本文主要是介绍人工智能|推荐系统——推荐大模型最新进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近年来,大语言模型的兴起为推荐系统的发展带来了新的机遇。这些模型以其强大的自然语言处理能力和丰富的知识表示,为理解和生成复杂的用户-物品交互提供了新的视角。本篇文章介绍了当前利用大型语言模型进行推荐系统研究的几个关键方向,包括嵌入空间的解释性、个性化推荐的知识对齐、端到端推荐框架的构建,以及基于GPT训练范式的顺序推荐模型等。这些研究不仅推动了推荐系统在技术上的创新,也为理解和改进推荐系统提供了新的理论和实践基础。
LLMRec相关
一、研究1
1.1 论文题目
Demystifying Embedding Spaces Using Large Language Models
1.2 摘要
Embedding 已成为表示关于实体、概念和关联的复杂的信息的关键手段,并以简洁且有用的格式呈现。然而,它们通常难以直接进行解释。尽管下游任务利用这些压缩表示,但要进行有意义的解释通常需要使用降维或专门的机器学习可解释性方法进行可视化。本文解决了使这些嵌入更具解释性和广泛实用性的挑战,通过利用大语言模型(LLMs)直接与嵌入进行交互,将抽象向量转化为可理解的叙述。通过将嵌入注入LLMs,我们使复杂的嵌入数据可以进行查询和探索。我们在各种不同任务上展示了我们的方法,包括 enhancing concept activation vectors (CAVs), communicating novel embedded entities, and decoding user preferences in recommender systems。我们的工作将嵌入的巨大信息潜力与LLMs的解释能力相结合。
1.3 内容概述
物品的embedding是对于物品信息的抽象表示,例如在推荐系统领域中,物品的embeddings可能隐含着关于其质量、可用性、设计、客户满意度等复杂细节,但理解这些抽象表示仍然非常困难。这篇论文提出利用大语言模型的来帮助理解物品的embedding信息。同时作者在文中指出,利用LLMs来进行embedding解释,可以描述embedding space中的一些特定点,即使这些特定点可能并不对应真实物品。例如图2所示,LLMs可以完成为embedding space中一些虚构点提供描述、观看理由等任务。具体而言,该论文提出了一种名为ELM(Embedding Language Model)的框架,利用大型语言模型(LLMs)解释领域嵌入,使用训练好的adapter将领域嵌入向量整合到LLM的Token embedding space中。开发了一种训练方法,用于微调预训练的LLMs以解释领域嵌入。
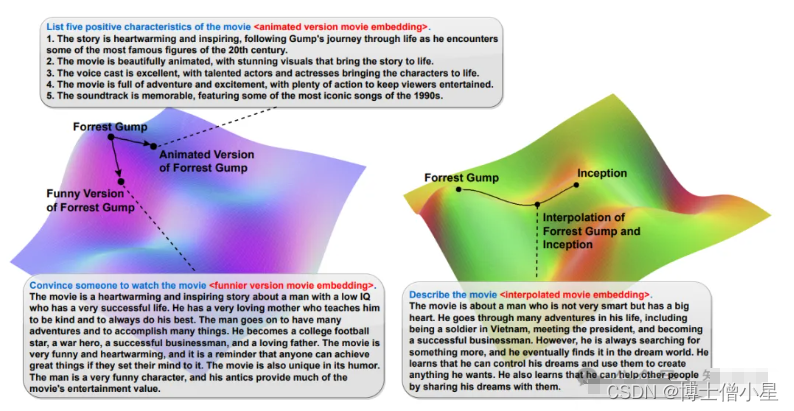
1.4 推荐理由
该文章提供了一个清晰直观的框架,利用大语言模型强大的能力来提供对物品embedding space的解释。这种想法是比较有启发性的,例如在一些生成式推荐框架中,很多时候并不直接生成推荐结果,那么在映射到真实物品空间中之前,也可以考虑使用这样的embedding解释技术来对生成结果进行分析。同时文中生成对embedding的解释也包含多个方面,例如推荐/不推荐理由、可能喜欢该物品的用户群体、物品描述等,也有助于该工作应用在不同的推荐场景下。值得一提的是,该工作的部分训练数据也是由LLMs生成的,这一方面降低了模型的数据收集成本,但另一方面这可能也让人对该模型在真实场景下的能力抱有疑问。总而言之,该工作为如何利用LLMs来理解embedding空间提供了新的思路。
二、研究2
2.1 论文题目
Exact and Efficient Unlearning for Large Language Model-based Recommendation
2.2 摘要
大型语言模型推荐(LLMRec)的不断发展通过使用推荐数据对大型语言模型(LLMs)进行参数高效微调(PEFT)来实现定制化。然而,将用户数据纳入LLMs会引发隐私问题,因此需要有效的遗忘过程来从已建立的LLMRec模型中删除无用数据(例如历史行为)。现有的遗忘方法对LLMRec来说不够有效,主要是因为计算成本高或无法完全擦除数据。在本研究中,我们介绍了适配
这篇关于人工智能|推荐系统——推荐大模型最新进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







