本文主要是介绍DataX数据采集流程(项目),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.CDH介绍
2.ClouderaManager架构
3.服务器
4.dataX架构
5.Datax数据处理流程
6.DataX的使用说明
7.Mysql数据切割
8.Mysql数据导入HDFS
9.查询站点
站点页面如下,可进一步查询导入的数据内容
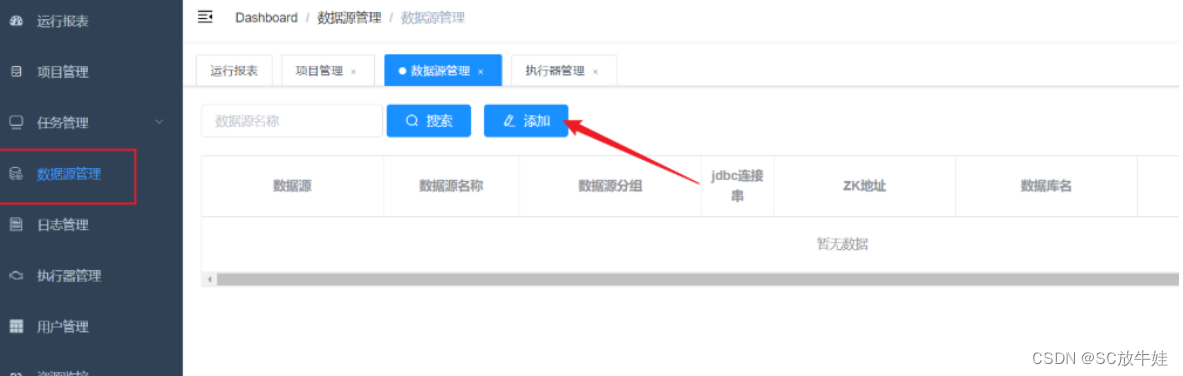
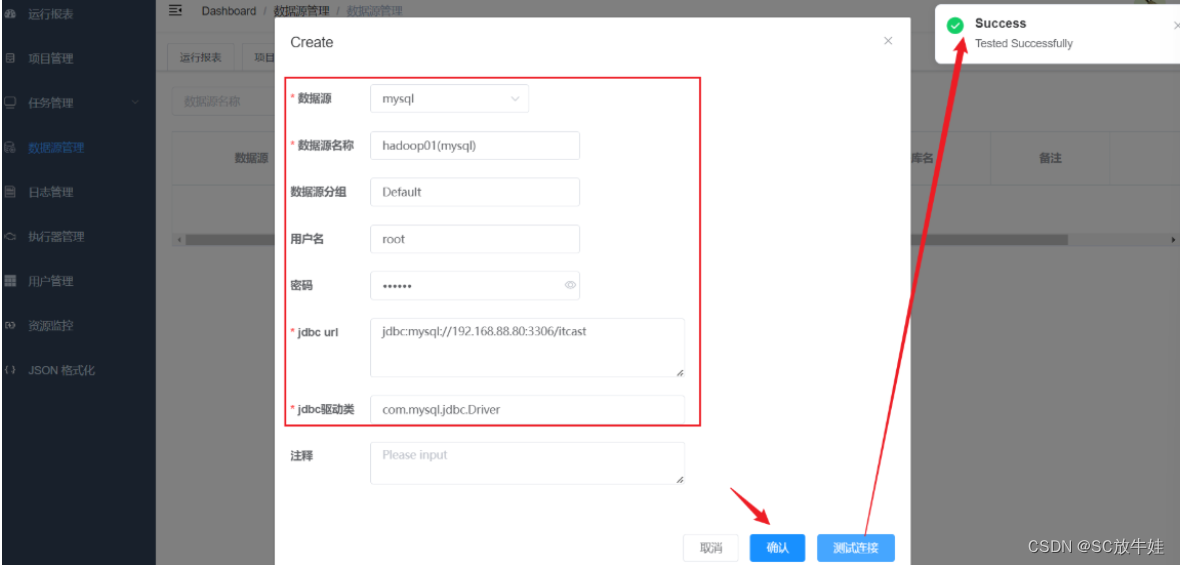
10.dataX-Web访问页面
创建数据库连接
1.CDH介绍
--(1)CDH Cloudera's Distribution Including Apache Hadoop --(2)CDH 是商业版的hadoop,由cloudera公司基于开源的hadoop进行二次开发,封装更多的功能,部分功能需要付费使用 --(3)CDH 集成了一个 CM(Cloudera Manager),使用各B(浏览器)/S(服务器)模型服务,可以在CM中通过web浏览器页面管理维护hadoop集群 --(4)CM的核心角色--server 主服务 处理CM的各类请求--agent 从服务 运行多台服务器上,接受servGr分配的任务
2.ClouderaManager架构
--(1)Server:Cloudera Manager的核心是Cloudera Manager Server。提供了统一的UI和API方便用户和集群上的CDH以及其它服务进行交互,能够安装配置CDH和其相关的服务软件,启动停止服务,维护集群中各个节点服务器以及上面运行的进程。 --(2)Agent:安装在每台主机上的代理服务。它负责启动和停止进程,解压缩配置,触发安装和监控主机 --(3)Management Service:执行各种监控、报警和报告功能的一组角色的服务 --(4)Database:CM自身使用的数据库,存储配置和监控信息 --(5)Cloudera Repository:云端存储库,提供可供Cloudera Manager分配的软件 --(6)Client:用于与服务器进行交互的接口1)Admin Console:管理员可视化控制台2)API:开发人员使用API可以创建自定义的Cloudera Manager应用程序
3.服务器
服务器说明 hadoop01 192.168.88.80 hadoop02 192.168.88.81 账户 root 密码 123456 注意:需要通过域名访问hadoop服务,就需要更改windos下域名解析文件 访问Server: http://hadoop01:7180/cmf/login 账号密码均为admin
4.dataX架构
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。 (1)Reader: Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。 (2)Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。 (3)Framework: Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
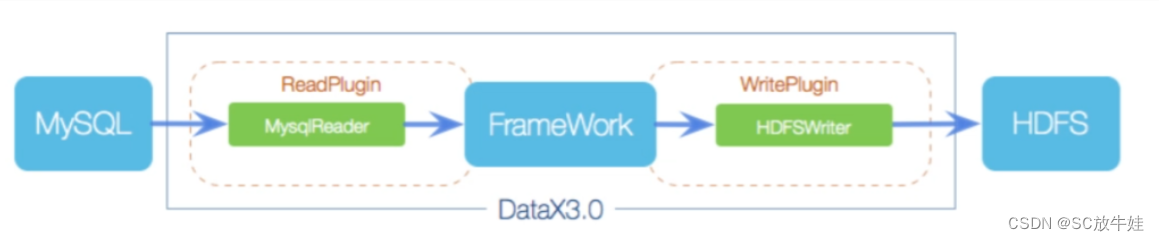
5.Datax数据处理流程
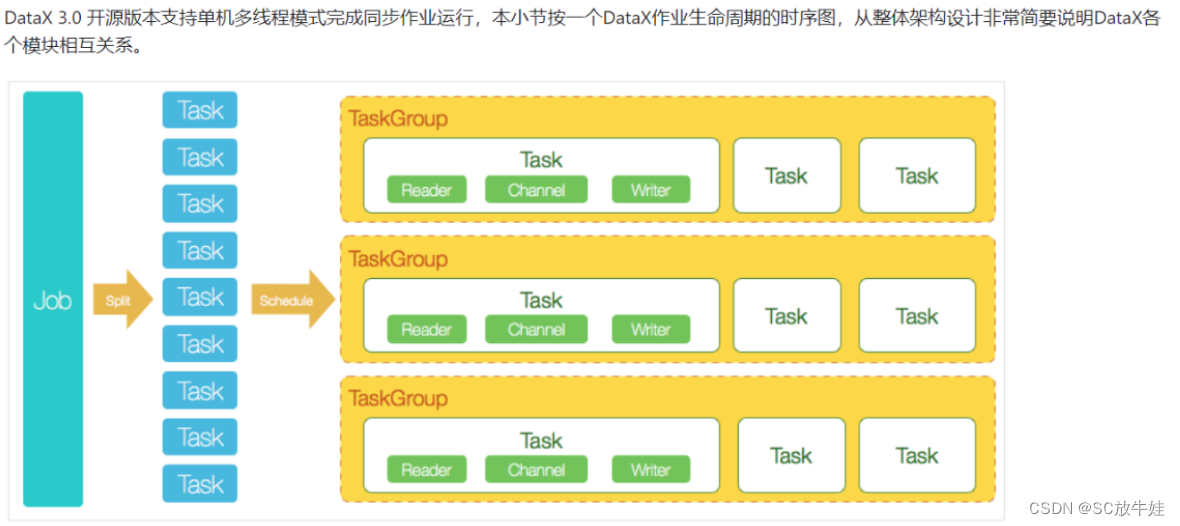
6.DataX的使用说明
-- 切割数据并执行 官网: https://github.com/alibaba/DataX/blob/master/introduction.md (1)启动finalshell连接虚拟机 (2)datagrip中对应虚拟机里创建相应数据库并插入数据 (3)在/export/server/datax/job下创建json文件 (4)切换到/export/server/datax/bin下运行python datax.py ../job/mysql_query.json
7.Mysql数据切割
-- json语言,切割数据过程,虚拟机运行
{"job": {"setting": {"speed": {"channel":1}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","connection": [{"querySql": ["select * from student where id>=3;"],"jdbcUrl": ["jdbc:mysql://192.168.88.80:3306/itcast"]}]}},"writer": {"name": "streamwriter","parameter": {"print": true,"encoding": "UTF-8"}}}]}
}
8.Mysql数据导入HDFS
-- mysql数据导入hdfs(虚拟机数据可视化网站,操作流程同上)
{"job": {"setting": {"speed": {"channel":1}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","column": ["id","name","age","gender"],"splitPk": "id","connection": [{"table": ["student"],"jdbcUrl": ["jdbc:mysql://192.168.88.80:3306/itcast"]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://192.168.88.80:8020","fileType": "text","path": "/data","fileName": "student","column": [{"name": "id","type": "int"},{"name": "name","type": "string"},{"name": "age","type": "INT"},{"name": "gender","type": "string"}],"writeMode": "append","fieldDelimiter": "\t"}}}]}
}
9.查询站点
在C:\Windows\System32\drivers\etc\hosts中添加如下代码 访问站点:hadoop01:9870(具体名称由自己的主虚拟机名决定)

站点页面如下,可进一步查询导入的数据内容

10.dataX-Web访问页面
http://hadoop01:9527/index.html

创建数据库连接
这篇关于DataX数据采集流程(项目)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






