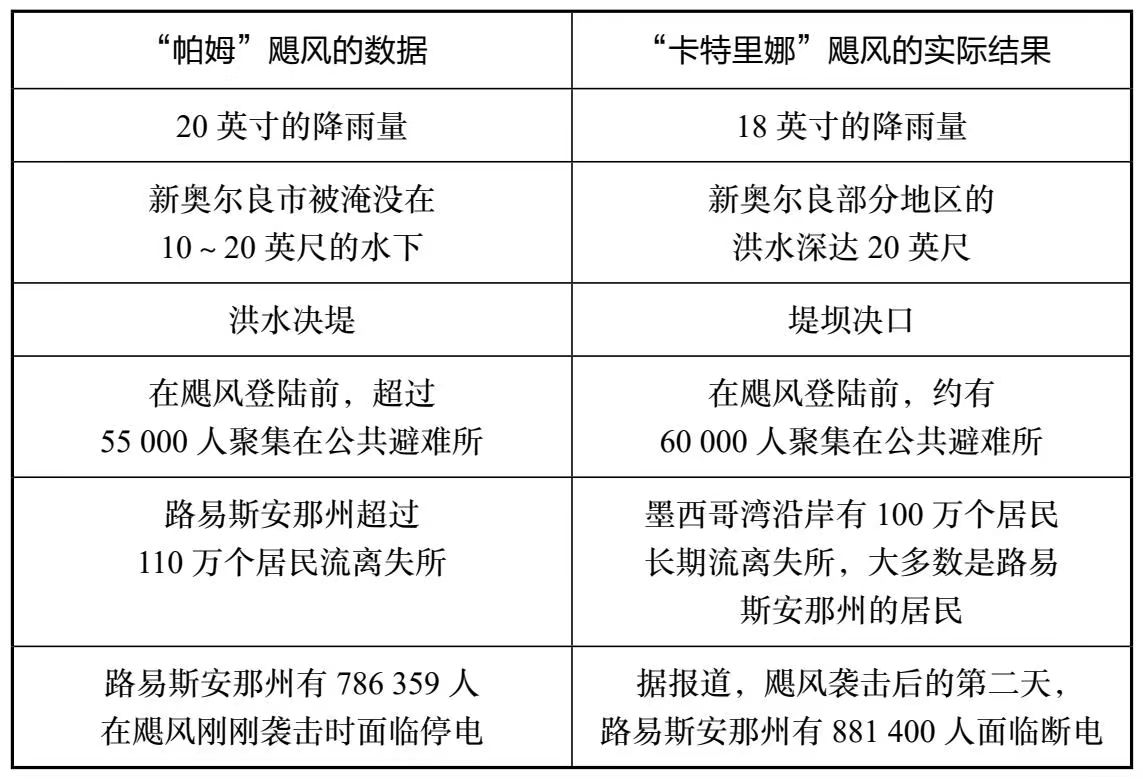
乍看起来,演习好像白做了,完全没有起到什么效果啊!但问题是,人们很难通过严格的对比实验,知道没有演习的时候造成的损失会不会更大,所以你用来衡量效果的指标到底是不是科学和严谨的,这点至关重要。
我们不妨再看一眼下面的这张图“
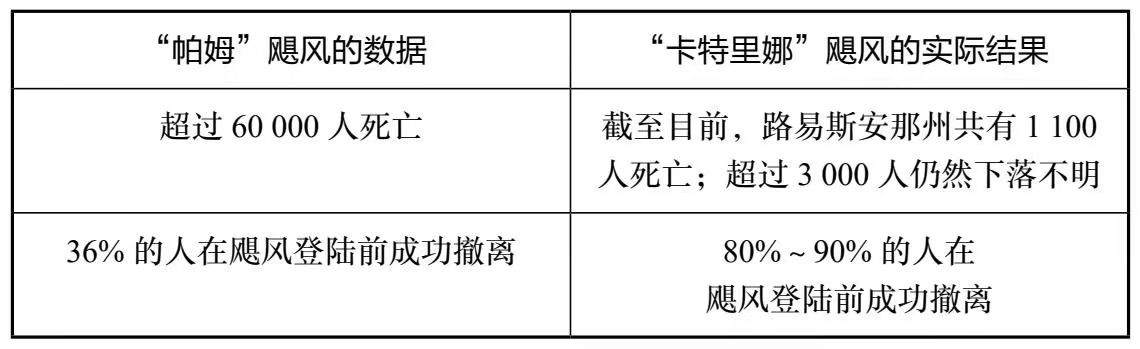
当然,这个基于模拟的数据也不完全是严谨的,但如果你相信第一张图的模拟结果,那么第二张图的结果一定也是接近真实的。那么这次演习无疑是相当成功的。
这个例子告诉我们:要避免错误的指标,要避免单一指标。
在预测未来
现在大数据+人工智能已经展现出了非常强大的预测能力,天气预报的准确度也得到了巨大的提升。不过在这里我想强调,很多时候预测未来是困难的,不要迷信关于预测的数据。
作者在书中提到了很多利用上有思维解决问题的成功案例,但也不无谦虚地在结尾说到,把这种成功的经验在更大范围内的推广不一定奏效,不能做出这样简单的预测。
“芝加哥大学犯罪实验室”的延斯·路德维格表示:“越来越多的人开始着手解决项目规模化的问题,但我们现在还处于非常初期的阶段。我们根本不知道要如何将对1000个孩子奏效的社会项目推广至5000个孩子。”
人脑天然容易接受的是线性思维,按照线性思维的推断,对1000个孩子奏效,很显然推广到5000个也应该奏效。但真实的世界是非线性的,这点在《规模》这本书里有更精彩的讨论。总之,我们应该要有规模思维,不同规模和不同尺度下,可能是完全不一样的规律。我们举个互联网产品中的例子:对1万个用户奏效的方案,推广到10倍甚至100倍的用户还会产生一样的效果吗?根据我粗浅的经验,答案通常是否定的。
总结
这是一本不错的书,里面的内容远远不至于我从数据人视角所谈的这些,非常值得一看。
如果你喜欢我的文章,欢迎到我的个人网站关注我,非常感谢!
这篇关于一个数据人眼中的《上游思维》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







