本文主要是介绍GraspNet-1Billion 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里写自定义目录标题
- GraspNet-1Billion
- 总体
- 数据集
- 评价指标
- 网络
- pointnet++:
- Approach Network:
- Operation Network:
- Tolerance Network
- 摘要
- 相关工作
- 基于深度学习的抓取预测算法
- 抓取数据集
- 点云深度学习
GraspNet-1Billion
CVPR2020
上海交大
论文和数据集地址:https://graspnet.net/
总体
主要解决训练数据不足和抓取姿态表示形式不同,没有统一的评估方法;仿真数据和真实场景数据存在gap
本文主要贡献是提出一个大规模数据集,一个统一的评价指标,一个端到端的物体抓取姿态预测方法
数据集

深度相机与机械臂固定连接,控制机械臂沿固定轨迹运动,只需要第一帧的6D位姿,后续的帧通过标定好的相机参数进行传递。
抓取姿态标注流程:
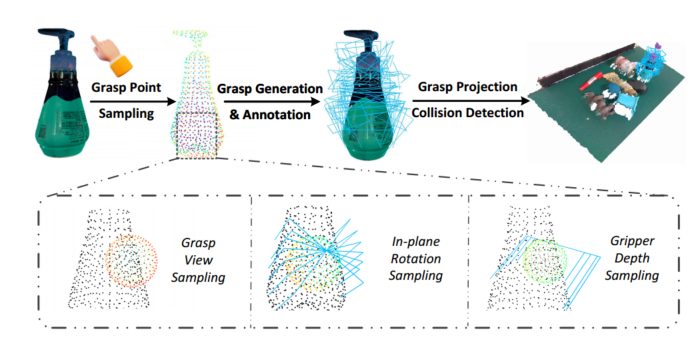
a. 抓取点采样
b. 抓取生成:视角、平面旋转和抓取深度采样
c. 通过物体的6D姿态投影场景中得到抓取姿态
d 碰撞检测
评价指标
Precision@k:前k个抓取的精度
网络
输入:点云
输出:抓取姿态
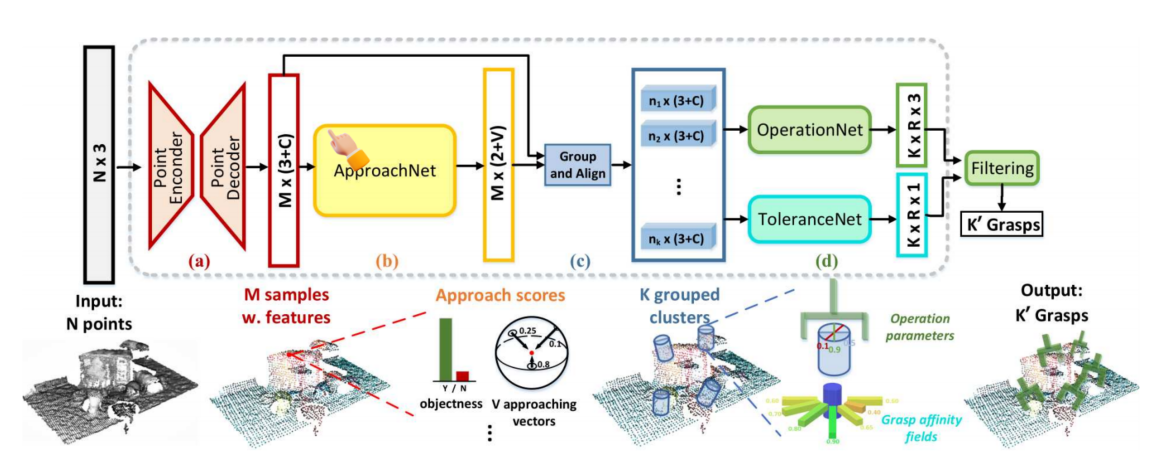
pointnet++:
最远点采样算法, 点云分类
Approach Network:
输出能否抓取和预先定义的接近向量数量
Operation Network:
圆柱区域变换
旋转和宽度:分类比回归效果更好
Tolerance Network
grasp affinity fields:增加扰动还是有效的
摘要
物体抓取在许多应用中都是至关重要的,也是一个具有挑战性的计算机视觉问题。然而,对于复杂的场景,目前的研究存在训练数据不足和缺乏评估基准的问题。在这项工作中,我们提供了一个具有统一评估系统的大规模抓取姿势检测数据集。我们的数据集包含97280个RGB-D图像,超过10亿个抓取姿势。同时,我们的评估系统通过分析计算直接报告抓取是否成功,这能够评估任何种类的抓取姿势,而无需详尽地标记真值。 此外,本文还提出了一种基于点云输入的端到端抓取姿态预测网络,通过解耦的方式学习机器人的接近方向和操作参数,并设计了一种新的抓取亲和度场来提高抓取鲁棒性。实验结果表明,本文的数据集和评估系统能够很好地与真实世界的实验结果相吻合,网络的性能达到了最先进的水平。 我们的数据集、源代码和模型可在www.graspnet.net上公开获取。
相关工作
基于深度学习的抓取预测算法
抓取数据集
点云深度学习
这篇关于GraspNet-1Billion 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)