本文主要是介绍PHP与MySQL程序设计 学习笔记 第九章 字符串和正则表达式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
php支持两种正则表达式实现,分别为Perl正则表达式和POSIX正则表达式实现。但POSIX版本在php 5.3.0中被废弃。
POSIX表示UNIX的可移植操作系统接口(Portable Operating System Interface for UNIX),最初是针对基于UNIX的一组标准。POSIX正则表达式语法目的是让各种编程语言中的正则表达式标准化。
最简单的正则表达式是只匹配一个字符的表达式,如g,能匹配所有带g的字符串。
可通过管道操作符|同时匹配多个正则表达式,如php|zend可匹配含php或zend的字符串。
POSIX正则表达式支持的符号:
1.中括号:用来表述要匹配的一定范围内的字符列表,如[php]将找到所有包含p或h的字符串。以下为常用的字符范围表示:
(1)[0~9]匹配任何从0到9的十进制数字。
(2)[a~z]匹配任何从小写a到z的字符。
(3)[A~Z]匹配任何从大写A到Z的字符。
(4)[A~Za~z]匹配任何从大写A到小写z的字符。
也可使用[0~3]来匹配从0到3内的任何数字,可指定任意的ASCII范围。
2.量词:如想找到包含特定个数某字符的串:
(1)p+:匹配任何至少包含一个p的字符串。
(2)p*:匹配任何包含零个或多个p的字符串。
(3)p?:匹配任何包含零个或一个p的字符串。
(4)p{2}:匹配任何包含两个连续p的字符串。
(5)p{2,3}:匹配任何包含两个或三个连续p的字符串。
(6)p{2,}:匹配任何至少包含两个连续p的字符串。
(7)p$:匹配任何以p结尾的字符串。
(8)^p:匹配任何以p开头的字符串。
(9)[^a-zA-Z]:匹配任何不包含从a~z和从A~Z的字符串。
(10)p.p:匹配任何包含p、接下来是任何字符、再接下来又是p的字符串。
(11)^.{2}$:匹配任何只包含两个字符的字符串。
(12)<b>(.*)</b>:匹配任何以<b>和</b>为头尾的字符串。
(13)p(hp)*:匹配任何包含一个p,p后面是零个或多个hp的字符串。
如果希望在字符串中搜索带以上特殊字符的串,需要在这些字符前加\转义,如([\$])([0-9]+)表示美元符后跟一个或多个整数的字符串。
3.预定义的字符范围:
(1)[:alpha:]:表示小写字母或大写字母。
(2)[:alnum:]:表示小写字母、大写字母、数字。等同于[A-Za-z0-9]。
(3)[:cntrl:]:表示控制字符,如制表符、退格符、反斜线。
(4)[:digit:]:表示数字。
(5)[:graph:]:表示ASCII码为33~126范围内的可打印字符。
(6)[:lower:]:表示小写字母。
(7)[:punct:]:表示标点符号字符。
(8)[:upper:]:表示大写字母字符。
(9)[:space:]:表示空白字符,包括空格、水平制表符、换行、换页、回车。
(10)[:xdigit:]:表示十六进制字符。相当于[a-fA-F0-9]。
php POSIX正则表达式函数(php 5.3.0中被废弃,需用之前版本测试):
1.以区分大小写方式搜索字符串,如找到返回匹配字符串的长度,否则返回false:

确定用户名是否只包含小写字母:
$userName = "jasoN";if (ereg("([^a-z])", $userName)) {print("user name must be all lowercase"); // 会被输出
} else {print("user name is all lowercase");
}
可选参数regs可将结果分割成多个部分,分割的界限为正则表达式中的括号:

2.不区分大小写地搜索字符串:

用户必须使用8-10个字母数字组成的密码:

3.以区分大小写的方式替换文本,它会用replacement串代替string中的pattern:

将URL改为超链接:

运行它:

上例中,替换串replacement中的\0表示整个字符串,\1表示第一个子串,最多可以用9个反引用。
在不需要复杂的正则表达式时,可用str_replace函数代替,它的速度更快。
4.以不区分大小写的方式替换文本:

5.以区分大小写的方式将字符串划分,划分的边界为模式串:

可选参数limit指定串最多可被划分为多少个元素。
使用该函数将字符串根据水平制表符和换行符分成几个部分:
$text = "this is\tsome test that\nwe might like to parse.";print_r(split("[\n\t]", $test));
运行它:

6.以不区分大小写的方式将字符串划分为不同元素:

7. 将当前正则表达式转换为不区分大小写匹配的正则表达式:

echo sql_regcase("Foo - bar.");
运行它:

可见非字母符号不会变。
Perl的正则表达式语法就是POSIX实现派生的,可用POSIX中的所有量词。
以下为Perl风格正则表达式语法:
1.修饰符:

这些修饰符可直接放在正则表达式的后面,如/wmd/i可不区分大小写匹配wmd串;/taxation/gi不区分大小写地找出所有该单词。
2.元字符:
(1)\A:只匹配字符串的开头。
(2)\b:匹配串边界。
(3)\B:不匹配串边界。
(4)\d:匹配数字字符。
(5)\D:匹配非数字字符。
(6)\s:匹配空白字符。
(7)\S:匹配非空白字符。
(8)[]:包围一个字符集合。
(9)():包围一个字符分组或定义一个反引用。
(10)$:匹配行尾。
(11)^:匹配行首。
(12).:匹配除换行外所有字符。
(13)\:转义元字符。
(14)\w:匹配任何只包含下划线和字母数字字符的字符串。
(15)\W:匹配任何不含下划线、字母、数字的字符串。
如\sa/b\可匹配pisa、lisa这种后边界带sa的但不会匹配前边界带sa的sand;而/sa\B/能匹配含sa但不以sa结尾的字符串,如sand、fff f sally但不能匹配melissa;/\$\d+/g表示返回所有的含一个美元符且美元符后面跟一个或多个数字的串。
3.Perl兼容的正则表达式函数:
(1)preg_grep():搜索数组中所有元素,返回与参数pattern表示的模式匹配的所有元素组成的数组:

找到以p开头的单词:
print_r(preg_grep("/^p/", ["pasta", "steak", "fish", "potatoes"]));
运行它:

可选参数flags可取PREG_GREP_INVERT,表示取不符合模式串的串:
print_r(preg_grep("/^p/", ["pasta", "steak", "fish", "potatoes"], PREG_GREP_INVERT));
运行它:

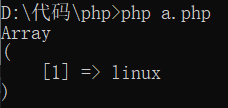
如果匹配以某个词开头和结尾的,相当于只匹配这个单独的词:
$pattern = "/\blinux\b/i";print_r(preg_grep($pattern, ["linuxlinux", "linux"]));
运行它:
(2)preg_match函数根据模式搜索字符串,如串中能匹配到模式则返回true,否则返回false:

可选的参数matches可获取所搜索模式中的子模式(如果存在)。
完成不区分大小写的搜索操作:
$line = "vim is the greatest word peocessor ever created! Oh vim, how I love thee!";
$match = null;
if (preg_match("/\bV(i)(m)\b/i", $line, $match)) print("Match found!\n");
print_r($match);
运行它:

它会匹配开头的vim。如果开头的单词不是vim,则会匹配Oh后边的vim。
可选参数flags可被设置为以下值的组合,使用按位或运算符|组合:
①PREG_OFFSET_CAPTURE:对于每一个出现的匹配子组返回时会附加子组字符串相对于整个被匹配的字符串的偏移量(字节数,第一个字节的偏移量为0),这会改变结果参数matches的结构:
preg_match('/(foo)(bar)(baz)/', 'afoobarbaz', $matches, PREG_OFFSET_CAPTURE);
print_r($matches);
运行它:

②PREG_UNMATCHED_AS_NULL:未匹配的子组会报告为NULL,未使用该flag时,未匹配的子组报告为空string:
preg_match('/(a)(b)*(c)/', 'ac', $matches); // 此处的第二个子组为b而非b*,如果要搜索的串为abbc,则第二个子串为b,如果子组为b*,则此时第二个子串为bb
var_dump($matches);
preg_match('/(a)(b)*(c)/', 'ac', $matches, PREG_UNMATCHED_AS_NULL);
var_dump($matches);
运行它:

可选参数offset用于指定从目标字符串的某个位置开始搜索(以字节为单位):
$subject = "abcdef";
$pattern = '/def/';
preg_match($pattern, $subject, $matches, PREG_OFFSET_CAPTURE, 3);
print_r($matches);
运行它:

如果模式串是以def开头,而开始匹配的偏移也以def开头,但偏移处的def不是单词的开头时,匹配会失败:
$subject = "abcdef";
$pattern = '/^def/';
preg_match($pattern, $subject, $matches, PREG_OFFSET_CAPTURE, 3);
print_r($matches);
运行它:

(3)preg_match_all函数匹配字符串中出现的所有模式,返回值为匹配到的串数:

可选flags参数值,可用按位或运算符|组合使用:
①PREG_PATTERN_ORDER:该值是没有定义可选参数flags时的默认值。它使参数matches的返回值中下标为0的元素为所有匹配到的串组成的数组,下标为1的元素为所有匹配到的串的第一个子组组成的数组:
$text = "Abc abCd aaBc";
$matches = null;
print(preg_match_all("/(a)(bc)/i", $text, $matches, PREG_PATTERN_ORDER) . "\n");
print_r($matches);
运行它:
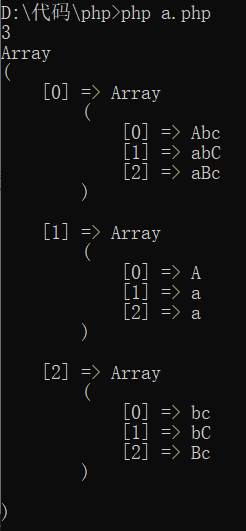
②PREG_SET_ORDER:与①不兼容,会使第一个数组元素为第一个匹配到的串和第一个匹配到的串的所有子组:
$text = "Abc abCd aaBc";
$matches = null;
print(preg_match_all("/(a)(bc)/i", $text, $matches, PREG_SET_ORDER) . "\n");
print_r($matches);
运行它:

③PREG_OFFSET_CAPTURE:参数matches中会包含匹配到的串相对于整个被匹配串(参数string)的偏移量,string中的第一个字符的偏移量为0:
$text = "abc abcd aabc";
$matches = null;
print(preg_match_all("/(a)(bc)/", $text, $matches, PREG_OFFSET_CAPTURE) . "\n");
var_dump($matches);
运行它:

可选参数offset可指定搜索的起点:
$text = "abc abcd aabc";
$matches = null;
print(preg_match_all("/(a)(bc)/", $text, $matches, PREG_SET_ORDER, 3) . "\n");
运行它:

④preg_quote函数在每个对于正则表达式语法而言有特殊含义的字符前插入一个反斜线,特殊字符包括:.、\、+、*、?、[、^、]、$、(、)、{、}、=、!、<、>、|、:、-、#(php 7.3.0新增)。(注意/不是正则表达式特殊字符)
函数形式为:

print(preg_quote('$a.'));
运行它:

可选参数delimiter可将该字符也当作特殊字符,这样也会给delimiter前加上\,如果delimiter参数字符串长度大于1,则只有第一个字符有效:
print(preg_quote('$bax.', 'xba'));
运行它:

⑤preg_replace函数可将匹配到的串替换为指定串:

pattern和replacement参数都是mixed的,这两个参数既可以提供字符串,也可以提供数组。
print(preg_replace("/ /", "x", "a b c"));
运行它:

模式串和替换串也可以是array:
print(preg_replace(array("/a/", "/b/"), array("x", "y"), "a b c"));
运行它:

如果模式串比替换串多:
$res = preg_replace(array("/a/", "/b/", "/c/"), array("x", "y"), "a b c");
print($res . PHP_EOL);
print(strlen($res));
运行它:
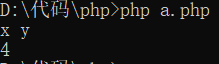
可见多出来的模式串被直接删掉。
如果模式串比替换串少:
print(preg_replace(array("/a/", "/b/"), array("x", "y", "z"), "a b c"));
运行它:

可见多出的替换串没用到。
可选参数limit指明最多发生几次匹配,如未设置或设置为-1,则替换所有匹配的字符串:
print(preg_replace(array("/a/", "/b/"), array("x", "y"), "a b a", 1) . "\n");
print(preg_replace("/ /", "x", "a b c", 1));
运行它:

可见参数limit指定的是每个模式串最多替换多少次。
结果可选参数count指明替换发生了多少次:
print(preg_replace(array("/a/", "/b/"), array("x", "y"), "a b a", 1, $count) . "\n");
print($count);
运行它:

php 5.3.0新增了preg_filter函数,它的操作方式与preg_replace函数相同,但它不修改原串,只返回替换后的串:
$text = "a b a";
print(preg_filter(array("/a/", "/b/"), array("x", "y"), $text, 1, $count) . "\n");
print($count . "\n");
print($text);
运行它:

⑥preg_replace_callback函数可使用自定义函数改变替换字符串的方式:

function func($matches) {print_r($matches);return " " . strtoupper($matches[1]). " ";
}$text = "a b c";
print(preg_replace_callback("/ (.) /", "func", $text));
运行它:

可选参数limit可指定最多进行多少次匹配,如果不设置或将其设置为-1则表示无次数限制:
function func($matches) {static $i = 0;return $i++;
}$text = "a b c";
print(preg_replace_callback("/ /", "func", $text, 1));
运行它:

可选参数count指明匹配发生了多少次:
function func($matches) {static $i = 0;return $i++;
}$text = "a b c";
print(preg_replace_callback("/ /", "func", $text, -1, $count) . "\n");
print($count);
运行它:

⑦preg_split函数不区分大小写将字符串划分为不同元素:

print_r(preg_split("/\++/", "a+b++c")); // 匹配一个或多个+
运行它:

可选参数limit可限制划分次数:
print_r(preg_split("/\++/", "a+b++c", 2));
运行它:

可选参数flags可以是以下值的组合(通过按位或运算|):
a.PREG_SPLIT_NO_EMPTY会忽略分割后长度为0的串:
print_r(preg_split("/\+/", "a++c", -1, PREG_SPLIT_NO_EMPTY));
print_r(preg_split("/\+/", "a++c", -1));
运行它:

b.PREG_SPLIT_DELIM_CAPTURE可将分隔模式串中括起来的部分也返回:
print_r(preg_split("/(\+)\+/", "a++b++c", -1, PREG_SPLIT_DELIM_CAPTURE));
print_r(preg_split("/(\+)\+/", "a++b++c", -1));
运行它:

可见虽然分割模式串是两个加号,但只有一个加号是带括号的,因此只输出带括号的部分。
c.PREG_SPLIT_OFFSET_CAPTURE会将各个分割后的子串首字符相对于参数string的首字符的偏移量也捕获,string的首字符偏移量为0:
print_r(preg_split("/(\+)\+/", "a++b++c", -1, PREG_SPLIT_OFFSET_CAPTURE));
print_r(preg_split("/(\+)\+/", "a++b++c", -1));
运行它:

返回字符串长度的函数:

print(strlen("aa")); // 输出2
以区分大小写的方式对两个字符串进行二进制安全的比较(即将两个字符串看作二进制流,不考虑其格式等因素):

如果两字符串相等则返回0;str1小于str2返回-1;否则返回1:
print(strcmp("aa", "ab") . "\n"); // 输出-1
print(strcmp("ab", "aa")); // 输出1
以不区分大小写的方式比较两个字符串:

返回值规则与strcmp函数相同。
print(strcasecmp("Aa", "aa")); // 返回0
一般电子邮件地址是不分大小写的,可用此函数比较两个电子邮箱是否相同。
strspn函数返回一个字符串的开头部分中包含另一个字符串中字符的长度:
print(strspn("42 is the answer to the 128th question.", "1234567890 i")); // 输出4
测试字符串是否全部由数字组成:
$text = "543253253";
if (strspn($text, "1234567890") == strlen($text)) {print("all characters are numbers"); // 会被输出
}
可选参数start指明查找的起始位置,0表示从头开始查找:
print(strspn("432", "0123456789", 1)); // 输出2
可选参数length指明参与比较的str1的长度:
print(strspn("4321", "0123456789", 1, 2)); // 输出2
strcspn函数与strspn相反,查找str1的开头不在str2中的长度:

$text = "a55555";
if (strcspn($text, "0123456789") != strlen($text)) { // 1 != 6print("str1 can't contain numbers"); // 会被输出
}
将字符串全部转换为小写,原字符不会变,返回修改后的字符串,非字母字符不受影响:

将字符串全部转换为大写,原字符不会变,返回修改后的字符串,非字母字符不受影响:

将字符串的第一个字符大写,原字符不会变,返回修改后的字符串,第一个字符为非字母字符时,返回原串:

将字符串中的每个单词(单词的两侧都有空白符)的第一个字符大写,首字符非字母的单词不受影响,原串不会变,返回修改后的字符串:

将字符串中的所有换行符(\n)转换为<br />:

$text = "abcd";
print(nl2br($text));
运行它:

通信过程中,可能会遇到文档的文本编码不包括的特殊字符或键盘上无法输入的字符,如版权符号©、法语重音符号等,为了克服这些困难,设计了一组统一的按键编码,称为字符实体引用,浏览器解析这些实体时,会将其转换为可识别的形式,如版权符为©、法语重音符号为È。可用以下函数将特殊字符转换为HTML等价形式:

$text = "<\"a'"; // php需要转义字符串中的双引号
print(htmlentities($text));
运行它:

由于标记中引号有特殊意义,可通过可选的quote_style参数选择如何处理引号:
1.ENT_COMPAT:转换双引号,忽略单引号,这是默认值。
2.ENT_NOQUOTES:忽略双引号和单引号。
$text = "<\"a'";
print(htmlentities($text, ENT_NOQUOTES));
运行它:

3.ENT_QUOTES:转换双引号和单引号。
$text = "<\"a'";
print(htmlentities($text, ENT_QUOTES));
运行它:

4.EMT_HTML401:以HTML 4.01处理代码。
5.ENT_XML1:以XML 1处理代码。
6.ENT_XHTML:以XHTML处理代码。
7.ENT_HTML5:以HTML 5处理代码。
可选参数charset确定转换所用的字符集,如果忽略charset参数,php 5.4和5.5使用utf-8作为默认值,在此之前版本使用ISO-8859-1作为默认值,在此版本之后使用php.ini中的default_charset配置作为默认值,此参数的可选值如下:

可选参数double_encode会阻止对字符串中已有的HTML编码再次编码,默认值为true,即会再次编码:
$text = "&"; // &的HTML编码
print(htmlentities($text, ENT_QUOTES, ini_get("default_charset")) . "\n");
print(htmlentities($text, ENT_QUOTES, ini_get("default_charset"), false));
运行它:

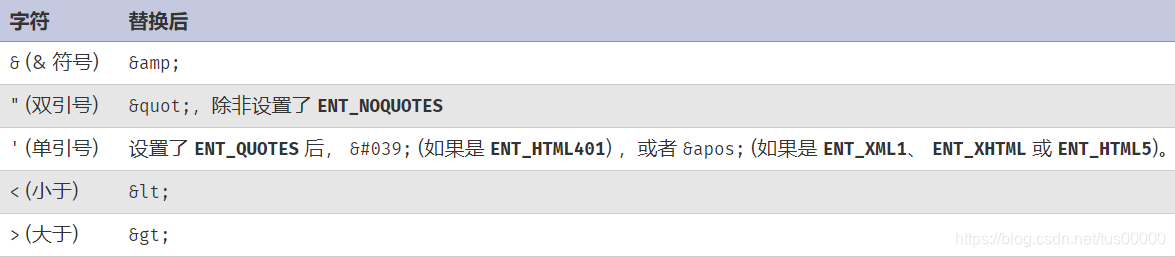
只将以上字符转换为HTML实体的函数:

可选参数及其含义与htmlentities函数中的相同。
返回参数str表示的串中去除了php和html中的标记字符的结果,原串不变:

$text = "<br>aa<br/>";
print(strip_tags($text)); // 输出aa
可选参数allowable_tags为要保留的标记字符,php 5.3.4之后,为了保留<br>和<br/>,只需填写<br>:
$text = "<br>aa<br/>";
print(strip_tags($text, '<br>')); // 会输出原串
返回字符与其对应HTML实体的转换表:

table参数可以是HTML_SPECIALCHARS或HTML_ENTITIES。
print_r(get_html_translation_table(HTML_SPECIALCHARS));
运行它:

将字符串参数str中的字符转换为参数replacements表示的数组中以该字符为键的值并返回,原串不变:

$text = "&a&";
$specialCharsTable = get_html_translation_table(HTML_SPECIALCHARS);$text = strtr($text, $specialCharsTable);
print($text . "\n");$specialCharsTable = array_flip($specialCharsTable); // 此函数交换每个元素的键值对并返回,原数组不变
print(strtr($text, $specialCharsTable));
运行它:

可用以下函数替代正则表达式函数时,不要用正则表达式,正则表达式解析慢。
根据参数tokens表示的串中的字符将参数str表示的字符串分割:

每次调用该函数只会返回分割的一个部分,str参数只需指定一次,函数会追踪参数str中的位置,直到完成了str参数的词法分析或重新指定了str参数:
$text = "a,b.c|d";
$token = ",.|";$part = strtok($text, $token);
while ($part) { print($part);$part = strtok($token); // 最后一次分割时产生false
}
运行它:

直接将字符串根据分隔符分解为子串组成的数组:

print_r(explode(".", "a,b.c|d")); // 此函数的分隔符被看作一个整体
运行它:

可选函数limit指明最多分为几个子串:
print_r(explode(".", "a.b.c.d", 2));
运行它:

heredoc的结束标识符所在行不能缩进,且该行只能有结束符和分号:
$text = <<< textab
text;
将一个字符串数组中的元素连接拼成新字符串,每个元素以参数delimiter分隔:

$textArr = ["a", "b"];
print(implode(" | ", $textArr));
运行它:

在字符串中以区分大小写的方式找到子串第一次出现的位置:

如果子串不存在,则返回false。
print(strpos("abc", "b")); // 返回1
可选参数offset可指定从哪里开始搜索:
if (strpos("abc", "b", 2) === false) {print("not found"); // 会被输出
}print(strpos("abc", "b", 1)); // 返回1
函数stripos与strpos相似,但它以不区分大小写的方式搜索。
找到最后一次子串出现的位置:

print(strrpos("abcd", "c")); // 输出2
可选参数offset可确定搜索的左界:
print(strrpos("abcde", "bc", 2) === false ? 3 : 4); // 会输出3
print(strrpos("abcde", "bc", 1) === false ? 3 : 4); // 会输出4
一个应用,取大段文字的前100个字符,但要保持最后一个单词的完整,如果最后一个单词不完整,则去掉最后一个词:
$text = <<<text
What distinguishes PHP from something like client-side JavaScript is that the code is executed on the server,
generating HTML which is then sent to the client.
text;print(substr($text, 0, strrpos(substr($text, 0, 100), " ")) . "...");
运行它:

用区分大小写的方式将字符串参数str中的参数occurrence表示的串替换为参数replacement表示的串,原串保持不变:

可选参数count指明替换发生了多少次:
print(str_replace(" ", "+", "a b c", $count)); // 输出a+b+c
print($count); // 输出2
函数str_ireplace作用与str_replace函数相似,但它执行不区分大小写的搜索。
返回字符串中从参数occurrence表示的串开始之后的串(返回串中含occurrence参数表示的串):

print(strstr("a b c", " ")); // 返回" b c"
可选参数before_needle为true时会返回参数occurrence表示的串之前的串:
print(strstr("a b c", " ", true)); // 返回"a"
返回特定偏移区间内的子串:

print(substr("abcd", 2)); // 返回cd
可选参数length可指定返回的子串长度:
print(substr("abcd", 2, 1)); // 返回c
参数组合:
1.start > 0,子串从start开始。
2.start < 0,子串从strlen(str) + start位置开始:
print(substr("abcd", -2)); // 返回cd
3.length > 0,返回此长度的子串,如果超出了字符串末尾,则只返回末尾前的部分。
4.length < 0,子串会从末尾的length个字符除结束:
print(substr("abcd", -3, -1)); // 返回bc,左闭右开
找出子串出现的次数:

print(substr_count("abcabc", "ab")); // 返回2
可选参数offset指明开始搜索的起点:
print(substr_count("abcabc", "ab", 1)); // 返回1
可选参数length指明要搜索的串长度:
print(substr_count("abcabc", "ab", 1, 3)); // 返回0
将字符串中的一部分替换为另一个串:

从参数start处开始将str参数中的串替换为指定串:
print(substr_replace("abcd", "23", 1));
运行它:

可选参数length指明要替换的原串的字符的长度:
print(substr_replace("abcd", "23", 1, 1) . "\n");
print(substr_replace("abcd", "23", 1, 2) . "\n");
print(substr_replace("abcd", "23", 1, 3));
运行它:

start和length参数可正可负:
1.start > 0,从下标为start处开始替换。
2.start < 0,从下标为strlen(str) + start处开始替换。
3.length > 0,替换length个字符。
4.length < 0,替换将在下标strlen(str) + start处替换结束(不含尾元素):
print(substr_replace("abcd", "23", 1, -1));
运行它:

将字符串开头部分的空白字符去掉,空白字符包括空格符、水平制表符\t、换行\n、回车\r、空值\0、垂直制表符\x0b:

可选参数charlist指定要删除的字符集合,此字符集合替换了默认的空白字符集合:
print(ltrim(" :abcd", " :a")); // 输出bcd,charlist中的空格不能省略,否则会输出原串
删除字符串参数str尾部的空白字符:

删除字符串参数str两端的空白字符:

填充字符串参数str,直到其长度等于length参数:

如果不指定可选参数pad_string,则用空格符填充串。如果不指定可选参数pad_type,则默认将字符串填充在右侧,它可取的值有STR_PAD_RIGHT(默认值,右端填充)、STR_PAD_LEFT(左端填充)、STR_PAD_BOTH(两端填充)。
print(str_pad("a", 6, "+=", STR_PAD_BOTH) . "\n");
print(str_pad("a", 7, "+=", STR_PAD_BOTH));
运行它:

统计字符串参数str中的字符个数:

print_r(count_chars("12abcdefab"));
运行它:

它返回了以字符的ASCII码为键,出现次数为值的数组。
可选参数mode指定返回行为:
1.0:默认值,返回以字符的ASCII码为键,出现次数为值的数组。
2.1:返回数组中只含频率大于0的键值对。
3.2:返回数组中只含频率等于0的键值对。
4.3:返回包含所有出现过的字符的集合的字符串。
5.4:返回包含所有未出现过的字符的集合的字符串。
返回字符串中每个字符出现的频率:
$sentense = "Hello world!";
foreach (count_chars($sentense, 1) as $char => $times) {print(chr($char) . "occurs $times times\n");
}
运行它:

上例中chr函数将数字转换为ASCII码值对应的字符,这与ord函数是互补的,ord函数会将字符转换为字符对应的ASCII码。
统计字符串中的单词总数:

$sentense = "Hello world!";
print(str_word_count($sentense)); // 返回2
可选参数format改变函数的返回值:
1.1:返回str参数中单词组成的数组:
$sentense = "Hello world! Hello";
print_r(str_word_count($sentense, 1));
运行它:

2.2:返回以单词的偏移量为键值,单词为值的数组:
$sentense = "Hello world! Hello";
print_r(str_word_count($sentense, 2));
运行它:

该函数可与array_count_values函数一起使用统计单词出现的频率,array_count_values函数可返回数组中相同值出现的频率:
$sentense = "Hello world! Hello";
print_r(array_count_values(str_word_count($sentense, 2)));
运行它:

这篇关于PHP与MySQL程序设计 学习笔记 第九章 字符串和正则表达式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[Linux深度学习笔记5.9]](https://img-blog.csdnimg.cn/direct/34a048ce5f8a478bb4997f2046efbe56.jpeg)