本文主要是介绍【目标跟踪】ByteTrack详解与代码细节,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、前言
- 二、代码详解
- 2.1、新起航迹
- 2.2、预测
- 2.3、匹配
- 2.4、结果发布
- 2.5、总结
- 三、流程图
- 四、部署
一、前言
论文地址:https://arxiv.org/pdf/2110.06864.pdf
git地址:https://github.com/ifzhang/ByteTrack
ByteTrack 在是在 2021 年 10 月公开发布的,在 ECCV 2022 中获奖。它以一种简单的设计方式击败了当时各路“魔改”跟踪器,在 MOT17 数据上首次突破了80 MOTA,并且在单张 V100 中推理速度高达 30FPS。 我把 ByteTrack 核心思想概括为:
- 区分高置信度检测框与低置信度检测框,不同置信度检测框采取不同处理方式。
- 保留低置信度检测框,在后续可能会重新确认为 confirm 状态。而不是像传统 MOT 算法选择删除。
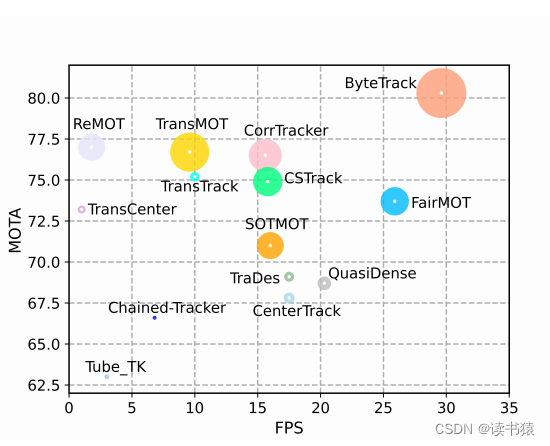
ByteTrack 可以有效解决一些遮挡,且能够保持较低的 IDSwitch。目标会因为被遮挡检测置信度有所降低,当重新出现时,置信度会有所升高。可以想象:
- 当目标逐渐被遮挡时,跟踪目标与低置信度检测目标匹配。
- 当目标遮挡逐渐重现时,跟踪目标与高置信度检测目标匹配。
另外,要慎重考虑并处理检测的假阳性,无目标检测出低置信度框的情况。
网上常常把DeepSort 与 ByteTrack 进行比较,关于 ByteTrack 与 DeepSort,他们各有限制,我们需要根据实际情况选用合适的算法。
- ByteTrack:跟踪效果非常依赖检测的效果。如果检测器的效果好,跟踪也会取得不错的效果。
- DeepSort:使用了外观描述符和复杂的匹配算法,可能在某些复杂场景下计算量较大,影响实时性能。
二、代码详解
要真正理解通、理解透,啃源码是必不可少的。也不是说非要看懂源码才可以跑通项目,而是看懂之后可以吹牛,也不是为了非要吹牛,至少你自己也有成就感。废话不多说,直接来!
代码详解这一节有点难度。如果一时理解不了,可以先点赞收藏,后续再慢慢啃。。。
为了方便理解,下面没有完全按照代码顺序分析,而是按照航迹起始到消亡顺序分析。
2.1、新起航迹
这里要区分两个阈值,一个 track_thrash, 一个 high_thrash。 源码中 track_thresh 设定为 0.5。high_thresh 设定为0.6。一般情况下 high_thresh 设定的值要比 track_thresh 大。track_thresh 是为了区分高置信度检测,还是低置信度检测。而 high_thrash 是为了保证是否可以新起始航迹。只有是大于 high_thrash 置信度的检测框才可以新起航迹。新起的航迹中 state = Tracked,只第一帧新起航迹 is_activated = True,否则is_activated = false。
this->state = TrackState::Tracked;if (frame_id == 1){this->is_activated = true;}//this->is_activated = true;this->frame_id = frame_id;this->start_frame = frame_id;
总结:当第一帧时,航迹本身为空时,只有置信度超过 high_thresh 时,才新起始航迹, 此时 state = Tracked,is_activated =
true。后续只有未匹配的且置信度很高(超过 high_thresh )时才新起始航迹,此时 state = Tracked,is_activated = false。
2.2、预测
合并 is_activated = true 与 state = Lost 航迹。合并后进行预测,预测遵循 kalman 滤波预测。
每个新的检测信息都会初始化一个 STrack 对象,此对象是否能新起航迹前文已经明确了。源码中的 tlbr 顺序是个坑顺序并非是top,left,bottom,right。实际上是left,top,right,bottom。刚开始我也理解错了,至今我都未明白为什么用这种顺序命名。
if (objects.boxes.size() > 0){for (int i = 0; i < objects.boxes.size(); i++){std::vector<float> tlbr_; // x1,y1,x2,y2tlbr_.resize(4);tlbr_[0] = objects.boxes[i].x;tlbr_[1] = objects.boxes[i].y;tlbr_[2] = objects.boxes[i].x + objects.boxes[i].w;tlbr_[3] = objects.boxes[i].y + objects.boxes[i].h;float score = objects.boxes[i].score;STrack strack(STrack::tlbr_to_tlwh(tlbr_), score);if (score >= track_thresh){detections.push_back(strack);}else{detections_low.push_back(strack);}}}
tlbr_to_tlwh 会把 x1,y1,x2,y2 转化成 x1,y1,w,h。 新起航迹时,activate 函数中 tlwh_to_xyah ,会把 x1, y1, w, h 转变为 xCenter,yCenter,w / h,h。然后放进 kalman 滤波初始化,初始化其状态与协方差。
void STrack::activate(byte_kalman::KalmanFilter &kalman_filter, int frame_id)
{ 此处省略代码auto mc = this->kalman_filter.initiate(xyah_box); 此处省略代码
}
此时 _motion_mat 为一个 8 * 8 的矩阵。对应运动状态方程为匀速。
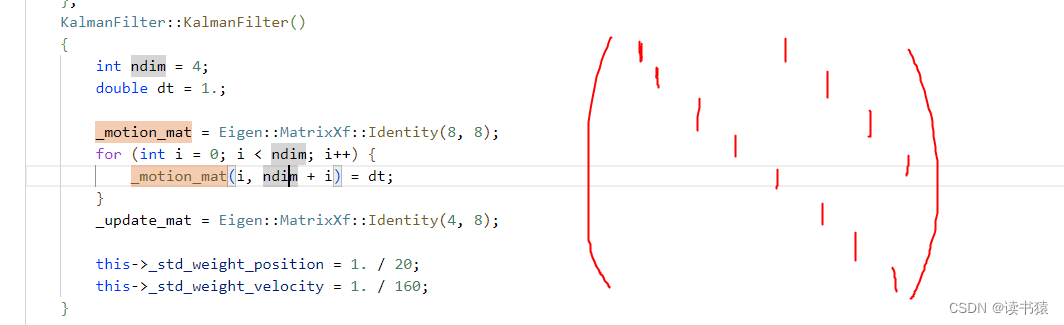
box 状态 mean为:(xCenter,yCenter,w/h,h,Vx,Vy,Vr,Vh)。 预测predict 获得新状态 new_mean = _motion_mat * mean.T
void KalmanFilter::predict(KAL_MEAN &mean, KAL_COVA &covariance){//revise the data;DETECTBOX std_pos;std_pos << _std_weight_position * mean(3),_std_weight_position * mean(3),1e-2,_std_weight_position * mean(3);DETECTBOX std_vel;std_vel << _std_weight_velocity * mean(3),_std_weight_velocity * mean(3),1e-5,_std_weight_velocity * mean(3);KAL_MEAN tmp;tmp.block<1, 4>(0, 0) = std_pos;tmp.block<1, 4>(0, 4) = std_vel;tmp = tmp.array().square();KAL_COVA motion_cov = tmp.asDiagonal();KAL_MEAN mean1 = this->_motion_mat * mean.transpose();KAL_COVA covariance1 = this->_motion_mat * covariance *(_motion_mat.transpose());covariance1 += motion_cov;mean = mean1;covariance = covariance1;}
更新协方差 covariance = _motion_mat * convariance *_motion_mat.T + motion_cov 。
montion_cov为过程噪声矩阵。一般可以保持不变,初始化时可以设定,源码中设定为与 w / h 相关的对角矩阵。
2.3、匹配
这部分是整个论文思想的亮点,也是代码中容易让人混淆的地方。
第一次匹配 预测框与高置信度检测框
- 预测框:2.2中的跟踪预测框。他们state为Tracked或Lost
- 高置信度检测框:置信度大于track_thresh中的检测框,文中track_thresh 设定为0.5。
文中采取了计算 iou 进行匹配,预测框与检测框的交并比。 当预测框匹配上时,此时 state = Tracked, is_activated = true。 匹配上后需要更新框的状态 mean 与协方差 covariance。
kalman中update:
KAL_DATAKalmanFilter::update(const KAL_MEAN &mean,const KAL_COVA &covariance,const DETECTBOX &measurement){KAL_HDATA pa = project(mean, covariance);KAL_HMEAN projected_mean = pa.first; // x,y,r,hKAL_HCOVA projected_cov = pa.second; // _update_mat * covariance * (_update_mat.transpose()) + diagEigen::Matrix<float, 4, 8> B = (covariance * (_update_mat.transpose())).transpose();Eigen::Matrix<float, 8, 4> kalman_gain = (projected_cov.llt().solve(B)).transpose(); // eg.8x4Eigen::Matrix<float, 1, 4> innovation = measurement - projected_mean; //eg.1x4auto tmp = innovation * (kalman_gain.transpose());KAL_MEAN new_mean = (mean.array() + tmp.array()).matrix();KAL_COVA new_covariance = covariance - kalman_gain * projected_cov*(kalman_gain.transpose());return std::make_pair(new_mean, new_covariance);}
首先进入project函数,得到 projected_mean 与 projected_cov。我们先看 project 进行了什么操作。
KAL_HDATA KalmanFilter::project(const KAL_MEAN &mean, const KAL_COVA &covariance){DETECTBOX std;std << _std_weight_position * mean(3), _std_weight_position * mean(3),1e-1, _std_weight_position * mean(3);KAL_HMEAN mean1 = _update_mat * mean.transpose();KAL_HCOVA covariance1 = _update_mat * covariance * (_update_mat.transpose());Eigen::Matrix<float, 4, 4> diag = std.asDiagonal();diag = diag.array().square().matrix();covariance1 += diag;return std::make_pair(mean1, covariance1);}
mean 1*8矩阵(xCenter, yCenter, w/h, h, Vx, Vy, Vr, Vh)
mean1 相当于提取了 mean 中前四个元素。
covariance1 是为了方便后续更新 covariance 一个中间量。
diag 为测量噪声协方差,文中设定与过程噪声矩阵类似。
kalman_gain 为卡尔曼增益,原本需要求 projected_cov 的逆矩阵,再与 B 矩阵相乘求得,这里直接通过解线性方程组的形式求的,省略了一些计算步骤。
new_mean 与 new_covariance 为新的 box 状态与 新的协方差。 预测框与高置信度检测框匹配成功后,无论此时目标 state 为Tracked 还是 Lost,都需更新为 Tracked 状态,且 is_activated 均更新为 true。且都需要进行 kalman 中 update 操作。 一旦目标匹配后:
(1)目标的 state 均变为 Tracked
(2)目标的 is_activated 均变为true
(3)目标的 mean 与 covariance 均需update
第一次未匹配上的预测框与检测框额外缓存。方便后续操作。
第二次匹配 第一次未匹配的预测框与低置信度检测框
- 第一次未匹配的预测框:第一次未匹配上,state为Tracked的预测框。state为Tracked表明该目标为上一帧匹配上的目标
- 低置信度检测框:置信度小于track_thresh中的检测框,文中track_thresh = 0.5。
匹配仍然计算iou匹配。匹配上的目标与第一次匹配类似处理。未匹配上的目标会被标记,state后续可能会被修改为Lost。
第三次匹配 is_activated=false 的跟踪框与第一次未匹配的高置信度检测框
- is_activated=false的跟踪框:上一帧新起的目标,只有上一帧新起的目标is_activate才为false,且此时的框并未做predict处理,也就是说用的上一帧的原始检测框匹配
- 第一次未匹配的高置信度检测框:置信度大于track_thresh,但是第一次未与状态为is_activated跟踪目标匹配。
如果目标匹配上,则(1)state = Tracked(2)is_activated = true(3)mean 与 covariance 均 update。
如果目标未匹配上,此时状态会变为 Removed,此目标会被永久移除。为了要连续两规避偶尔出现某一帧假阳性,至少需帧高置信度的检测才可被 confirm,有机会参与后续计算。
2.4、结果发布
在发布结果前,需要变更BYTETrack类成员变量的值。
- 当 Lost 状态超过 max_time_lost时,state 从 Lost 变为 Removed,此目标被永久遗忘。max_time_lost 构造函数时就已经设定。设定10或者30,根据实际情况调整。
- 当成员 state 从 Lost 变为 Tracked 或 Remove d时,this->lost_stracks 需剔除 id 一致的。
this->lost_stracks = sub_stracks(this->lost_stracks, this->tracked_stracks);
this->lost_stracks = sub_stracks(this->lost_stracks, this->removed_stracks);
remove_duplicate_stracks(resa, resb, this->tracked_stracks, this->lost_stracks); // 移除 重复路径
当有重复路径时,存活帧数一致,航迹相似。也需剔除此lost航迹。 输出结果:只有当 is_activated = true、state=Tracked 时,才会输出目标
2.5、总结
- 检测目标未匹配上时,只有当置信度大于 0.6 才可以新起航迹,其他情况直接被遗忘。此时新起航迹 is_activated 为 false(第一帧不同,第一帧新起航迹 is_activated 默认为 true),当与下一帧置信度大于 0.5 的检测目标在第三次匹配匹配上时(is_activated=false 的目标没资格参与前两次匹配),此时 is_activated 变为 true。此时被标记为 confirm,才有资格被输出。
- 跟踪航迹在匹配中成功匹配,此时无论 state = tracked、is_activated=true。可以参与下一帧匹配中的前两次匹配。如果前两次匹配都未成功,则此时 state = Lost,只能参与下一帧第一次匹配,如果连续 max_time_lost 帧在第一次匹配都未匹配上,此时会被遗忘 Removed,永久移除此航迹。
三、流程图
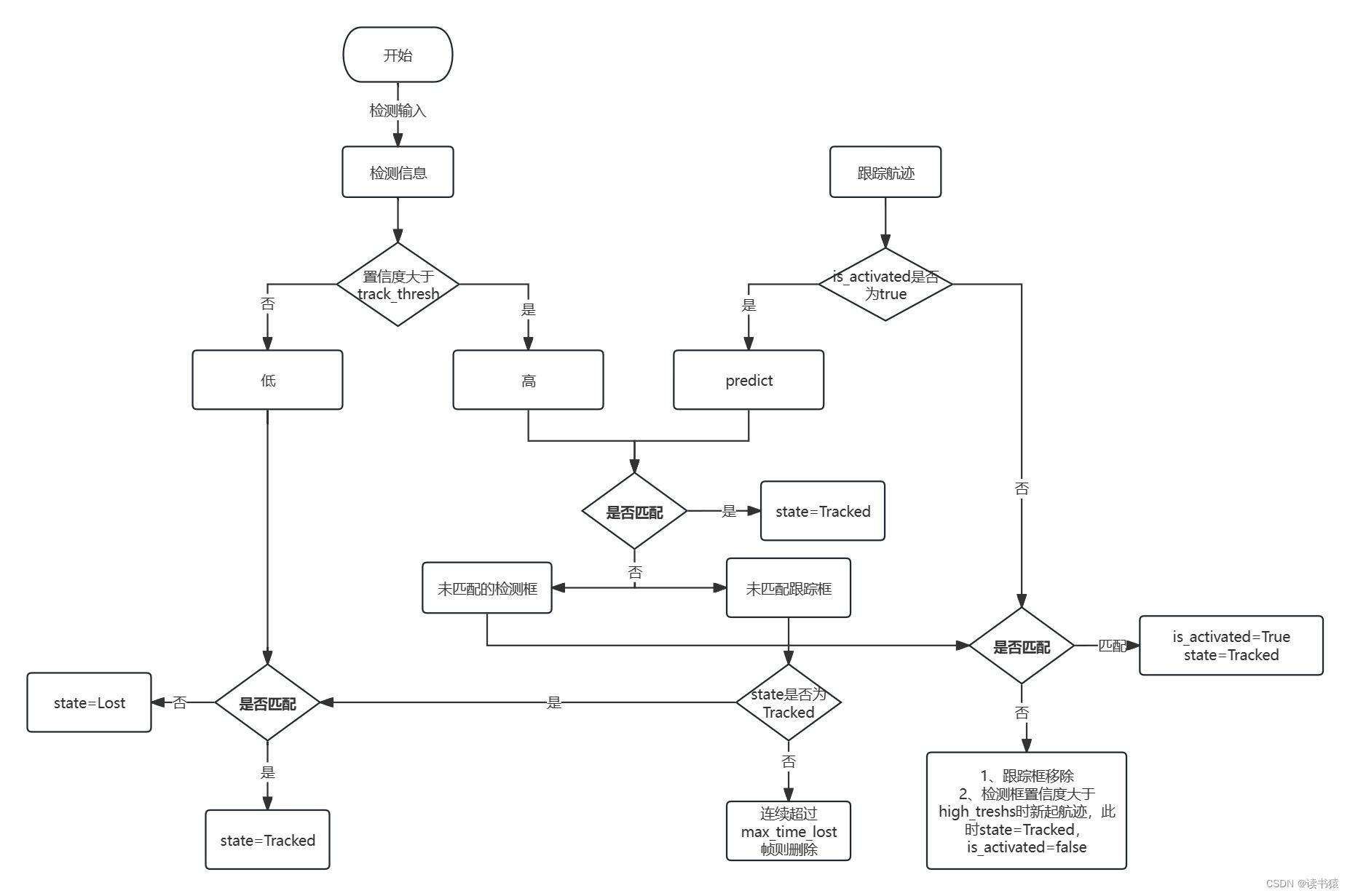
要是看到这里还没看明白,再给你一张我自制的流程图。
四、部署
要是实在看不明白源码,也不想明白,只想在本地跑跑效果看看。那就直接看这里。
环境:linux cmake编译
数据集:https://motchallenge.net/data/MOT17/
git地址:https://github.com/ifzhang/ByteTrack
先 clone 源码下来。链接已给出。c++ 代码在 deploy 文件夹下,博主选用的 ncnn\cpp 文件夹下的代码。下方有 include 与 src 就是全部代码了。
CMakeLists.txt 缺啥链接啥。
mian.cpp 读取 det.txt 文件,保存每一帧的检测结果。给个大概得代码
BYTETracker byteTrack = BYTETracker(10, 30);
for (int fi = 0; fi < maxFrame; fi++) { // maxFrame 帧std::vector<ObjectTrack> trackResult;byteTrack.update(detFrameData[fi], trackResult);
}
trackResult为自己定义的结果
只需对 BYTETracker.cpp 文件引用进去, 把 update 修改为
void BYTETracker::update(const DetectInfo& objects, std::vector<ObjectTrack>& outTracks)
{// 在函数末尾 添加代码for (auto i = 0; i < output_stracks.size(); i++){outTracks.push_back({static_cast<uint>(output_stracks[i].track_id), static_cast<uint>(output_stracks[i].tlbr[0]),static_cast<uint>(output_stracks[i].tlbr[1]),static_cast<uint>(output_stracks[i].tlbr[2]),static_cast<uint>(output_stracks[i].tlbr[3]),output_stracks[i].score });}
}
这时候已经拿到结果了,后续只需在相应的图片可视化相应结果就大功告成了[喝彩.jpg]。机智的你已经行动起来了。
这篇关于【目标跟踪】ByteTrack详解与代码细节的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




