本文主要是介绍基于__torch_dispatch__机制的dump方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于__torch_dispatch__机制的dump方法
- 1.参考链接
- 2.原理
- 3.代码
- 4.效果
之前拦截torch和torch.Tensor的办法,在处理backward时,不能看到aten算子的细节.以下基于__torch_dispatch__机制的方案更节约代码,且能看到调用栈
1.参考链接
[原理] (https://dev-discuss.pytorch.org/t/what-and-why-is-torch-dispatch/557)
2.原理
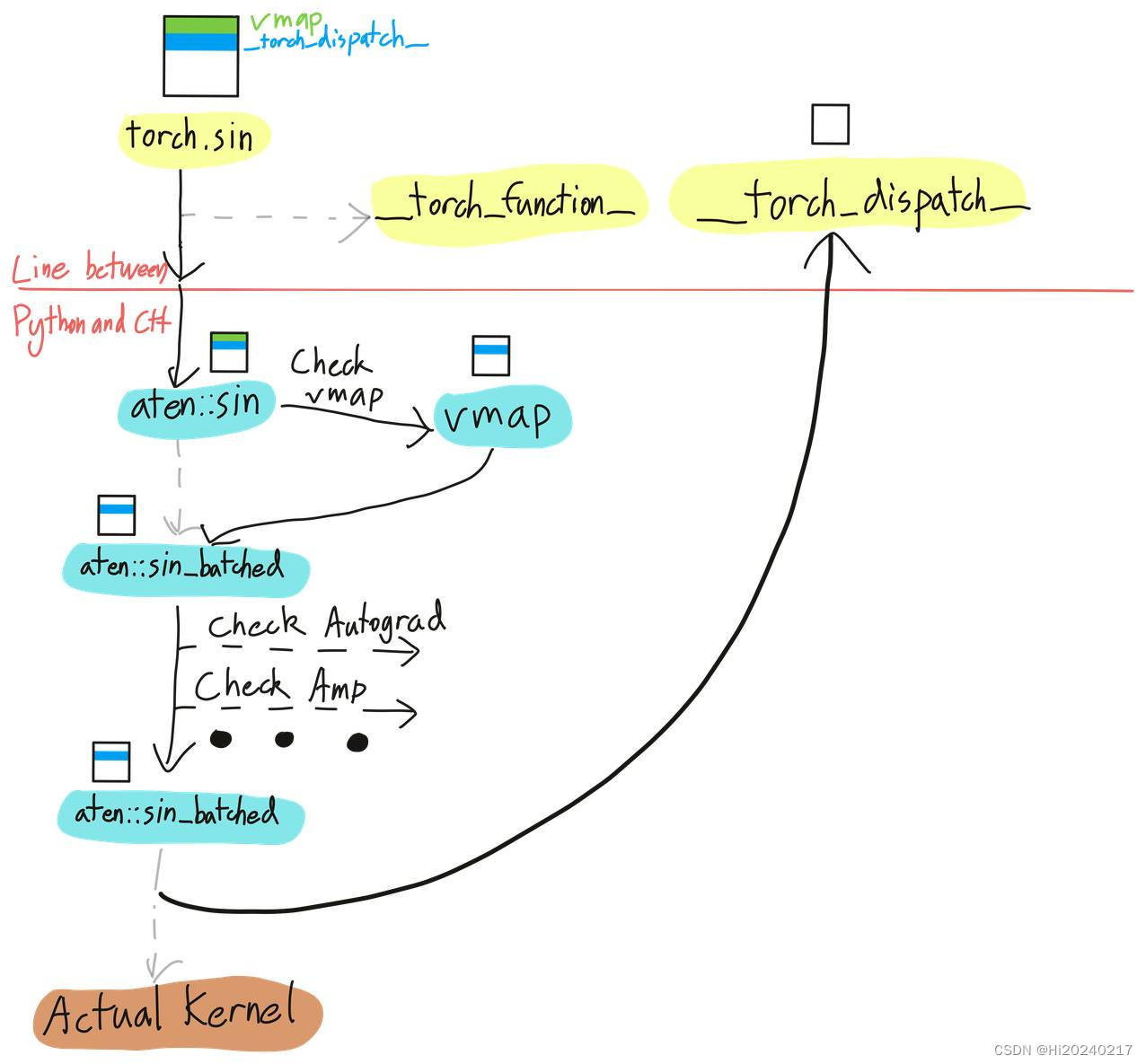
3.代码
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
import torch
from torch import nn
import math
import torch.nn.functional as F
from torch.autograd import Variable
import time
import os
import threadingdevice="cuda"
from torch.utils._python_dispatch import TorchDispatchMode
import inspect
import traceback
from dataclasses import dataclass
from typing import Any@dataclass
class _ProfilerState:cls: Anyobject: Any = Nonelock=threading.Lock()
gindex=0
def save_tensor(name,args,index=0):if isinstance(args,torch.Tensor):print(name,index,args.shape)global gindexlock.acquire()torch.save(args,"{}_{}_{}_{}.pt".format(device,gindex,name,index))gindex+=1lock.release()if isinstance(args,tuple):for idx,x in enumerate(args):save_tensor(name,x,index+idx)class TorchDumpDispatchMode(TorchDispatchMode):def __init__(self,parent):super().__init__()self.parent=parentdef __torch_dispatch__(self, func, types, args=(), kwargs=None):func_packet = func._overloadpacket if kwargs is None:kwargs = {} enable_dump=Falseif func_packet.__name__ not in ["detach"]:enable_dump=Trueprint(f"Profiling {func_packet.__name__}") for idx,stack in enumerate(inspect.stack()):print(f'{"*"*idx}{stack.filename}{stack.lineno}')if enable_dump: save_tensor(f"{func_packet.__name__}-input",args)ret= func(*args, **kwargs)if enable_dump:save_tensor(f"{func_packet.__name__}-output",ret)return retclass TorchDumper:_CURRENT_Dumper = Nonedef __init__(self,schedule: Any):self.p= _ProfilerState(schedule) def __enter__(self):assert TorchDumper._CURRENT_Dumper is NoneTorchDumper._CURRENT_Dumper = selfif self.p.object is None:o = self.p.cls(self)o.__enter__()self.p.object = oelse:self.p.object.step()return selfdef __exit__(self, exc_type, exc_val, exc_tb):TorchDumper._CURRENT_Dumper = Noneif self.p.object is not None:self.p.object.__exit__(exc_type, exc_val, exc_tb)class Attention(nn.Module):def __init__(self,max_seq_len,head_dim,flash):super().__init__()self.flash = flashself.dropout=0self.attn_dropout = nn.Dropout(self.dropout)self.head_dim=head_dimif not self.flash:print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")mask = torch.full((1, 1, max_seq_len, max_seq_len), float("-inf")).to(device)mask = torch.triu(mask, diagonal=1).half().to(device)self.register_buffer("mask", mask) def forward(self,xq: torch.Tensor,xk: torch.Tensor,xv: torch.Tensor):if self.flash:output = torch.nn.functional.scaled_dot_product_attention(xq, xk, xv,attn_mask=None, dropout_p=self.dropout if self.training else 0.0, is_causal=True)else:_xk=xk.clone()t=_xk.transpose(2, 3)scores = torch.matmul(xq,t)scores = scores/math.sqrt(self.head_dim)a=self.mask[:, :, :seqlen, :seqlen]scores = scores+ascores = F.softmax(scores.float(), dim=-1)scores = scores.type_as(xq)scores = self.attn_dropout(scores)output = torch.matmul(scores, xv) return outputdef main(flash,bs, n_local_heads, seqlen, head_dim):torch.random.manual_seed(1)q = torch.ones((bs, n_local_heads, seqlen, head_dim),dtype=torch.float32).half().to(device)k = torch.ones((bs, n_local_heads, seqlen, head_dim),dtype=torch.float32).half().to(device)v = torch.ones((bs, n_local_heads, seqlen, head_dim),dtype=torch.float32).half().to(device)q.data.normal_(0, 0.1)k.data.normal_(0, 0.1)v.data.normal_(0, 0.1)q=Variable(q, requires_grad=True).to(device)k=Variable(k, requires_grad=True).to(device)v=Variable(v, requires_grad=True).to(device)gt= torch.randint(0,head_dim,(bs*n_local_heads*seqlen,1)).reshape(-1).to(device)loss_func=nn.CrossEntropyLoss().to(device)model=Attention(seqlen,head_dim,flash).half().to(device)optim = torch.optim.SGD([q,k,v], lr=1.1)with TorchDumper(TorchDumpDispatchMode):for i in range(1):output = model(q,k,v)loss=loss_func(output.reshape(-1,head_dim),gt)loss.backward() optim.step()print("{:.5f},{:.5f},{:.5f},{:.5f}".format(q.sum().item(),k.sum().item(),v.sum().item(),loss.item()))bs, n_local_heads, seqlen, head_dim = 8, 8, 512, 64
main(False,bs, n_local_heads, seqlen, head_dim)
4.效果
Profiling clone
/home/user/proj/attention/attention_torch_dispatch_dumper.py60
*/home/user/proj/attention/attention_torch_dispatch_dumper.py109
**/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1527
***/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1518
****/home/user/proj/attention/attention_torch_dispatch_dumper.py144
*****/home/user/proj/attention/attention_torch_dispatch_dumper.py151
clone-input 0 torch.Size([8, 8, 512, 64])
clone-output 0 torch.Size([8, 8, 512, 64])
Profiling transpose
/home/user/proj/attention/attention_torch_dispatch_dumper.py60
*/home/user/proj/attention/attention_torch_dispatch_dumper.py110
**/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1527
***/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1518
****/home/user/proj/attention/attention_torch_dispatch_dumper.py144
*****/home/user/proj/attention/attention_torch_dispatch_dumper.py151
transpose-input 0 torch.Size([8, 8, 512, 64])
transpose-output 0 torch.Size([8, 8, 512, 64])
Profiling expand
/home/user/proj/attention/attention_torch_dispatch_dumper.py60
*/home/user/proj/attention/attention_torch_dispatch_dumper.py111
**/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1527
***/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1518
****/home/user/proj/attention/attention_torch_dispatch_dumper.py144
*****/home/user/proj/attention/attention_torch_dispatch_dumper.py151
expand-input 0 torch.Size([8, 8, 512, 64])
expand-output 0 torch.Size([8, 8, 512, 64])
Profiling view
/home/user/proj/attention/attention_torch_dispatch_dumper.py60
*/home/user/proj/attention/attention_torch_dispatch_dumper.py111
**/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1527
***/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1518
****/home/user/proj/attention/attention_torch_dispatch_dumper.py144
*****/home/user/proj/attention/attention_torch_dispatch_dumper.py151
view-input 0 torch.Size([8, 8, 512, 64])
view-output 0 torch.Size([8, 8, 512, 64])
Profiling expand
/home/user/proj/attention/attention_torch_dispatch_dumper.py60
*/home/user/proj/attention/attention_torch_dispatch_dumper.py111
**/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1527
***/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1518
****/home/user/proj/attention/attention_torch_dispatch_dumper.py144
*****/home/user/proj/attention/attention_torch_dispatch_dumper.py151
expand-input 0 torch.Size([8, 8, 64, 512])
expand-output 0 torch.Size([8, 8, 64, 512])
Profiling view
/home/user/proj/attention/attention_torch_dispatch_dumper.py60
*/home/user/proj/attention/attention_torch_dispatch_dumper.py111
**/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1527
***/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1518
****/home/user/proj/attention/attention_torch_dispatch_dumper.py144
*****/home/user/proj/attention/attention_torch_dispatch_dumper.py151
view-input 0 torch.Size([8, 8, 64, 512])
view-output 0 torch.Size([8, 8, 64, 512])
Profiling bmm
/home/user/proj/attention/attention_torch_dispatch_dumper.py60
*/home/user/proj/attention/attention_torch_dispatch_dumper.py111
**/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1527
***/home/anaconda3/envs/nvidia_training/lib/python3.10/site-packages/torch/nn/modules/module.py1518
****/home/user/proj/attention/attention_torch_dispatch_dumper.py144
*****/home/user/proj/attention/attention_torch_dispatch_dumper.py151
bmm-input 0 torch.Size([64, 512, 64])
bmm-input 1 torch.Size([64, 64, 512])
bmm-output 0 torch.Size([64, 512, 64])
bmm-output 1 torch.Size([64, 64, 512])
Profiling _unsafe_view
这篇关于基于__torch_dispatch__机制的dump方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





