本文主要是介绍TI的C28x系列芯片的存储结构(2)——CLA的RAM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CLA有自己的程序和数据总线,它的RAM存储区分三种:程序RAM(program RAM)、数据RAM(data RAM)和信号RAM(message RAM)。
①program RAM
CLA的程序必须复制到RAM中才能快速执行。CLA的程序可导入到任意一个LSx RAM中,由CPU完成。
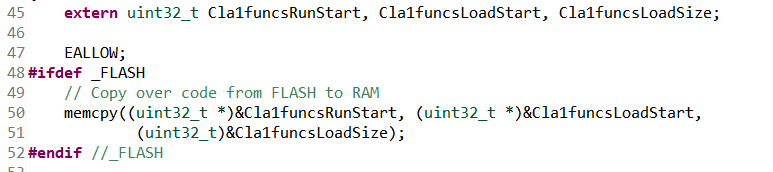
将LSx RAM映射成CLA的program RAM:

例如:
![]()
一旦LSx RAM映射成CLA的program RAM,则CPU不能访问,CLA只能从中读取指令(fetch)。
②data RAM
任意一个LSx RAM也可以作为CLA的data RAM,映射过程:

举例:
![]()
LSx RAM映射成CLA的data RAM,同时其对CPU的映射地址并没有禁止,CPU依然可以进行读写数据访问。
③Message RAM
Memory中有两块:CLA to CPU MSGRAM和CPU to CLA MSGRAM,且只存储data。
CLA to CPU MSGRAM:CLA传递数据给CPU,CLA可读可写数据,CPU只能读数据;
CPU to CLA MSGRAM:CPU传递数据给CLA,CPU可读可写数据,CLA只能读数据。
这篇关于TI的C28x系列芯片的存储结构(2)——CLA的RAM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








