本文主要是介绍【Linux】fork函数详解and写时拷贝再理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤
📃个人主页 :阿然成长日记 👈点击可跳转
📆 个人专栏: 🔹数据结构与算法🔹C语言进阶🔹C++🔹Liunx
🚩 不能则学,不知则问,耻于问人,决无长进
🍭 🍯 🍎 🍏 🍊 🍋 🍒 🍇 🍉 🍓 🍑 🍈 🍌 🍐 🍍
文章目录
- 一、fork是什么?
- 二、fork使用演示
- 三、问题解决
- 1.fork为什么fork()要给子进程返回0,给父进程返回子进程pid?
- 2. fork()函数创建子进程
- 3.读时共享,写时拷贝
- 四、写时拷贝的原理
一、fork是什么?
fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。
总结来说就是:
1️⃣ 创建一个子进程,其返回值为pid_t。
2️⃣ 调用fork函数之后,一定是两个进程同时执行fork函数之后的代码,而之前的代码以及由父进程执行完毕。
3️⃣ fork成功后产生两个进程,一个是子进程,一个是父进程。
(1)子进程fork函数返回0,
(2)父进程fork返回新创建子进程的进程PID,
(3)错误返回负值。
4️⃣ 4.fork是把已有的进程复制一份,当然把PCB也复制了一份,然后申请一个PID:子进程的PID=父进程的PID+1;
5️⃣fork后的代码会执行两遍。
6️⃣读时共享,写时拷贝
二、fork使用演示
运行如下代码:
1 #include<stdio.h>2 #include<unistd.h>3 4 int main(void) 5 {6 7 fork();8 printf("after: only one line\n");9 sleep(1);10 return 0;11 }我们只写了一个printf语句,却打印了两遍。也印证了5️⃣fork后的代码会执行两遍。原因就是:fork执行后生成父子进程。

那么根据第三点3️⃣ fork成功后产生两个进程,一个是子进程,一个是父进程。子进程fork函数返回0;父进程fork返回新创建子进程的进程PID。我们在写一段代码来验证一下。
#include <stdio.h>#include <unistd.h>#include <sys/types.h>int main(void){printf("begin: 我是一个进程, pid: %d, ppid: %d\n", getpid(), getppid());pid_t id = fork();if(id == 0){// 子进程while(1){printf("我是一个子进程, pid: %d, ppid: %d\n", getpid(), getppid());sleep(1);}}else if(id > 1){// 父进程while(1){printf("我是一个父进程, pid: %d, ppid: %d\n", getpid(), getppid()); sleep(1);}}else{printf("error, fork创建子进程失败\n");}return 0;
}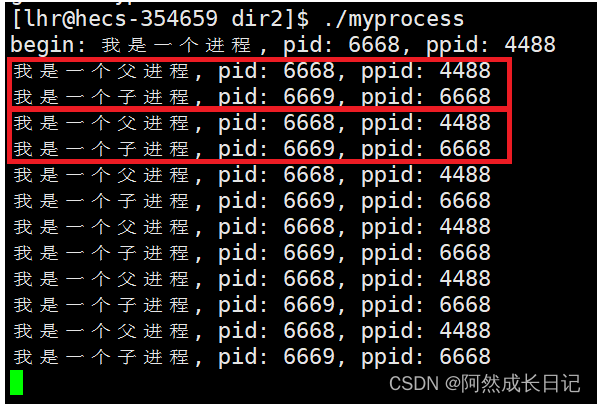
看到这里你会惊奇的发现,这个代码的if…else…分支可以同时进去。这在以前是没有发生过的。这也正是父子进程同时执行的结果。
三、问题解决
1.fork为什么fork()要给子进程返回0,给父进程返回子进程pid?
- 上面我们说到当进程的代码执行到fork()函数的时候,会将执行流一分为二,父子进程通过不同的 id 返回值来区分,以此执行不同的代码块。:因为父子进程是两个不同的进程,所以需要根据这个不同的返回值来进程区别
- 再就是为什么一定是给父进程返回子进程的PID呢?不能反过来吗?这是因为,父亲只能有一个,但是可以有很多儿子,如果给父进程返回0,那么有那么儿子的标识都是0,就无法区分了。
2. fork()函数创建子进程
- 在上面我们讲到过【进程 = 内核数据结构 + 代码+数据 】,当我们在执行完fork()函数后,子进程被创建出来,那么它的PCB结构体即 task_struct 会被构建出来,我们知道的是在每个进程的结构体中有PID和PPID这两个成员,而且对于子进程中的PPID恰好就是父进程中的PID +1。所以子进程大部分的属性就是以父进程为模版创建的,相当于把父进程拷贝了一份,对部分属性做了修改。
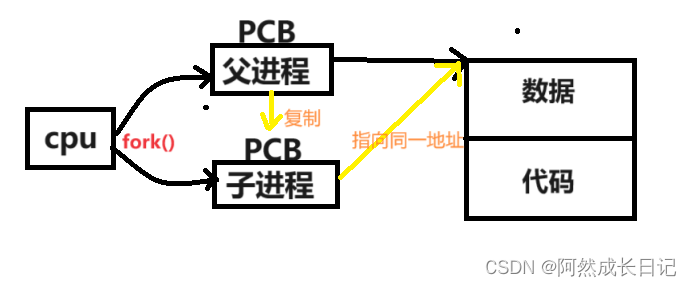
也就是说,子进程几乎拷贝了父进程的所有内容,包括代码数据和绝大部分的PCB。上面我们谈到子进程要去拷贝数据的原因是在于【并发修改】的问题,但若是子进程只是读取数据但是不修改呢?也需要去完整地拷贝一份数据吗?不,完全不需要!这会使得资源消耗过大!(如上图🖕)
3.读时共享,写时拷贝
fork函数执行时,不会直接给子进程拷贝一份父进程的数据,在子进程刚被创建的时候,代码和数据全部都是被共享的,只有当操作系统识别到子进程要对父进程中的数据做修改时,才会在系统的某一个位置开辟一段空间,然后在修改的时候不去修改父进程内部的这个数据,而是去修改拷贝出来的这块数据此为父子进程之间数据层面的写时拷贝。
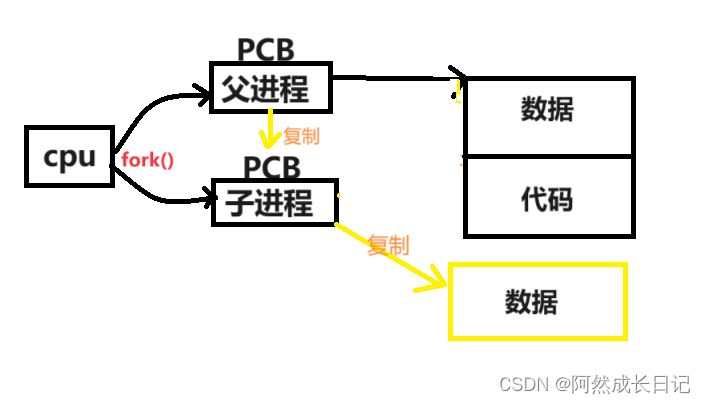
四、写时拷贝的原理
1.为什么要使用写时拷贝?
其核心思想是,如果有多个调用者同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这个过程对其他的调用者是透明的(transparently)。此作法的主要优点是如果调用者没有修改该资源,就不会有副本(private copy)被建立,因此多个调用者只是读取操作是可以共享同一份资源。
- 上面的官方术语简单来说就是: 写时拷贝是浅拷贝解决浅拷贝析构冲突的一种解决方案,几个对象共用一块空间,当执行
读操作时不会有影响,当你需要进行写操作改变一个对象的内容时,空间的值不能被修改,会互相影响,那么就需要单独开辟一块空间将对象拷贝过去然后改,不改变就不需要开辟。
2.写时拷贝的原理
-
写时拷贝技术实际上是运用了一个 “
引用计数” 的概念来实现的。 -
在开辟的空间中多维护四个字节来存储引用计数。
有两种方法:
①:多开辟四个字节(pCount)的空间,用来记录有多少个指针指向这片空间。
②:在开辟空间的头部预留四个字节的空间来记录有多少个指针指向这片空间。【常用】 -
当我们多开辟一份空间时,让
引用计数+1,如果有释放空间,那就让计数-1,但是此时不是真正的释放,是假释放,等到引用计数变为 0时,才会真正的释放空间。 -
如果有修改或写的操作,那么也让原空间的引用计数-1,并且真正开辟新的空间。
这篇关于【Linux】fork函数详解and写时拷贝再理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





