本文主要是介绍octave实现协同过滤推荐算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
octave实现协同过滤推荐算法
标签:推荐算法
这是对关于电影评分的数据集使用协同过滤算法,实现推荐系统。
数据来源为:电影数据
- 先从本地导入数据(代码如下):
% 导入数据
load ('ex8_movies.mat');现在对矩阵可视化看看:
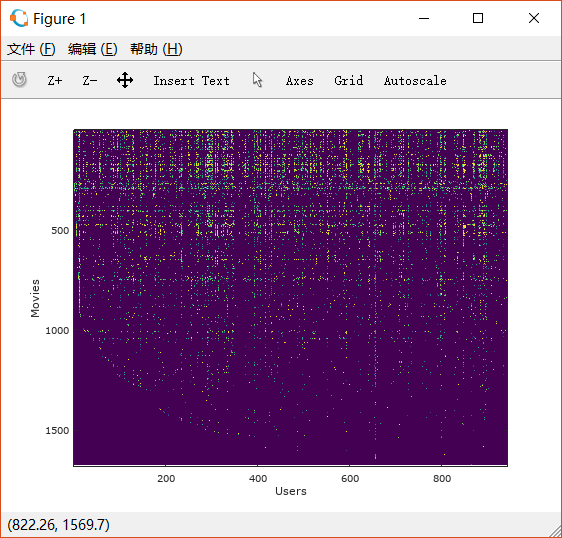
我们可以看出,该图为Y的输出,横轴为用户,纵轴为电影,所以 Y Y 矩阵是
另外对于 R R 矩阵,其
另外代码中常会看到两个矩阵:

X大小为电影数*特征数,第i行代表第i部电影的特征,Theta大小为用户数*特征数,第j行代表第j个用户对应的参数。
4.现在开始求代价函数
代码如下:
J = 1/2 * (sum(sum(R .* (((X * Theta') - Y).^2) ))) ;
%正则化
J = J + lambda/2 * (sum(sum(X.^2))) + lambda/2 * (sum(sum(Theta.^2))) ;%梯度下降
X_grad = (R .* (X * Theta' - Y)) * Theta ;
X_grad = X_grad + lambda * X ;Theta_grad = (R .* (X * Theta' - Y))' * X ;
Theta_grad = Theta_grad + lambda * Theta ;其中,经过正则化的公式为:
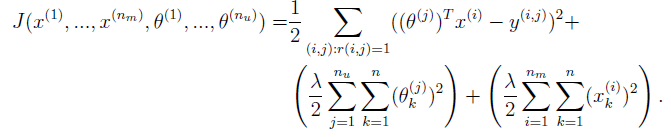
我们更新参数公式中,损失函数梯度(这里没打出正则化,代码里正则化了)为:
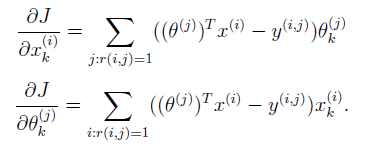
调用为:
%% ========= Part 4: Collaborative Filtering Cost Regularization ========
% Now, you should implement regularization for the cost function for
% collaborative filtering. You can implement it by adding the cost of
% regularization to the original cost computation.
% % Evaluate cost function
J = cofiCostFunc([X(:) ; Theta(:)], Y, R, num_users, num_movies, ...num_features, 1.5);fprintf(['Cost at loaded parameters (lambda = 1.5): %f '...'\n(this value should be about 31.34)\n'], J);fprintf('\nProgram paused. Press enter to continue.\n');
pause;好,有了这些,再加上Octave中的无约束最小化优化函数,就可以直接训练了(下面是这个优化函数调用的代码):
theta = fmincg (@(t)(cofiCostFunc(t, Y, R, num_users, num_movies, ...num_features, lambda)), ...initial_parameters, options);现在可以看看对于一个用户它的效果了:
这里来了一个用户,且有该用户对几个电影的评分,代码如下:
%% ============== Part 6: Entering ratings for a new user ===============
% Before we will train the collaborative filtering model, we will first
% add ratings that correspond to a new user that we just observed. This
% part of the code will also allow you to put in your own ratings for the
% movies in our dataset!
%
movieList = loadMovieList();% Initialize my ratings
my_ratings = zeros(1682, 1);% Check the file movie_idx.txt for id of each movie in our dataset
% For example, Toy Story (1995) has ID 1, so to rate it "4", you can set
my_ratings(1) = 4;% Or suppose did not enjoy Silence of the Lambs (1991), you can set
my_ratings(98) = 2;% We have selected a few movies we liked / did not like and the ratings we
% gave are as follows:
my_ratings(7) = 3;
my_ratings(12)= 10;
my_ratings(54) = 4;
my_ratings(64)= 10;
my_ratings(66)= 3;
my_ratings(69) = 10;
my_ratings(183) = 4;
my_ratings(226) = 10;
my_ratings(355)= 10;fprintf('\n\nNew user ratings:\n');
for i = 1:length(my_ratings)if my_ratings(i) > 0 fprintf('Rated %d for %s\n', my_ratings(i), ...movieList{i});end
endfprintf('\nProgram paused. Press enter to continue.\n');
pause;其中LoadmovieList()导入了如下的电影(其实是我选了几个,另外几个随便选的)
New user ratings:
Rated 4 for Toy Story (1995)
Rated 3 for Twelve Monkeys (1995)
Rated 10 for Usual Suspects, The (1995)
Rated 4 for Outbreak (1995)
Rated 10 for Shawshank Redemption, The (1994)
Rated 3 for While You Were Sleeping (1995)
Rated 10 for Forrest Gump (1994)
Rated 2 for Silence of the Lambs, The (1991)
Rated 4 for Alien (1979)
Rated 10 for Die Hard 2 (1990)
Rated 10 for Sphere (1998)现在开始训练参数了:
%% ================== Part 7: Learning Movie Ratings ====================
% Now, you will train the collaborative filtering model on a movie rating
% dataset of 1682 movies and 943 users
%fprintf('\nTraining collaborative filtering...\n');% Load data
load('ex8_movies.mat');% Y is a 1682x943 matrix, containing ratings (1-5) of 1682 movies by
% 943 users
%
% R is a 1682x943 matrix, where R(i,j) = 1 if and only if user j gave a
% rating to movie i% Add our own ratings to the data matrix
Y = [my_ratings Y];
R = [(my_ratings ~= 0) R];% Normalize Ratings
[Ynorm, Ymean] = normalizeRatings(Y, R);% Useful Values
num_users = size(Y, 2);
num_movies = size(Y, 1);
num_features = 10;% Set Initial Parameters (Theta, X)
X = randn(num_movies, num_features);
Theta = randn(num_users, num_features);initial_parameters = [X(:); Theta(:)];% Set options for fmincg
options = optimset('GradObj', 'on', 'MaxIter', 100);% Set Regularization
lambda = 10;
theta = fmincg (@(t)(cofiCostFunc(t, Ynorm, R, num_users, num_movies, ...num_features, lambda)), ...initial_parameters, options);% Unfold the returned theta back into U and W
X = reshape(theta(1:num_movies*num_features), num_movies, num_features);
Theta = reshape(theta(num_movies*num_features+1:end), ...num_users, num_features);fprintf('Recommender system learning completed.\n');fprintf('\nProgram paused. Press enter to continue.\n');
pause;然后,开始推荐:
%% ================== Part 8: Recommendation for you ====================
% After training the model, you can now make recommendations by computing
% the predictions matrix.
%p = X * Theta';
my_predictions = p(:,1) + Ymean;movieList = loadMovieList();[r, ix] = sort(my_predictions, 'descend');
fprintf('\nTop recommendations for you:\n');
for i=1:10j = ix(i);fprintf('Predicting rating %.1f for movie %s\n', my_predictions(j), ...movieList{j});
endfprintf('\n\nOriginal ratings provided:\n');
for i = 1:length(my_ratings)if my_ratings(i) > 0 fprintf('Rated %d for %s\n', my_ratings(i), ...movieList{i});end
end
结果推荐了这几部电影:
Top recommendations for you:
Predicting rating 6.5 for movie Forrest Gump (1994)
Predicting rating 6.3 for movie Return of the Jedi (1983)
Predicting rating 6.3 for movie Star Wars (1977)
Predicting rating 6.2 for movie Raiders of the Lost Ark (1981)
Predicting rating 6.1 for movie Shawshank Redemption, The (1994)
Predicting rating 6.1 for movie Empire Strikes Back, The (1980)
Predicting rating 6.0 for movie Braveheart (1995)
Predicting rating 6.0 for movie Titanic (1997)
Predicting rating 5.8 for movie Back to the Future (1985)
Predicting rating 5.8 for movie Game, The (1997)好吧,我也没看过,都是很老的电影。。。我也不知道推荐的准不准。。。
这篇关于octave实现协同过滤推荐算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





